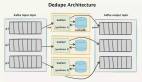
【51CTO.com原创稿件】Apache Kafka 是一款流行的分布式数据流平台,它已经广泛地被诸如 New Relic(数据智能平台)、Uber、Square(移动支付公司)等大型公司用来构建可扩展的、高吞吐量的、且高可靠的实时数据流系统。
例如,在 New Relic 的生产环境中,Kafka 群集每秒能够处理超过 1500 万条消息,而且其数据聚合率接近 1Tbps。
可见,Kafka 大幅简化了对于数据流的处理,因此它也获得了众多应用开发人员和数据管理专家的青睐。
然而,在大型系统中 Kafka 的应用会比较复杂。如果您的 Consumers 无法跟上数据流的话,各种消息往往在未被查看之前就已经消失掉了。
同时,它在自动化数据保留方面的限制,高流量的发布+订阅(publish-subscribe,pub/sub)模式等,可能都会影响到您系统的性能。
可以毫不夸张地说,如果那些存放着数据流的系统无法按需扩容、或稳定性不可靠的话,估计您经常会寝食难安。
为了减少上述复杂性,我在此分享 New Relic 公司为 Kafka 集群在应对高吞吐量方面的 20 项***实践。
我将从如下四个方面进行展开:
- Partitions(分区)
- Consumers(消费者)
- Producers(生产者)
- Brokers(代理)
快速了解 Kafka 的概念与架构
Kafka 是一种高效的分布式消息系统。在性能上,它具有内置的数据冗余度与弹性,也具有高吞吐能力和可扩展性。
在功能上,它支持自动化的数据保存限制,能够以“流”的方式为应用提供数据转换,以及按照“键-值(key-value)”的建模关系“压缩”数据流。
要了解各种***实践,您需要首先熟悉如下关键术语:
Message(消息)
Kafka 中的一条记录或数据单位。每条消息都有一个键和对应的一个值,有时还会有可选的消息头。
Producer(生产者)
Producer 将消息发布到 Kafka 的 topics 上。Producer 决定向 topic 分区的发布方式,如:轮询的随机方法、或基于消息键(key)的分区算法。
Broker(代理)
Kafka 以分布式系统或集群的方式运行。那么群集中的每个节点称为一个 Broker。
Topic(主题)
Topic 是那些被发布的数据记录或消息的一种类别。消费者通过订阅Topic,来读取写给它们的数据。
Topic Partition(主题分区)
不同的 Topic 被分为不同的分区,而每一条消息都会被分配一个 Offset,通常每个分区都会被复制至少一到两次。
每个分区都有一个 Leader 和存放在各个 Follower 上的一到多个副本(即:数据的副本),此法可防止某个 Broker 的失效。
群集中的所有 Broker 都可以作为 Leader 和 Follower,但是一个 Broker 最多只能有一个 Topic Partition 的副本。Leader 可被用来进行所有的读写操作。
Offset(偏移量)
单个分区中的每一条消息都被分配一个 Offset,它是一个单调递增的整型数,可用来作为分区中消息的唯一标识符。
Consumer(消费者)
Consumer 通过订阅 Topic partition,来读取 Kafka 的各种 Topic 消息。然后,消费类应用处理会收到消息,以完成指定的工作。
Consumer group(消费组)
Consumer 可以按照 Consumer group 进行逻辑划分。Topic Partition 被均衡地分配给组中的所有 Consumers。
因此,在同一个 Consumer group 中,所有的 Consumer 都以负载均衡的方式运作。
换言之,同一组中的每一个 Consumer 都能看到每一条消息。如果某个 Consumer 处于“离线”状态的话,那么该分区将会被分配给同组中的另一个 Consumer。这就是所谓的“再均衡(rebalance)”。
当然,如果组中的 Consumer 多于分区数,则某些 Consumer 将会处于闲置的状态。
相反,如果组中的 Consumer 少于分区数,则某些 Consumer 会获得来自一个以上分区的消息。
Lag(延迟)
当 Consumer 的速度跟不上消息的产生速度时,Consumer 就会因为无法从分区中读取消息,而产生延迟。
延迟表示为分区头后面的 Offset 数量。从延迟状态(到“追赶上来”)恢复正常所需要的时间,取决于 Consumer 每秒能够应对的消息速度。
其公式如下:time = messages / (consume rate per second - produce rate per second)
针对 Partitions 的***实践
①了解分区的数据速率,以确保提供合适的数据保存空间
此处所谓“分区的数据速率”是指数据的生成速率。换言之,它是由“平均消息大小”乘以“每秒消息数”得出的数据速率决定了在给定时间内,所能保证的数据保存空间的大小(以字节为单位)。
如果您不知道数据速率的话,则无法正确地计算出满足基于给定时间跨度的数据,所需要保存的空间大小。
同时,数据速率也能够标识出单个 Consumer 在不产生延时的情况下,所需要支持的***性能值。
②除非您有其他架构上的需要,否则在写 Topic 时请使用随机分区
在您进行大型操作时,各个分区在数据速率上的参差不齐是非常难以管理的。
其原因来自于如下三个方面:
- 首先,“热”(有较高吞吐量)分区上的 Consumer 势必会比同组中的其他 Consumer 处理更多的消息,因此很可能会导致出现在处理上和网络上的瓶颈。
- 其次,那些为具有***数据速率的分区,所配置的***保留空间,会导致Topic 中其他分区的磁盘使用量也做相应地增长。
- 第三,根据分区的 Leader 关系所实施的***均衡方案,比简单地将 Leader 关系分散到所有 Broker 上,要更为复杂。在同一 Topic 中,“热”分区会“承载”10 倍于其他分区的权重。
有关 Topic Partition 的使用,可以参阅《Kafka Topic Partition的各种有效策略》https://blog.newrelic.com/engineering/effective-strategies-kafka-topic-partitioning/。
针对 Consumers 的***实践
③如果 Consumers 运行的是比 Kafka 0.10 还要旧的版本,那么请马上升级
在 0.8.x 版中,Consumer 使用 Apache ZooKeeper 来协调 Consumer group,而许多已知的 Bug 会导致其长期处于再均衡状态,或是直接导致再均衡算法的失败(我们称之为“再均衡风暴”)。
因此在再均衡期间,一个或多个分区会被分配给同一组中的每个 Consumer。
而在再均衡风暴中,分区的所有权会持续在各个 Consumers 之间流转,这反而阻碍了任何一个 Consumer 去真正获取分区的所有权。
④调优 Consumer 的套接字缓冲区(socket buffers),以应对数据的高速流入
在 Kafka 的 0.10.x 版本中,参数 receive.buffer.bytes 的默认值为 64KB。而在 Kafka 的 0.8.x 版本中,参数 socket.receive.buffer.bytes 的默认值为 100KB。
这两个默认值对于高吞吐量的环境而言都太小了,特别是如果 Broker 和 Consumer 之间的网络带宽延迟积(bandwidth-delay product)大于局域网(local areanetwork,LAN)时。
对于延迟为 1 毫秒或更多的高带宽的网络(如 10Gbps 或更高),请考虑将套接字缓冲区设置为 8 或 16MB。
如果您的内存不足,也至少考虑设置为 1MB。当然,您也可以设置为 -1,它会让底层操作系统根据网络的实际情况,去调整缓冲区的大小。
但是,对于需要启动“热”分区的 Consumers 来说,自动调整可能不会那么快。
⑤设计具有高吞吐量的 Consumers,以便按需实施背压(back-pressure)
通常,我们应该保证系统只去处理其能力范围内的数据,而不要超负荷“消费”,进而导致进程中断“挂起”,或出现 Consume group 的溢出。
如果是在 Java 虚拟机(JVM)中运行,Consumers 应当使用固定大小的缓冲区,而且***是使用堆外内存(off-heap)。请参见 Disruptor 模式:http://lmax-exchange.github.io/disruptor/files/Disruptor-1.0.pdf
固定大小的缓冲区能够阻止 Consumer 将过多的数据拉到堆栈上,以至于 JVM 花费掉其所有的时间去执行垃圾回收,进而无法履行其处理消息的本质工作。
⑥在 JVM 上运行各种 Consumers 时,请警惕垃圾回收对它们可能产生的影响
例如,长时间垃圾回收的停滞,可能导致 ZooKeeper 的会话被丢弃、或 Consumer group 处于再均衡状态。
对于 Broker 来说也如此,如果垃圾回收停滞的时间太长,则会产生集群掉线的风险。
针对 Producers 的***实践
⑦配置 Producer,以等待各种确认
籍此 Producer 能够获知消息是否真正被发送到了 Broker 的分区上。在 Kafka 的 0.10.x 版本上,其设置是 Acks;而在 0.8.x 版本上,则为 request.required.acks。
Kafka 通过复制,来提供容错功能,因此单个节点的故障、或分区 Leader 关系的更改不会影响到系统的可用性。
如果您没有用 Acks 来配置 Producer(或称“fireand forget”)的话,则消息可能会悄然丢失。
⑧为各个 Producer 配置 Retries
其默认值为 3,当然是非常低的。不过,正确的设定值取决于您的应用程序,即:就那些对于数据丢失零容忍的应用而言,请考虑设置为 Integer.MAX_VALUE(有效且***)。
这样将能够应对 Broker 的 Leader 分区出现无法立刻响应 Produce 请求的情况。
⑨为高吞吐量的 Producer,调优缓冲区的大小
特别是 buffer.memory 和 batch.size(以字节为单位)。由于 batch.size 是按照分区设定的,而 Producer 的性能和内存的使用量,都可以与 Topic 中的分区数量相关联。
因此,此处的设定值将取决于如下几个因素:
- Producer 数据速率(消息的大小和数量)
- 要生成的分区数
- 可用的内存量
请记住,将缓冲区调大并不总是好事,如果 Producer 由于某种原因而失效了(例如,某个 Leader 的响应速度比确认还要慢),那么在堆内内存(on-heap)中的缓冲的数据量越多,其需要回收的垃圾也就越多。
⑩检测应用程序,以跟踪诸如生成的消息数、平均消息大小、以及已使用的消息数等指标
针对 Brokers 的***实践
⑪在各个 Brokers 上,请压缩 Topics 所需的内存和 CPU 资源。
日志压缩(请参见https://kafka.apache.org/documentation/#compaction)需要各个 Broker 上的堆栈(内存)和 CPU 周期都能成功地配合实现而如果让那些失败的日志压缩数据持续增长的话,则会给 Brokers 分区带来风险。
您可以在 Broker 上调整 log.cleaner.dedupe.buffer.size 和 log.cleaner.threads 这两个参数,但是请记住,这两个值都会影响到各个 Brokers 上的堆栈使用。
如果某个 Broker 抛出 OutOfMemoryError 异常,那么它将会被关闭、并可能造成数据的丢失。
而缓冲区的大小和线程的计数,则取决于需要被清除的 Topic Partition 数量、以及这些分区中消息的数据速率与密钥的大小。
对于 Kafka 的 0.10.2.1 版本而言,通过 ERROR 条目来监控日志清理程序的日志文件,是检测其线程可能出现问题的最可靠方法。
⑫通过网络吞吐量来监控 Brokers
请监控发向(transmit,TX)和收向(receive,RX)的流量,以及磁盘的 I/O、磁盘的空间、以及 CPU 的使用率,而且容量规划是维护群集整体性能的关键步骤。
⑬在群集的各个 Brokers 之间分配分区的 Leader 关系
Leader 通常会需要大量的网络 I/O 资源。例如,当我们将复制因子(replication factor)配置为 3、并运行起来时。
Leader 必须首先获取分区的数据,然后将两套副本发送给另两个 Followers,进而再传输到多个需要该数据的 Consumers 上。
因此在该例子中,单个 Leader 所使用的网络 I/O,至少是 Follower 的四倍。而且,Leader 还可能需要对磁盘进行读操作,而 Follower 只需进行写操作。
⑭不要忽略监控 Brokers 的 in-sync replica(ISR)shrinks、under-replicatedpartitions 和 unpreferred leaders
这些都是集群中潜在问题的迹象。例如,单个分区频繁出现 ISR 收缩,则暗示着该分区的数据速率超过了 Leader 的能力,已无法为 Consumer 和其他副本线程提供服务了。
⑮按需修改 Apache Log4j 的各种属性
详细内容可以参考:https://github.com/apache/kafka/blob/trunk/config/log4j.properties
Kafka 的 Broker 日志记录会耗费大量的磁盘空间,但是我们却不能完全关闭它。
因为有时在发生事故之后,需要重建事件序列,那么 Broker 日志就会是我们***的、甚至是唯一的方法。
⑯禁用 Topic 的自动创建,或针对那些未被使用的 Topics 建立清除策略
例如,在设定的 x 天内,如果未出现新的消息,您应该考虑该 Topic 是否已经失效,并将其从群集中予以删除。此举可避免您花时间去管理群集中被额外创建的元数据。
⑰对于那些具有持续高吞吐量的 Brokers,请提供足够的内存,以避免它们从磁盘子系统中进行读操作
我们应尽可能地直接从操作系统的缓存中直接获取分区的数据。然而,这就意味着您必须确保自己的 Consumers 能够跟得上“节奏”,而对于那些延迟的 Consumer 就只能强制 Broker 从磁盘中读取了。
⑱对于具有高吞吐量服务级别目标(service level objectives,SLOs)的大型群集,请考虑为 Brokers 的子集隔离出不同的 Topic
至于如何确定需要隔离的 Topics,则完全取决于您自己的业务需要。例如,您有一些使用相同群集的联机事务处理(multipleonline transaction processing,OLTP)系统。
那么将每个系统的 Topics 隔离到不同 Brokers 子集中,则能够有助于限制潜在事件的影响半径。
⑲在旧的客户端上使用新的 Topic 消息格式。应当代替客户端,在各个 Brokers 上加载额外的格式转换服务
当然,***还是要尽量避免这种情况的发生。
⑳不要错误地认为在本地主机上测试好 Broker,就能代表生产环境中的真实性能了
要知道,如果使用复制因子为 1,并在环回接口上对分区所做的测试,是与大多数生产环境截然不同的。
在环回接口上网络延迟几乎可以被忽略的,而在不涉及到复制的情况下,接收 Leader 确认所需的时间则同样会出现巨大的差异。
总结
希望上述各项建议能够有助于您更有效地去使用 Kafka。如果您想提高自己在 Kafka 方面的专业知识,请进一步查阅 Kafka 配套文档中的“操作”部分,其中包含了有关操作群集等实用信息。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】