一、前言
数学大师陈省身有一句话是这样说的:了解历史的变化是了解这门学科的一个步骤。今天,我把这句话应用到一个具体的Linux模块:了解逆向映射的最好的方法是了解它的历史。本文介绍了Linux内核中的逆向映射机制如何从无到有,如何从笨重到轻盈的历史过程,通过这些历史的演进过程,希望能对逆向映射有更加深入的理解。
二、基础知识
在切入逆向映射的历史之前,我们还是简单看看一些基础的概念,这主要包括两个方面:一个是逆向映射的定义,另外一个是引入逆向映射的原因。
1、什么是逆向映射(reverse mapping)?
在聊逆向映射之前,我们先聊聊正向映射好了,当你明白了正向映射,逆向映射的概念也就易如反掌了。所谓正向映射,就是在已知虚拟地址和物理地址(或者page number、page struct)的情况下,为地址映射建立起完整的页表的过程。例如,进程分配了一段VMA之后,并无对应的page frame(即没有分配物理地址),直到程序访问了这段VMA之后,产生异常,由内核为其分配物理页面并建立起所有的各级的translation table。通过正向映射,我们可以将进程虚拟地址空间中的虚拟页面映射到对应的物理页面(page frame)。
逆向映射相反,在已知page frame的情况下(可能是PFN、可能是指向page descriptor的指针,也可能是物理地址,内核有各种宏定义用于在它们之间进行转换),找到映射到该物理页面的虚拟页面们。由于一个page frame可以在多个进程之间共享,因此逆向映射的任务是把分散在各个进程地址空间中的所有的page table entry全部找出来。
一般来说,一个进程的地址空间内不会把两个虚拟地址mapping到一个page frame上去,如果有多个mapping,那么多半是这个page被多个进程共享。最简单的例子就是采用COW的进程fork,在进程没有写的动作之前,内核是不会分配新的page frame的,因此父子进程共享一个物理页面。还有一个例子和c lib相关,由于c lib是基础库,它会file mapping到很多进程地址空间中,那么c lib中的程序正文段对应的page frame应该会有非常多的page table entries与之对应。
2、为何需要逆向映射?
之所以建立逆向映射机制主要是为了方便页面回收。当页面回收机制启动之后,如果回收的page frame是位于内核中的各种内存cache中(例如 slab内存分配器),那么这些页面其实是可以直接回收,没有相关的页表操作。如果回收的是用户进程空间的page frame,那么在回收之前,内核需要对该page frame进行unmapping的操作,即找到所有的page table entries,然后进行对应的修改操作。当然,如果页面是dirty的,我们还需要一些必要的磁盘IO操作。
可以给出一个实际的例子,例如swapping机制,在释放一个匿名映射页面的时候,要求对所有相关的页表项进行更改,将swap area和page slot index写入页表项中。只有在所有指向该page frame的页表项修改完毕后才可以将该页交换到磁盘,并且回收这个page frame。demand paging的场景是类似的,只不过是需要把所有的page table entry清零,这里就不赘述了。
三、史前文明
盘古开天辟地之前,宇宙混沌一片。对于逆向映射这个场景,我们的问题就是:没有逆向映射之前,混沌的内核世界是怎样的呢?这一章主要是回答这个问题的,分析的基础是2.4.18内核的源代码。
1、没有逆向映射,系统如何运作?
也许年轻的内核工程师很难想象没有逆向映射的内核世界,但实际上2.4时期的内核就是这样的。让我们想象一下,我们自己就是page reclaim机制的维护者,看看我们目前的困境:如果没有逆向映射机制,那么struct page中没有维护任何的逆向映射的数据。这种情况下,内核不可能通过简单的方法来找到page frame所对应的那些PTEs。当回收一个被多个进程共享的page frame,我们该怎么办呢?
本身回收用户进程的物理页帧并不复杂,这需要memory mapping和swapping机制的支持。这两种机制的工作原理类似,只不过一个用于file mapped page,另外一个用于anonymous page。不过对于页面回收而言,他们的工作原理类似:就是把某些进程不常使用的page frame交换到磁盘上去,同时解除进程和这个page frame的一切关系,完成这两步之后,这个物理页帧已经自由了,可以回收到伙伴系统中。
OK,了解了基本原理,现在需要看看如何具体实现:不常使用的page frame很好找(inactive lru链表),不过断绝page frame和进程们之间的关系很难,因为没有逆向映射。不过这难不倒Linux内核开发人员,他们选择了扫描整个系统的各个进程的地址空间的方法。
2、如何对进程地址空间进行扫描?
下图是一个对进程地址空间进行扫描的示意图:
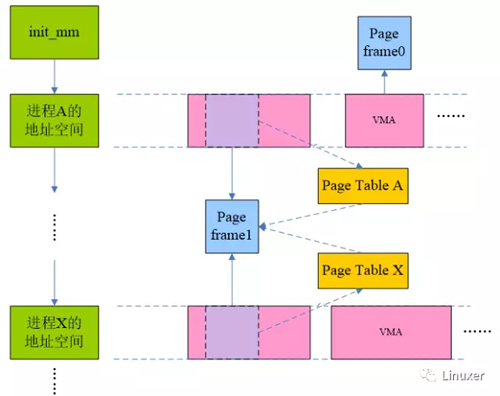
系统中的所有进程地址空间(memory descriptor)被串成一个链表,链表头就是init_mm,系统中所有的进程地址空间都挂在了这个链表中。所谓scan当然就是沿着这条mm链表进行了。当然,页面回收算法尽量不scan整个系统的全部进程地址空间,毕竟那是一个比较笨的办法。回收算法可以考虑收缩内存cache,也可以遍历inactive_list来试图完成本次reclaim数目的要求(该链表中有些page不和任何进程相关),如果通过这些方法释放了足够多的page frame,那么一切都搞定了,不需要scan进程地址空间。当然,情况并非总是那么美好,有时候,必须启动进程物理页面回收过程才能满足页面回收的要求。
进程物理页面回收过程是通过调用swap_out函数完成的,而scan进程地址空间的代码也是开始于这个函数。该函数是一个三层嵌套结构:
(1) 首先沿着init_mm,对每一个进程地址空间进行扫描
(2) 在扫描一个进程地址空间的时候,对属于该进程地址空间的每一个VMA进行扫描
(3) 在扫描每一个VMA的时候,对属于该VMA的每一个page进行扫描
在扫描过程中,如果命中了进程A的page frame0,由于该page只是被进程A 使用(即只是被A进程mapping),那么可直接unmap并回收该page。对于共享页面,我们不能这么处理了,例如上图中的page frame 1,但scan A进程的时候,如果条件符合,那么我们会unmap该page,解除它和进程A的关系,当然,这时候不能回收该page,因为进程X还在使用该page。直到scan过程历经千山万水来到进程X,完成对page frame 1的unmaping操作,该物理页面才可以真正会伙伴系统的怀抱。
3、地址空间扫描的细节问题
首先,第一个问题:到底scan多少虚拟地址空间才停止scan呢?当目标已经达到的时候,例如本次scan打算reclaim 32个page frame,如果目标达到,那么scan停止,不需scan全部虚拟地址空间。还有一种比较悲惨的情况,那就是scan了系统中所有的地址空间之后,仍然没有达成目标,这时候也就可以停止了,不过这属于OOM的处理了。为了确保系统中的进程被均匀的scan(毕竟swap out会影响进程性能,我们肯定不能只逮住部分进程薅其羊毛),每次scan完成后,记录当前scan的位置(保存在swap_mm变量),等下次又启动scan过程的时候,从swap_mm开始继续scan。
由于对性能有影响,swap out需要雨露均沾,各个进程都跑不掉。同样的道理,对于一个进程的地址空间,我们一样也是需要公平对待,因此需要保存每次scan的虚拟地址(mm->swap_address),这样,每次重启scan的时候,总是从swap_mm那个地址空间的mm->swap_address虚拟地址开始scan。
具体对一个page frame进行swap out的代码位于try_to_swap_out函数中,在这个函数中,如果条件满足,会解除该page frame的该进程之间的关系,完成必要的IO操作,该page reference count减一,对应的pte清零或者设定swap entry等。当然,swap out一个page之后,我们并非一定能够回收它,因为这个page很可能被多个进程共享。而在scan过程中,如果碰巧找到了该page对应的所有的页面表条目,那么说明该页面已经不被任何进程引用,这时候该page frame就会被逐出磁盘,从而完成一个页面的回收。
四、开天辟地
时间又回到2002年1月,那时VM大神Rik van Riel遭遇了人生中的一次重大挫折,他的耗费心血维护的代码被一个全新的VM子系统取代了。不过Rik van Riel并没有消沉下去,他在憋大招,也就是传说中的reverse mapping(后文简称rmap)。本章主要描述第一个版本的rmap,代码来自Linux 2.6.0。
1、设计概念
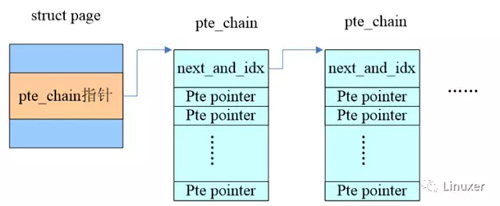
如何构建rmap?最直观的想法就是针对每一个page frame,我们维护一个链表,保存属于该page的所有PTEs。因此,Rik van Riel给struct page增加了一个pte chain的成员,以便把所有mapping到该page的pte entry指针给串起来。这样想要unmap一个page就易如反掌了,沿着这个pte chain就可以找到所有的mappings。一个基本的示意图如下,下面的小节会给出更详细的解释。
2、对Struct page的修改
Struct page的修改如下:
- struct page {
- ……
- union {
- struct pte_chain *chain;
- pte_addr_t direct;
- } pte;
- ……
当然,很多页面都不是共享的,只有一个pte entry,因此direct直接指向那个pte entry就OK了。如果存在页面共享的情况,那么chain成员则会指向一个struct pte_chain的链表。
3、定义struct pte_chain
- struct pte_chain {
- unsigned long next_and_idx;
- pte_addr_t ptes[NRPTE];
- } ____cacheline_aligned;
如果pte_chain只保存一个pte entry的指针那么就太浪费了,比较好的方法是把struct pte_chain对齐在cache line并让整个struct pte_chain占用一个cache line。除了next_and_idx用于指向下一个pte_chain,形成链表之外,其余的空间都用于保存pte entry指针。由于pte entry指针形成了数组,因此我们还需要一个index指示下一个空闲的pte entry pointer的位置,由于pte_chain对齐在cache line,因此next_and_idx的LSB的若干个bit是等于0的,可以复用做index。
4、页面回收算法的修改
在进入基于rmap的页面回收算法之前,让我们先回忆一下痛苦的过去。假设一个物理页面P被A和B两个进程共享,在过去,释放P这个物理页面需要扫描进程地址空间,首先scan到A进程,解除P和A进程的关系,但是这时候不能回收,B进程还在使用该page frame。当然扫描过程最终会来到B进程,只有在这时候才有机会回收这个物理页面P。你可能会问:如果scan B进程地址空间的时候,A进程又访问了P从而导致映射建立。然后scan A的时候,B进程又再次访问,如此反反复复,那么P不就永远无法回收了吗?这个怎么办呢?这个……理论上是这样的,别问我,其实我也很绝望。
有了rmap,页面回收算法顿时感觉轻松多了,只要是页面回收算法看中的page frame,总是能够通过try_to_unmap解除和所有进程的关联,从而将其回收到伙伴系统中。如果该page frame没有共享(page flag设定PG_direct flag),那么page->pte.direct直接命中pte entry,调用try_to_unmap_one来进行unmap的操作。如果映射到了多个虚拟地址空间,那么沿着pte_chain依次调用try_to_unmap_one来进行unmap的操作。
五、女娲补天
虽然Rik van Riel开辟了逆向映射的新天地,但是,天和地都有着巨大的窟窿,需要有人修补。首先让我们看看这个“巨大的窟窿”是什么?
在引入第一个版本的rmap之后,Linux的页面回收变得简单、可控了,但是这个简单的设计是有代价的:每一个struct page增加一个指针成员,在32bit的系统上也就是增加了4B。考虑到系统为了管理内存会为每一个page frame建立一个struct page对象,引入rmap而导致的内存开销也不是一个小数目啊。此外,share page需要建立pte_chain链表,也是一个不小的内存开销。除了内存方面的压力,第一个版本的rmap对性能也造成了一定的影响。例如:在fork操作的时候,父子进程共享了很多的page frame,这样,在copy page table的时候就会伴随大量的pte_chain的操作,从而让fork的速度变得缓慢。
本章就是带领大家看看object-based reverse mapping(后文简称objrmap)是如何填补那个“巨大的窟窿”。本章的代码来自2.6.11版本的内核。
1、问题的引入
推动rmap优化的动力来自内存方面的压力,与此相关的问题是:32-bit的Linux内核是否支持4G以上的memory。在1999年,Linus的决定是:32-bit的Linux内核永远也不会支持2G以上的内存。不过历史的洪流不可阻挡,处理器厂商设计了扩展模块以便寻址更多的内存,高端的服务器也配置了越来越多的内存。这也迫使Linus改变之前的思路,让Linux内核支持更大的内存。
红帽公司的Andrea Arcangeli当时正在做的工作就是让32-bit的Linux运行在配置超过32G内存的公司服务器上。在这些服务器上往往启动大量的进程,共享了大量的物理页帧,消耗了大量的内存。对于Andrea Arcangeli来说,内存消耗的真正元凶是明确的:逆向映射模块,这个模块消耗了太多的low memory,从而导致了系统的各种crash。为了让自己的工作继续推进,他必须解决rmap引入的内存扩展性(memory scalability)问题。
2、file mapped的优化
并非只有Andrea Arcangeli关注到了rmap的内存问题,在2.5版本的开发过程中,IBM公司的Dave McCracken就已经提交了patch,试图在保证逆向映射功能的基础上,同时又能修正rmap带来的各种问题。
Dave McCracken的方案是一种基于对象的逆向映射机制。在过去,通过rmap,我们可以从struct page直接获取其对应的ptes,objrmap的方法借助其他的数据对象来完成从struct page检索到其对应ptes的过程,这个过程的示意图如下:
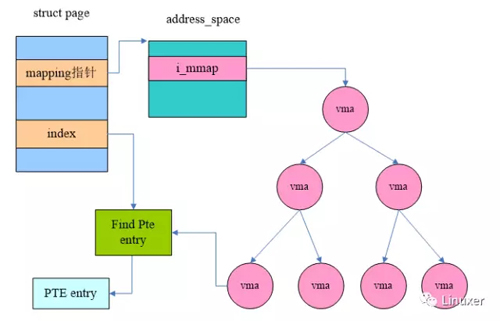
对于objrmap而言,寻找一个page frame的mappings是一个比较长的路径,它借助了VMA(struct vm_area_struct)这个数据对象。我们知道对于某些page frame是有后备文件的,这种类型的页面和某个文件相关,例如进程的正文段和该进程的可执行文件相关。此外,进程可以调用mmap()对某个文件进行mapping。对于这些页帧我们称之file mapped page。
对于这些文件映射页面,其struct page中有一个成员mapping指向一个struct address_space,address_space是和文件相关的,它保存了文件page cache相关的信息。当然,我们这个场景主要关注一个叫做i_mmap的成员。一个文件可能会被映射到多个进程的多个VMA中,所有的这些VMA都被挂入到i_mmap指向的Priority search tree中。
当然,我们最终的目标是PTEs,下面这幅图展示了如何从VMA和struct page中的信息导出该page frame的虚拟地址的:
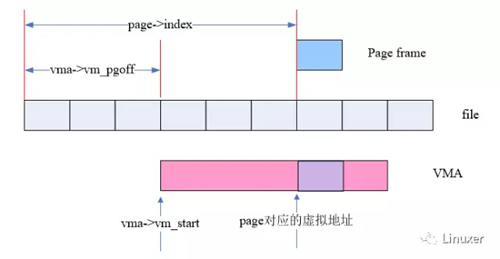
而在linux kernel中,函数vma_address可以完成这个功能:
- static inline unsigned long
- vma_address(struct page *page, struct vm_area_struct *vma)
- {
- pgoff_t pgoff = page->index << (PAGE_CACHE_SHIFT - PAGE_SHIFT);
- unsigned long address;
- address = vma->vm_start + ((pgoff - vma->vm_pgoff) << PAGE_SHIFT);
- return address;
- }
对于file mapped page,page->index表示的是映射到文件内的偏移(Byte为单位),而vma->vm_pgoff表示的是该VMA映射到文件内的偏移(page为单位),因此,通过vma->vm_pgoff和page->index可以得到该page frame在VMA中的地址偏移,再加上vma->vm_start就可以得到该page frame的虚拟地址。有了虚拟地址和地址空间(vma->vm_mm),我们就可以通过各级页表找到该page对应的pte entry。
3、匿名页面的优化
我们都知道,用户空间进程的页面主要有两种,一种是file mapped page,另外一种是anonymous mapped page。Dave McCracken的objrmap方案虽好,但是只是适用于file mapped page,对于匿名映射页面,这个方案无能为力。因此,我们必须为匿名映射页面也设计一种基于对象的逆向映射机制,最后形成full objrmap方案。
为了解决内存扩展性的问题,Andrea Arcangeli全力工作在full objrmap方案上,不过他还有一个竞争对手,Hugh Dickins,同时也提交了一系列full objrmap补丁,试图并入内核主线,显然,在匿名映射页面上,最后胜出的是Andrea Arcangeli,他的匿名映射方案如下图所示:
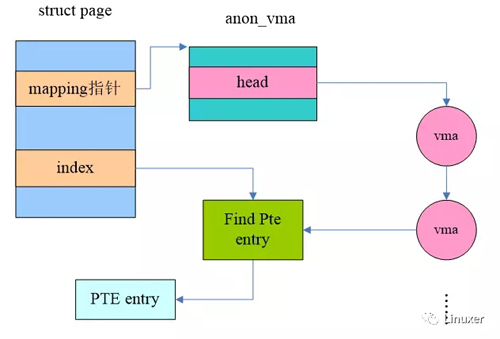
和file mapped类似,anonymous page也是通过VMA来寻找page frame对应的pte entry。由于文件映射页面的VMA数量可能非常大,因此我们采用Priority search tree这样的数据结构。对于匿名映射页面,其数量一般不会太大,所以使用链表结构就OK了。
为了节省内存,我们复用了struct page中的mapping指针:一个page frame如果是file mapped,其mapping指针指向对应文件的address_space数据结构。如果是anonymous page,那么mapping指针指向anon_vma数据结构。虽然节省了内存,但是降低了可读性,但是由于内核会为每一个page frame建立一个对应的struct page数据对象,该数据结构即便是增加4B对整个系统的内存消耗都是巨大的,因此内核还是采用了较为丑陋的方式来定义mapping这个成员。通过struct page中的mapping成员我们可以获得该page映射相关的信息,总结如下:
(1) 等于NULL,表示该page frame不再内存中,而是被swap out到磁盘去了。
(2) 如果不等于NULL,并且least signification bit等于1,表示该page frame是匿名映射页面,mapping指向了一个anon_vma的数据结构。
(3) 如果不等于NULL,并且least signification bit等于0,表示该page frame是文件映射页面,mapping指向了一个该文件的address_space数据结构。
通过anon_vma数据结构,我们可以得到映射到该page的所有的VMA,至此,匿名映射和file mapped汇合,进一步解决的问题仅仅是如何从VMA到pte entry而已。上一节,我们描述了vma_address函数如何获取file mapped page的虚拟地址,其实anonymous page的逻辑是一样的,只不过vma->vm_pgoff和page->index的基础点不一样了,对于file mapped的场景,这个基础点是文件起始位置。对于匿名映射,起始点有两种情况,一种是share anonymous mapping,起点位置是0。另外一种是private anonymous mapping,起点位置是mapping的虚拟地址(除以page size)。但是不管如何,从VMA和struct page得到对应虚拟地址的算法概念是类似的。
六、卷土重来
full objrmap进入内核之后,看起来一切都很完美了,比起她的前任,Rik van Riel的rmap方案,objrmap各方面的指标都是全面碾压rmap。首次将逆向映射引入内核的大神Rik van Riel遭受了第二次的打击,不过他依然斗志昂扬并试图东山再起。
Objrmap虽然完美,不过晴朗的天空中飘着一朵乌云。大神Rik van Riel敏锐的看到了逆向映射的那朵“乌云“,提出了自己的解决方案。本章主要描述新的anon_vma机制,代码来自4.4.6内核。
1、旧anon_vma机制有什么问题?
我们先一起来看看旧anon_vma机制下,系统是如何运作的。VMA_P是父进程的一个匿名映射的VMA,A和C都已经分配了page frame,而其他的page都还都没有分配物理页面。在fork之后,子进程copy了VMA_P,当然由于采用了COW技术,这时候父子进程的匿名页面会共享,同时在父子进程地址空间对应的pte entry中标注write protect的标记,如下图所示:
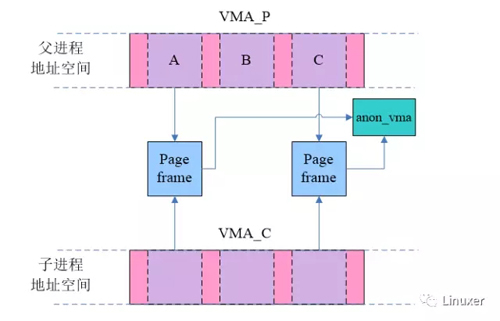
按理说不同进程的匿名页面(例如stack、heap)是私有的,不会共享,但是为了节省内存,在父进程fork子进程之后,父子进程对该页面执行写操作之前,父子进程的匿名页是共享的,所以这些page frame指向同一个anon_vma。当然,共享只是短暂的,一旦有write操作就会产生异常,并在异常处理中分配page frame,解除父子进程匿名页面的共享,具体如下图的page A所示:
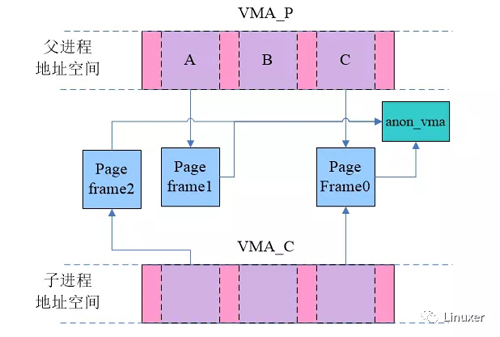
这时候由于写操作,父子进程原本共享的page frame已经不再共享,然而,这两个page却仍然指向同一个anon_vma,不仅如此,对于B这样的页面,一开始就没有在父子进程之间共享,当首次访问的时候(无论是父进程还是子进程),通过do_anonymous_page函数分配的page frame也是同样的指向一个anon_vma。也就是说,父子进程的VMA共享一个anon_vma。
在这种情况下,我们看看unmap page frame1会发生什么。毫无疑问,page frame1对应的struct page的mapping成员指向了上图中的anon_vma,遍历anon_vma会命VMA_P和VMA_C,这里面,VMA_C是无效的VMA,本来就不应该匹配到。如果anon_vma的链表没有那么长,那么整体性能也OK。然而,在有些网路服务器中,系统非常依赖fork,某个服务程序可能会fork巨大数量的子进程来处理服务请求,在这种情况下,系统性能严重下降。Rik van Riel给出了一个具体的示例:系统中有1000进程,都是通过fork生成的,每个进程的VMA有 1000个匿名页。根据目前的软件架构,anon_vma链表中会有1000个vma 的节点,而系统中有一百万个匿名页面属于同一个anon_vma。
这样的系统会导致什么样的问题呢?我们一起来看看try_to_unmap_anon函数,其代码框架如下:
- static int try_to_unmap_anon(struct page *page)
- {……
- anon_vma = page_lock_anon_vma(page);
- list_for_each_entry(vma, &anon_vma->head, anon_vma_node) {
- ret = try_to_unmap_one(page, vma);
- }
- spin_unlock(&anon_vma->lock);
- return ret;
- }
当系统中的一个CPU在执行try_to_unmap_anon函数的时候,需要遍历VMA链表,这时会持有anon_vma->lock这个自旋锁。由于anon_vma存有了很多根本无关的VMA,通过,page table的检索过程,你就会发现这个VMA根本和准备unmap的page无关,因此只能scan下一个VMA,整个过程需要消耗大量的时间,延长了临界区(复杂度是O(N))。与此同时,其他CPU在试获取这把锁的时候,基本会被卡住,这时候整个系统的性能可想而知了。更加糟糕的是内核中并非只有unmap匿名页面的时候会上锁、遍历VMA链表,还有一些其他的场景也会这样(例如page_referenced函数)。想象一下,一百万个页面共享这一个anon_vma,对anon_vma->lock自旋锁的竞争那是相当的激烈啊。
2、改进的方案
旧的方案的症结所在是anon_vma承载了太多进程的VMA了,如果能将其变成per-process的,那么问题就解决了。Rik van Riel的解决办法是为每一个进程创建一个anon_vma结构并通过各种数据结构把父子进程的anon_vma(后面简称AV)以及VMA链接在一起。为了链接anon_vma,内核引入了一个新的结构,称为anon_vma_chain(后面简称AVC):
- struct anon_vma_chain {
- struct vm_area_struct *vma;――指向该AVC对应的VMA
- struct anon_vma *anon_vma;――指向该AVC对应的AV
- struct list_head same_vma; ――链接入VMA链表的节点
- struct rb_node rb;―――链接入AV红黑树的节点
- unsigned long rb_subtree_last;
- };
AVC是一个神奇的结构,每个AVC都有其对应的VMA和AV。所有指向相同VMA的AVC会被链接到一个链表中,链表头就是VMA的anon_vma_chain成员。而一个AV会管理若干的VMA,所有相关的VMA(其子进程或者孙进程)都挂入红黑树,根节点就是AV的rb_root成员。
这样的描述非常枯燥,估计第一次接触逆向映射的同学是不会明白的,不如我们一起来看看AV、AVC和VMA的“大厦”是如何搭建起来的。
3、当VMA和VA首次相遇
由于采用了COW技术,子进程和父进程的匿名页面往往是共享的,直到其中之一发起写操作。但是如果子进程执行了exec的系统调用,加载了自己的二进制image,这时候,子进程和父进程的执行环境(包括匿名页面)就分道扬镳了(参考flush_old_exec函数),我们的场景就是从这么一个全新的exec后的进程开始。当该进程的匿名映射VMA通过page fault分配第一个page frame的时候,内核会构建下图所示的数据关系:
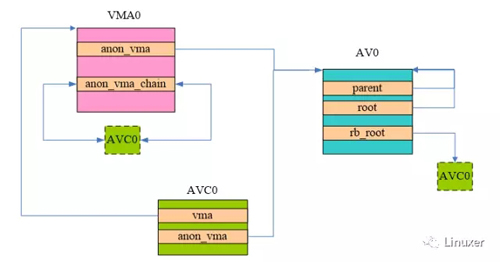
上图中的AV0就是该进程的anon_vma,由于它是一个顶级结构,因此它的root和parent都是指向了自己。AV这个数据结构当然为了管理VMA了,不过新机制中,这是通过AVC进行中转的。上图中的AVC0搭建了该进程VMA和AV之间的桥梁,分别有指针指向了VMA0和AV0,此外,AVC0插入到AV的红黑树,同时也会插入到VMA的链表中。
对于这个新分配的page frame而言,它会mapping到VMA对应的某个虚拟地址上去,为了维护逆向映射的关系,struct page中的mapping指向了AV0,index成员指向了该page在整个VMA0中的偏移。图中没有画出这个关系,主要因为这是老生常谈了,相信大家都已经熟悉。
VMA0中随后可能会有若干的page frame被mapping到该VMA的某个虚拟页面,不过上面的结构不会变化,只不过每一个page中的mapping都指向了上图中的AV0。另外,上图中那个虚线绿色block的AVC0其实等于那个绿色实线的AVC0 block,也就是说这时候该VMA只有一个anon_vma_chain,即AVC0,上图只是方便表示该AVC也会被挂入VMA的链表,挂入anon_vma的红黑树而已。
如果想参考相关的代码可以仔细看看do_anonymous_page或者do_cow_fault。
4、在fork的时候,匿名映射的VMA经历了什么?
一旦fork,那么子进程会copy父进程的VMA(参考函数dup_mmap),子进程会有自己的VMA,同时也会分配自己的AV(旧的机制下,多个进程共享一个AV,而新的机制中,AV是per process的),然后建立父子进程之间的VMA、VA的“大厦”,主要的步骤如下:
(1) 调用anon_vma_clone函数,建立子进程VMA和“父进程们”VA的关系
(2) 建立子进程VMA和子进程VA的关系
怎样叫做建立VMA和VA的关系?其实就是anon_vma_chain_link函数的调用过程,步骤如下:
(1) 分配一个AVC结构,成员指针指向对应的VMA和VA
(2) 将该AVC加入VMA链表
(3) 将该AVC加入VA红黑树
我们一开始先别把事情搞得太复杂,先看看一个全新进程fork子进程的场景。这时候,内核会构建下图所示的数据关系:
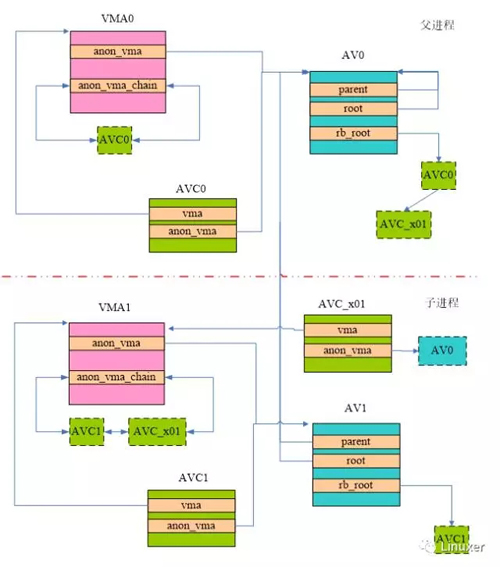
首先看看如何建立子进程VMA1和父进程AV0的关系,这里需要遍历VMA0的anon_vma_chain链表,当然现在这个链表只有一个AVC0(link到AV0),为了建立和父进程的联系,我们分配了AVC_x01,它是一个桥梁,连接了父子进程。(注:AVC_x01中的x表示连接,01表示连接level 0和level 1)。通过这个桥梁,父进程可以找到子进程的VMA(因为AVC_x01插入AV0的红黑树中),而子进程也可以找到父进程的AV(因为AVC_x01插入VMA1的链表中)。
当然,自己的anon_vma也需要创建。在上图中,AV1就是子进程的anon_vma,同时分配一个AVC1来连接该子进程的VMA1和AV1,并调用anon_vma_chain_link函数将AVC1插入VMA1的链表和AV1的红黑树中。
父进程也会创建其他新的子进程,新创建的子进程的层次和VMA1、VA1的类似,这里就不描述了。不过需要注意的是:父进程每创建一个子进程,AV0的红黑树中会增加每一个起“桥梁”作用的AVC,以此连接到子进程的VMA。
5、构建三层大厦
上一节描述了父进程创建子进程的情况,如果子进程再次fork,那么整个VMA-VA的大厦将形成三层结构,具体如下图所示:
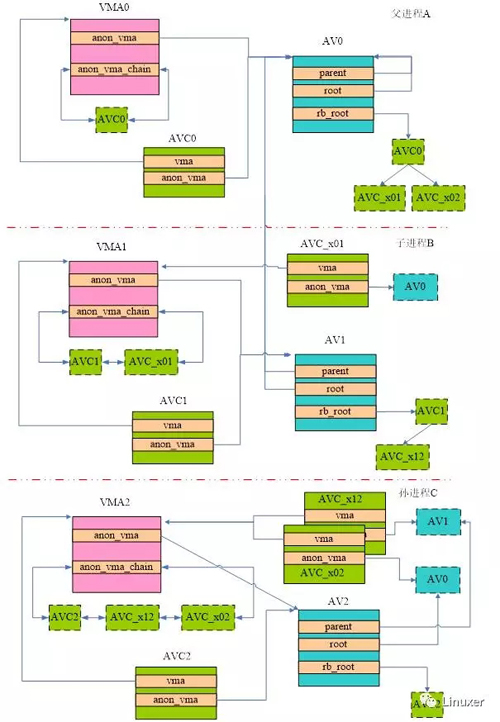
当然,首先要进行的仍然是建立孙进程VMA和“父进程们”VA的关系,这里的“父进程们”其实是泛指孙进程的上层的那些进程们。对于这个场景,“父进程们”指的就是上图中的A进程和B进程。如何建立?在fork的时候,我们进行VMA的拷贝:即分配VMA2并以VMA1为原型copy到VMA2中。Copy是沿着VMA1的AVC链表进行的,该链表有两个元素:AVC1和 AVC_x01,分别和父进程A和子进程B的AV关联。因此,在孙进程C中,我们会分配AVC_x02和AVC_x12两个AVC,并建立level 2层和level 0层以及level 1层之间的关系。
同样的,自己level的anon_vma也需要创建。在上图中,AV2就是孙进程C的anon_vma,同时分配一个AVC2来连接该孙进程的VMA2和AV2,并调用anon_vma_chain_link函数将AVC2插入VMA2的链表和AV2的红黑树中。
AV2中的root指向root AV,也就是进程A的AV。Parent成员指向其B进程(C的父进程)的AV。通过Parent这样的指针,不同level的AV建立了父子关系,而通过root指针,每一个level的AV都可以寻找找到root AV。
6、page frame是如何加入“大厦”中?
前面几个小节重点讨论了hierarchy AV的结构是如何搭建起来的,也就是描述fork的过程中,父子进程的VMA、AVC和AV是如何联系的。本小节我们将一起来看看父子进程之一访问页面,发生了page fault的处理过程。这个处理过程有两个场景,一个是父子进程都没有page frame,这时候,内核代码会调用do_anonymous_page分配page frame并调用page_add_new_anon_rmap函数建立该page和对应VMA的关系。第二个场景复杂一点,是父子共享匿名页面的场景,当发生write fault的时候,也是分配page frame并调用page_add_new_anon_rmap函数建立该page和对应VMA的关系,具体代码位于do_wp_page函数。无论哪一个场景,最终都是将该page的mapping成员指向了该进程所属的AV结构。
7、为何建立如此复杂的“大厦”?
如果你能坚持读到这里,那么说明你对枯燥文字的忍受能力还是很强的,哈哈。Page、VMA、VAC、VA组成了如此复杂的层次结构到底是为什么呢?是为了打击你学习内核的兴趣吗?非也,让我们还是用一个实际的场景来说明这个“大厦”的功能。
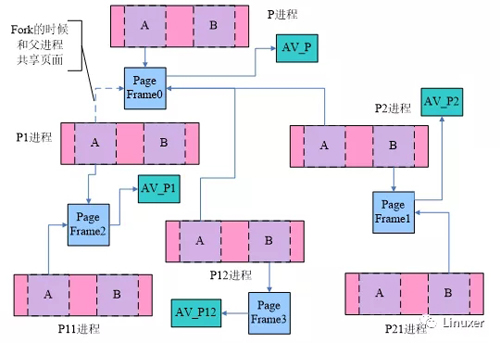
我们通过下面的步骤建立起上图的结构:
(1) P进程的某个VMA中有两类页面: 一类是有真实的物理页面的,另外一类是还没有配备物理页面的。上图中,我们分别跟踪有物理页面的A以及还没有分配物理页面的B。
(2) P进程fork了P1和P2
(3) P1进程fork了P12进程
(4) P1进程访问了A页面,分配了page frame2
(5) P12进程访问了B页面,分配了page frame3
(6) P2进程访问了B页面,分配了page frame1
(7) P2进程fork了P21进程
经过上面的这一些动作之后,我们来看看page frame共享的情况:对于P进程的page frame(是指该page 的mapping成员指向P进程的AV,即上图中的AV_P)而言,他可能会被任何一个level的的子进程VMA中的page所有共享,因此AV_P需要包括其子进程、孙进程……的所有的VMA。而对于P1进程而言,AV_P1则需要包括P1子进程、孙进程……的所有的VMA,有一点可以确认:至少父进程P和兄弟进程P2的VMA不需要包括在其中。
现在我们回头看看AV结构的大厦,实际上是符合上面的需求的。
8、页面回收的时候,如何unmap一个page frame的所有的映射?
搭建了那么复杂的数据结构大厦就是为了应用,我们一起看看页面回收的场景。这个场景需要通过page frame找到所有映射到该物理页面的VMAs。有了前面的铺垫,这并不复杂,通过struct page中的mapping成员可以找到该page对应的AV,在该AV的红黑树中,包含了所有的可能共享匿名页面的VMAs。遍历该红黑树,对每一个VMA调用try_to_unmap_one函数就可以解除该物理页帧的所有映射。
OK,我们再次回到这一章的开始,看看那个长临界区导致的性能问题。假设我们的服务器上有一个服务进程A,它fork了999个子进程来为世界各地的网友服务,进程A有一个VMA,有1000个page。下面我们就一起来对比新旧机制的处理过程。
首先,百万page共享一个anon_vma的情况在新机制中已经解决,每一个进程都有自己特有的anon_vma对象,每一个进程的page都指向自己特有的anon_vma对象。在旧的机制中,每次unmap一个page都需要扫描1000个VMA,而在新的机制中,只有顶层的父进程A的AV中有1000个VMA,其他的子进程的VMA的数目都只有1个,这大大降低了临界区的长度。
七、后记
本文带领大家一起简略的了解了逆向映射的发展过程。当然,时间的车轮永不停息,逆向映射机制还在不断的修正,如果你愿意,也可以了解其演进过程的基础上,提出自己的优化方案,在其历史上留下自己的印记。
作者简介
郭健,一名普通的内核工程师,以钻研Linux内核代码为乐,热衷于技术分享,和朋友一起创建了蜗窝科技的网站,希望能汇集有同样想法的技术人,以蜗牛的心态探讨技术。