负载均衡
负载均衡是云计算的基础组件,是网络流量的入口,其重要性不言而喻。
什么是负载均衡呢?用户输入的流量通过负载均衡器按照某种负载均衡算法把流量均匀地分散到后端的多个服务器上,接收到请求的服务器可以独立的响应请求,达到负载分担的目的。从应用场景上来说,常见的负载均衡模型有全局负载均衡和集群内负载均衡,从产品形态角度来说,又可以分为硬件负载均衡和软件负载均衡。
全局负载均衡一般通过DNS实现,通过将一个域名解析到不同VIP,来实现不同的region调度能力;硬件负载均衡器常见的有F***10、Array,它们的优缺点都比较明显,优点是功能强大,有专门的售后服务团队,性能比较好,缺点是缺少定制的灵活性,维护成本较高;现在的互联网更多的思路是通过软件负载均衡来实现,这样可以满足各种定制化需求,常见的软件负载均衡有LVS、Nginx、Haproxy。

我们的高性能负载均衡使用LVS和Tengine,在一个region区分不同的机房,每个机房都有LVS集群和Tengine集群,对于用户配置的四层监听,LVS后面会直接挂载用户ECS,七层用户监听ECS则挂载在Tengine上,四层监听的流量直接由LVS转发到ECS,而7层监听的流量会经过LVS到Tenigine再到用户ECS。每一个region里都会有多个可用区,达到主备容灾目的,每一个集群里都有多台设备,***是为了提升性能,第二也是基于容灾考虑。

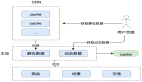
上图为高性能负载均衡控制管理概要图,SLB产品也有SDN概念,转发和控制是分离的,用户所有配置通过控制台先到控制器,通过集中控制器转换将用户配置推送到不同设备上,每台设备上都有Agent接收控制器下发的需求,通过本地转换成LVS和Tengine能够识别的配置,这个过程支持热配置,不影响用户转发,不需要reload才能使新配置生效。
LVS
1. LVS支持的三种模式

早期LVS支持三种模式,DR模式、TUN模式和NAT模式。
DR模式经过LVS之后,LVS会将MAC地址更改、封装MAC头,内层IP报文不动,报文经过LVS负载均衡查找到RS之后,将源MAC头改成自己的,目的MAC改成RS地址,MAC寻址是在二层网络里,对网络部署有一定的限定,在大规模分布式集群部署里,这种模式的灵活性没有办法满足需求;
TUN模式走在LVS之后,LVS会在原有报文基础上封装IP头,到了后端RS之后,RS需要解开IP报文封装,才能拿到原始报文,不管是DR模式还是TUN模式,后端RS都可以看到真实客户源IP,目的IP是自己的VIP,VIP在RS设备上需要配置,这样可以直接绕过LVS返回给用户,TUN模式问题在于需要在后端ECS上配置解封装模块,在Linux上已经支持这种模块,但是windows上还没有提供支持,所以会对用户系统镜像选择有限定。
NAT模式用户访问的是VIP,LVS查找完后会将目的IP做DNAT转换,选择出RS地址,因为客户端的IP没变,在回包的时候直接向公网真实客户端IP去路由,NAT的约束是因为LVS做了DNAT转换,所以回包需要走LVS,把报文头转换回去,由于ECS看到的是客户端真实的源地址,我们需要在用户ECS上配置路由,将到ECS的默认路由指向LVS上,这对用户场景也做了限制。
2. LVS基于Netfilter框架实现

Netfilter是Linux提供的网络开放平台,基于平台可以开发自己的业务功能模块,早期好多安全厂商都是基于Netfilter做一些业务模型实现,这种模型比较灵活,但通用模型里更多的是兼容性考虑,路径会非常长;而且通用模型中没办法发挥多核特性,目前CPU的发展更多是向横向扩展,我们经常见到多路服务器,每路上有多少核,早期通用模型对多核支持并不是特别友善,在多核设计上有些欠缺,导致我们在通用模型上做一些应用开发时的扩展性是有限的,随着核的数量越来越多,性能不增反降。
3. LVS的改进

- 早期模式的各种限制制约了我们的发展,所以我们首先做了FullNAT,相比原来的NAT方式,FullNAT多了SNAT属性,将客户端的原IP地址作了转换;
- 其次,我们在并行化上做了处理,充分利用多核实现性能线性提升;
- 然后是快速路径,我们在做网络转发模型时很容易想到设计快速路径和慢速路径,慢速路径更多是解决首包如何通过设备问题,可能需要查ACL或路由,需要判断许多和策略相关的东西,后面所有报文都可以通过快速路径转发出去;
- 还有指令相关优化,利用因特尔特殊指令提升性能;
- 另外针对多核架构,NUMA多节点内存访问,通过访问Local节点内存可能获得更好的延迟表现。
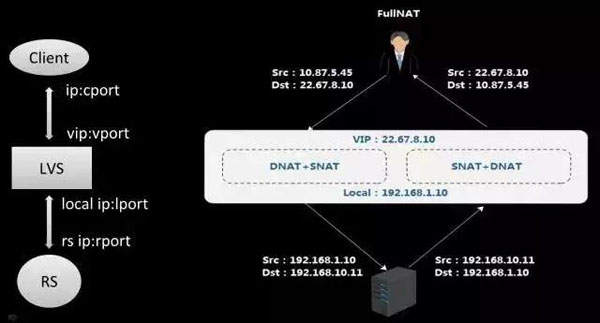
客户端进来IP首先访问LVS的VIP,原IP是客户端的,目的IP是LVS的VIP,经过FullNAT转换后,原IP变成LVS的Local地址,目的地址是LVS选择出来的RS地址,这样在RS回包时比较容易,只要路由可达,报文一定会交到LVS上,不需要在RS上做特殊的配置。右面就是DNAT+SNAT转换,报文就可以通过LVS转发回客户端,这种方式主要带来应用场景部署灵活性选择。
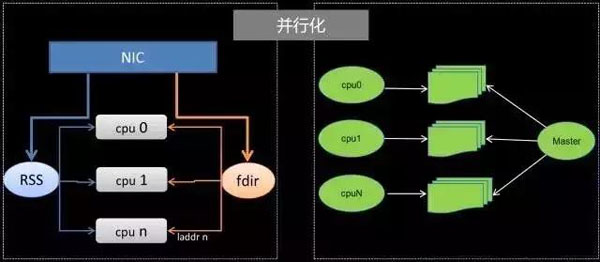
通过并行化实现对LVS性能的改善,性能没有办法得到线性提升更多的是因为每条路径都需要访问全局资源,就会不可避免引入锁的开箱,另外,同一条链接上的报文可能分散在不同的核上,大家去访问全局资源时也会导致cache的丢失。
所以我们通过RSS技术把同一个五源组报文扔到同一个CPU上处理,保证入方向的所有相同连接上的报文都能交给相同CPU处理,每个核在转发出去时都用当前CPU上的Local地址,通过设置一些fdir规则,报文回来时后端RS访问的目的地址就是对应CPU上的local地址,可以交到指定的CPU上去处理,这样一条连接上左右方向报文都可以交给同一个CPU处理,将流在不同的CPU隔离开。
另外,我们把所有配置资源包括动态缓存资源在每个CPU上作了拷贝, 将资源局部化,这使整个流从进入LVS到转发出去访问的资源都是固定在一个核上的本地资源,使性能达到较大化,实现线性提升。
经过我们改进之后,LVS的具体表现如下:
- 出于对容灾和性能提升的考虑,我们做了集群化部署,每个region有不同机房,每个机房有多个调度单元,每个单元有多台LVS设备;
- 每台LVS经过优化后,都能达到更高性能,大容量,单台LVS可以达到4000W PPS,600W CPS、单个group可以到达1亿并发;
- 支持region、IDC、集群和应用级的高可用;
- 实现了防×××功能,并在原版LVS上提供了更丰富的功能,可以基于各个维度做管理控制,较精确的统计,流量的分析等。
Tengine
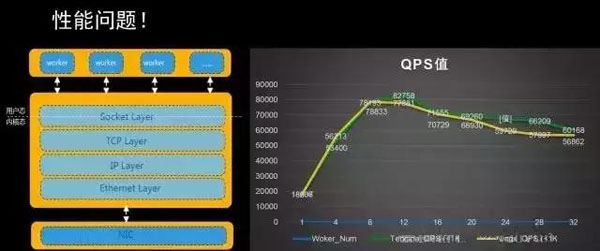
Tengine在应用过程中也遇到了各种问题,最严重的就是性能问题,我们发现随着CPU数量越来越多,QPS值并没有线性提升;Nginx本身是多worker模型,每个worker是单进程模式,多worker架构做CPU亲和,内部基于事件驱动的模型,其本身已经提供了很高的性能,单核Nginx可以跑到1W5~2W QPS。Nginx往下***层是socket API,socket 往下有一层VFS,再往下是TCP、IP,socket层比较薄,经过量化的分析和评估,性能开销较大的是TCP协议栈和VFS部分,因为同步开销大,我们发现横向扩展不行,对此,我们做了一些优化。
七层反向代理的路径更长,处理更复杂,所以它的性能比LVS低很多,我们比较关注单机和集群的性能,集群性能可以靠堆设备去解决,单机如果不提升,成本会一直增加,从性能角度来看,有以下的优化思路和方向:
- 基于Kernel做开发,比如优化协议栈;
- 基于Aliscoket的优化,Alisocket是阿里研发的高性能TCP协议栈平台,底层是DPDK,它将资源做了局部化处理,报文分发不同核处理,性能非常出色;
- HTTPS业务越来越多,流量逐步递增,我们采用硬件加速卡方式做一些加解密的性能提升,还有HTTPS的会话复用;
- 基于Web传输层的性能优化。
从弹性角度看,比如一些公司的应用和用户热点有关,当发生一个社会网络热点后,访问量会急剧变高,我们固有的基于物理机器实现的负载均衡模型在弹性扩展方面是有限制的,对此,我们可以使用VM去做,把反向代理功能放在VM去跑,我们会监控实例负载情况,根据实时需求做弹性扩容缩容;
除了VM,还有调度单元,我们可以在不同调度单元做平滑切换,根据不同的水位情况,通过切换可以把负载均衡实例调度到不同的单元中去,改善使容量上管理。Tengine本身也做了集群化部署,我们在一个region里有不同的机房,不同的调度单元,每个调度单元有多组设备;LVS到Tengine也有健康检查,如果一台Tengine有问题,可以通过健康检查方式摘除,不会影响用户转发能力;
Tengine具备灵活的调度能力,可以帮助我们应对更多的复杂情况;另外,Tengine也有很多高级的特性,比如基于cookie的会话保持、基于域名/URL的转发规则、HTTP2、Websocket等功能;目前,我们7层单VIP可以支撑10W规格的HTTPS QPS。
高可用
1. Group

高可用是整个产品很重要的一部分,图为集群内的高可用架构图,可以看到,在网络路径上是全冗余无单点的。具体情况如下:
- 双路服务器,每节点双网口上联不同交换机,增加带宽,避免跨节点收包
- VIP路由两边发不同的优先级,不同的VIP,高优先级路由在不同的交换机上
- 单机160G转发能力,单VIP 80G带宽,单流 40G带宽
- 网卡故障不影响转发,上下游路由自动切换
- ECMP,VIP路由发两边,通过优先级控制从入口
- 集群640G转发能力,单vip 320G带宽
- 会话同步,多播、包触发同步、定时同步
- 单机故障不影响转发
- 交换机故障不影响转发,路由秒级切换
- 用户无感知的升级变更,部分未及时同步的连接重连即可
2. AZ

每个机房连接两个不同路由器,当一个AZ出现故障之后,我们可以无缝切换到另外一个机房,具体情况如下:
- VIP在不同的AZ发不同优先级的路由(秒级切换、自动切换)
- VIP区分主备AZ,不同的VIP主备AZ不同
- 多个AZ的负载通过控制系统分配
- 缺省提供VIP多AZ的容灾能力
- 不支持跨AZ的session同步,跨AZ切换后,所有连接都需要重连
3. Region

当用户访问域名时,通过DNS解析,可以设定DNS解析到多个regionVIP地址,下沉到某一个Region来看,如果一个机房出现故障,流量可以切换到另一个可用区继续转发,如果流量进到机房发现一台LVS转发设备出现故障后,我们可以切换到另外一台LVS作处理,如果LVS后面挂载的RS出现问题,通过健康检查也可以快速摘掉设备,将流量转换到健康的设备上去。我们从多个维度实现高可用,较大限度地满足用户的需求。
总结
目前,高性能负载均衡应用主要在几个方面:
- 作为公有云基础组件,为公有云网站、游戏客户、APP提供负载均衡功能,也针对政府、金融等安全性高的客户提供专有云支持;
- 为阿里云内部云产品RDS、OSS、高防等提供了负载均衡的功能;
- 负载均衡作为电商平台入口,向淘宝、天猫、1688提供VIP统一接入功能;
- 交易平台的流量入口也在负载均衡设备上,如支付宝、网上银行。
未来,我们希望有更好的弹性扩展能力,更高的单机处理能力,我们希望VIP主动探测用户,以及网络全链路监控。