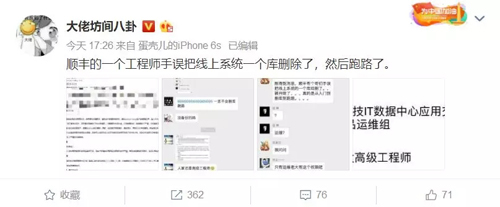
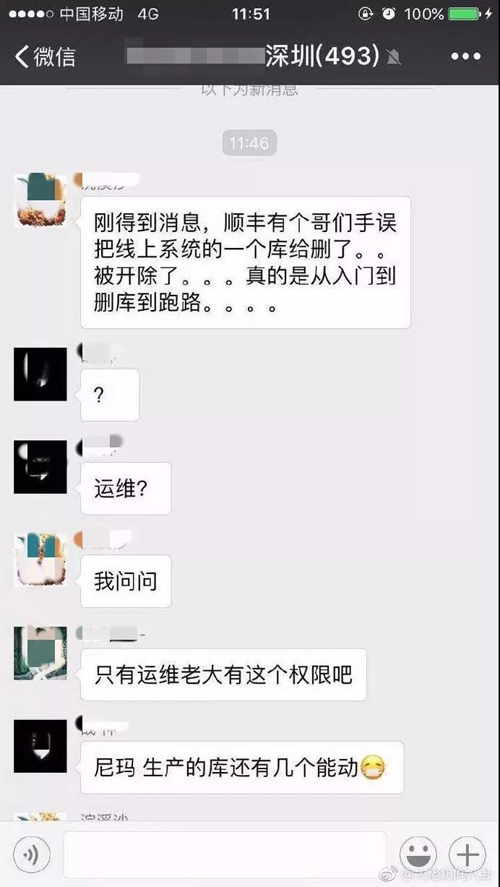
9 月 19 日下午,据微博网友大佬坊间八卦爆料,顺丰的一个工程师手误把线上系统一个库删除了,然后跑路了。
根据邮件内容,事件详情如下:
在接到该变更需求后,按照操作流程要求,登陆生产数据库跳转机,通过 navicat-mysql 客户端管理工具,连入 SHIVA-OMCS 的 RUSS 库进行操作。
但在操作过程中,该运维发现选错了 RUSS 数据库,打算删除执行的 sql。
在选定删除时,因其操作不严谨,光标回跳到 RUSS 库的实例上,在未看清所选内容的情况下,便通过 delete 执行删除,同时,他忽略了弹窗提示,直接回车,导致 RUSS 库被删除。
因运维人员工作不严谨的操作,导致 OMCS 运营监控系统发生故障,该系统上临时车线上发车功能无法使用并持续约 590 分钟。同比 9 月 5 日的 929 条临时车需求,此次故障对业务产生了严重的负面影响。

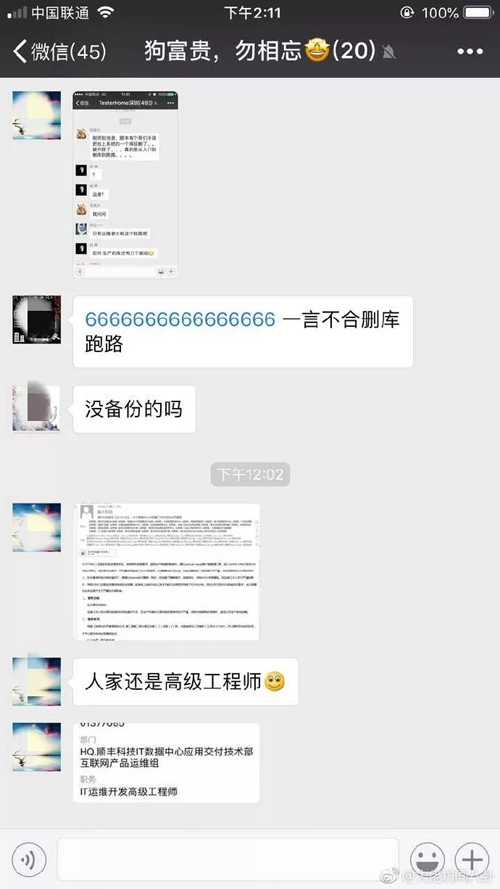
根据顺丰规定,予以开除,并通报公司批评。此外,据说该员工任职顺丰科技 IT 数据中心应用交付技术部互联网产品运维组,职务 IT 运维开发高级工程师。
如何看待顺丰工程师误删公司数据库被开除一事?
目前,此事已经在圈内传开了,各路网友开始吐槽:
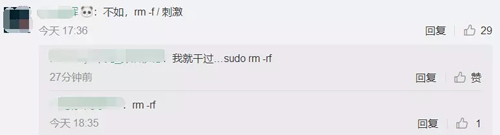
有幸灾乐祸调侃型的:不如,rm -f / 刺激。
也有人调侃称:删的时候肯定很激动!

还有人调侃:付出如此巨大的代价,培养起了一个运维工程师的安全意识,然后竟然把他开除了?
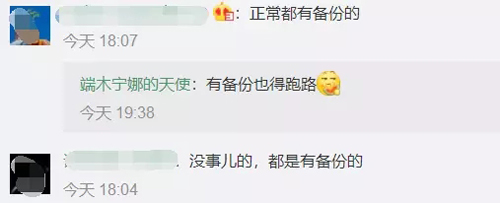
最后就是关于是否备份的讨论:
不过最狠的还是属这一条,反手丢给你一本 MySQL 从删库到跑路:

看看有没有什么后路好走啊哥们:国内呆不下了,赶紧出国。首先,不要选动车,要选最近的一班飞机,尽快出国,能走高速走高速,不然选人少的路线。
没错,我们 DBA 都是常备护照的。切记,注意看高德地图实时路况。我们有个前辈就是删库之后开车就上二环,下午五点钟。警察到的时候他还堵在路上。
以下为知乎网友的精彩评论:
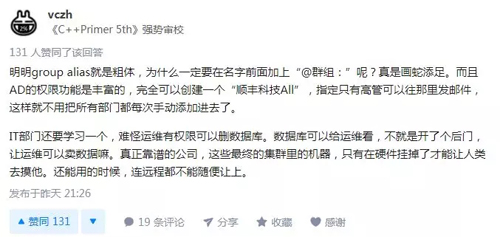
知乎网友 @vczh 表示:
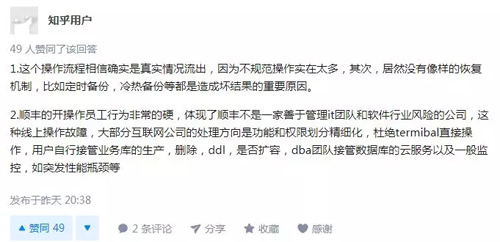
知乎网友@匿名用户回答:
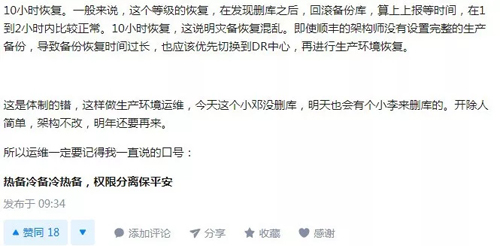
知乎@匿名用户:

最后,我们再来看看一位资深运维人对顺丰数据库被误删事件后的思考:
我们先来算一算,590 分钟不可用是个什么概念,大概相当于 10 个小时业务不可用。
我们按 365 天来算,一年为 525600 分钟,590 分钟服务不可用就意味着这次事件将服务可用性降低到了 99.88%。
那么 99.88% 是个什么概念呢,这个数值可能有些人觉得蛮高的,但是其实在互联网公司,对于做 OLTP 业务的数据库来说,估计一年的 KPI 都没有了。
尤其是对于电商,交易,金融相关的业务来说,10 个小时不可用那简直就和灾难一样。所以这个运维小哥被开除也应该不足为奇吧。
目前我也不清楚这个运维小哥什么情况,也不知道这 10 个小时是否影响的是核心业务,也不知道为什么要十个小时才恢复起来。我就数据库被删除这件事件和大家聊聊我的想法。
首先说说数据库什么情况下会被删,我想不外乎两种情况,要么是被恶意删除,那么就是被误操作删除。
恶意删除这种没什么好说的,删除了肯定根据公司损失来定责,性质比较恶劣,当然是严惩不贷,甚至是追究法律责任。我们重点来说说误操作这种情况。
为什么会产生误操作事件呢,我理解的误操作是有两种情况:
第一种是对技术的研究不够深入,导致操作误判出现故障,从而影响到线上业务,比如线上某台数据库由于 SQL 索引缺失造成性能问题,导致 SQL 堆积和数据库 CPU 飙升。
这个时候我们应该怎么操作呢,是Kill SQL,还是在线加索引,还是回滚业务?
我们都知道一般 SQL 索引问题可以通过加索引来解决,但是在这种数据库高负荷的情况下,加索引可能会导致数据库资源消耗更加严重,从而导致主库不可用。
这种情况下和业务方沟通 Kill 掉问题 SQL 并且回滚代码可能是比较好的办法,或者备库加好索引进行 MHA 切换也是可以的,这些需要 DBA 同学对数据库技术和线上操作有一定的经验才可以准确判断如何处理这个问题。
如果操作误判可能就是事故了,但是这些本身是技术经验相关的,随着工作经验的增加,这种误操作故障会越来越少。
第二种就是纯粹的误操作,误删库,误删表,误删数据,rm -rf 等等。比如运维同学手抖按了回车,眼睛看花眼把数据库选错了,复制粘贴错了,敲命令太快了等。
这种故障和上面说的技术和经验无关了,虽然不是恶意的,但是确实和操作人有关系。这种事件是在运维操作里需要格外小心和关注的。
真出了事情,什么理由都不是理由,KPI 没了,年终奖没了,甚至工作也没了,甚至还影响到自己部门的 KPI 考核。
这些事情不论是作为运维人员,还是部门领导都是不愿看到的事情,那么这种误操作怎么能够防范和避免呢,根据我自己的工作经验,我大概总结了下面几点:
责任心+细心
其实没什么好说的,不论什么事情和工作,责任心都是基础,自己的事情自己负责到底,有始有终,这个是考虑一个人首要条件,作为一个 DBA,更加不用说,没有责任心,做不了 DBA。
对生产环境的敬畏之心
之前看到一些公司的招聘要求,其中有一条就是对生产环境的敬畏之心,作为一个工作 N 年的 DBA 来说,这点现在越来越体会比较深刻。
工作经验越久,胆子反而越来越小,线上环境操作各种确认,一些重大变更回车迟迟不敢敲下,总要 Delay 半分钟。
其实我觉得作为一个 DBA 这是一个好的习惯,DBA 不是搬瓦工,不需要你快速操作,保障线上数据安全和持续稳定才是第一位的。
Double Check 机制
Double Check 机制是一个重大变更减少事故的好习惯。很多时候,过于可能会出现失误,有一些错误是自己永远发现不了的,当局者迷,旁观者清,这个时候第二个人帮你 Review 操作可能帮助你减少故障。
所以我建议对于生成变更走 Double Check 机制是个很好的习惯。
个人心态
另外一点我想聊的是人无圣人,孰能无过,也许只有经历过一些事故才能更好的成长。
当出现问题时,也不需要惊慌,把每次故障当成一次成长,出现问题,积极总结问题和故障复盘,要避免的是不要在同一个地方犯同样的错误,也是一种成长。
如何优雅地防止从删库到跑路?
换人容易,我们要从根本处避免问题的再次出现。运维不易,且行且珍惜。
但如果我在服务器维护的时候不小心执行了 rm -rf 命令……现在整台服务器被我删光了肿么办???......所以程序员特别喜欢跑步锻炼。
好吧,言归正传。下面我们来讨论下,程序员如何优雅地防止数据误删。现在先来介绍一下 rm。
rm -rf 的威力
rm 是 Linux 系统下删除文件的命令,-r 代表删除这个下面的一切,一切的一切那种的一切。f 表示不需要用户确认,直接执行。
通常这个命令都是指定文件夹用的,比如:
就是删除 /home/test/ 这个文件夹下面的所有东西。但是如果后面的文件夹路径没有加对,rm -rf / 在服务器上也就意味着…解脱了......
俗话说的好:常在河边走,哪能不湿鞋。那该怎么避免这种悲剧的发生呢?
如何避免再次跑路?
一个方案就是重定向 rm 命令以嫁接为 mv 命令,相当于给 Linux 系统定制了一个回收站。
实现方式如下:
最后将上述脚本写入 /etc/bashrc,并立即执行命令 source /etc/bashrc 即刻生效。
这个脚本定义了几个命令:
- rl:查看回收站下的文件。
- unrm 文件名或目录:恢复到当前的路径下。
- rmtrash:清空回收站,不过会友好提示。
执行 rm 不会真正删除,而是使用 mv 移动到我们指定的回收站。实在真的想删除可以 /bin/rm 来进行删除。
另外,需要注意的是,之前 rm 指令的一些参数可能不再使用,因为 rm 现在其实是 mv 了。
使用示例:
效果看着应该还可以吧。
虽然看着是还可以,但是也有一些问题,比如删除文件不能重名,若重名了会提示你是否进行覆盖。
那就需要再进行特殊处理了,比如删除时加个时间戳什么的,有兴趣的动手实现下吧。参考:https://www.cloudbility.com/club/6981.html
出处:《如何优雅地使用 rm 防止误删除?》一文来自【不正经程序员】微信公众号,作者:hoxis;《顺丰数据库被误删事件后的思考》一文来自【DBARUN社区】微信公众号,作者:茹作军,其他素材是互联网综合整理。
留 言 有 礼 活 动
作为程序员,您怎么看待顺丰工程师误删公司数据库被开除一事?扫描下方二维码,关注51CTO技术栈公众号。欢迎在技术栈微信公众号留言探讨。小编将精选出最有价值的三条评论,分别获得 50、30、20 元 的 红 包 奖 励,活动截止时间 9 月 28 号 12 时整。