数据分析指导商业行为的价值越来越高,使得用户对数据实时分析的要求变得越来越高。使用传统RDBMS数据分析架构,遇到了***的挑战,高延迟、数据处理流程复杂和成本过高。这篇文章讨论如何利用SQL Server 2016列存储技术做实时数据分析,解决传统分析方法的痛点。
传统RDBMS数据分析
在过去很长一段时间,企业均选择传统的关系型数据库做OLAP和Data Warehouse工作。这一节讨论传统RDBMS数据分析的结构和面临的挑战。
传统RDBMS分析架构
传统关系型数据库做数据分析的架构,按照功能模块可以划分为三个部分:
OLTP模块:OLTP的全称是Online Transaction Processing,它是数据产生的源头,对数据的完整性和一致性要求很高;对数据库的反应时间(RT: Response Time)非常敏感;具有高并发,多事务,高响应等特点。
ETL模块:ETL的全称是Extract Transform Load。他是做数据清洗、转化和加载工作的。可以将ETL理解为数据从OLTP到Data Warehouse的“搬运工”。ETL***的特定是具有延时性,为了***限度减小对OLTP的影响,一般会设计成按小时,按天或者按周来周期性运作。
OLAP模块:OLAP的全称是Online Analytic Processing,它是基于数据仓库(Data Warehouse)做数据分析和报表呈现的终端产品。数据仓库的特点是:数据形态固定,几乎或者很少发生数据变更,统计查询分析读取数据量大。
传统的RDBMS分析模型图,如下图展示(图片直接截取自微软的培训材料):
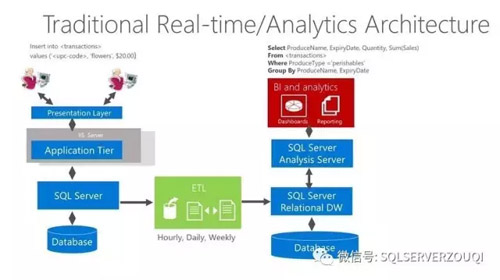
从这个图,我们可以非常清晰的看到传统RDBMS分析模型的三个大的部分:在图的最左边是OLTP业务场景,负责采集和产生数据;图的中部是ETL任务,负责“搬运”数据;图的右边是OLAP业务场景,负责分析数据,然后将分析结果交给BI报表展示给最终用户。企业使用这个传统的架构长达数年,遇到了不少的挑战和困难。
面临的挑战
商场如战场,战机随息万变,数据分析结果指导商业行为的价值越来越高,使得数据分析结果变得越来越重要,用户对数据实时分析的要求变得越来越高。使用传统RDBMS分析架构,遇到了***的挑战,主要的痛点包括:
- 数据延迟大
- 数据处理流程冗长复杂
- 成本过高
数据延迟大:为了减少对OLTP模块的影响,ETL任务往往会选择在业务低峰期周期性运作,比如凌晨。这就会导致OLAP分析的数据源Data Warehouse相对于OLTP有至少一天的时间差异。这个时间差异对于某些实时性要求很高的业务来说,是无法接受的。比如:银行卡盗刷的检查服务,是需要做到秒级别通知持卡人的。试想下,如果你的银行卡被盗刷,一天以后才收到银行发过来的短信提醒,会是多么糟糕的体验。
数据处理流程冗长复杂:数据是通过ETL任务来抽取、清洗和加载到Data Warehouse中的。为了保证数据分析结果的正确性,ETL还必须要解决一系列的问题。比如:OLTP变更数据的捕获,并同步到Data Warehouse;周期性的进行数据全量和增量更新来确保OLTP和Data Warehouse中数据的一致性。整个数据流冗长,实现逻辑异常复杂。
成本过高:为了实现传统的RDBMS数据分析功能,必须新增Data Warehouse角色来保存所有的OLTP数据冗余,专门提供分析服务功能。这势必会加大了硬件、软件和维护成本投入;随之还会到来ETL任务做数据抓取、清洗、转换和加载的开发成本和时间成本投入。
那么,SQL Server有没有一种技术既能解决以上所有痛点的方法,又能实现数据实时分析呢?当然有,那就是SQL Server 2016列存储技术。
SQL Server 2016列存储技术做实时分析
为了解决OLAP场景的查询分析,微软从SQL Server 2012开始引入列存储技术,大大提高了OLAP查询的性能;SQL Server 2014解决了列存储表只读的问题,使用场景大大拓宽;而SQL Server 2016的列存储技术彻底解决了实时数据分析的业务场景。用户只需要做非常小规模的修改,便可以可以非常平滑的使用SQL Server 2016的列存储技术来解决实时数据分析的业务场景。这一节讨论以下几个方面:
SQL Server 2016数据分析架构
- Disk-based Tables with Nonclustered Columnstore Index
- Memory-based Tables with Columnstore Index
- Minimizing impacts of OLTP
SQL Server 2016数据分析架构
SQL Server 2016数据分析架构相对于传统的RDBMS数据分析架构有了非常大的改进,变得更加简单。具体体现在OLAP直接接入OLTP数据源,如此就无需Data Warehouse角色和ETL任务这个“搬运工”了。
OLAP直接接入OLTP数据源:让OLAP报表数据源直接接入OLTP的数据源头上。SQL Server会自动选择合适的列存储索引来提高数据分析查询的性能,实现实时数据分析的场景。
不再需要ETL任务:由于OLAP数据源直接接入OLTP的数据,没有了Data Warehouse角色,所以不再需要ETL任务,从而大大简化了数据处理流程中的各环节,没有了相应的开发维护和时间成本。
SQL Server 2016实时分析架构图,展示如下(图片来自微软培训教程):
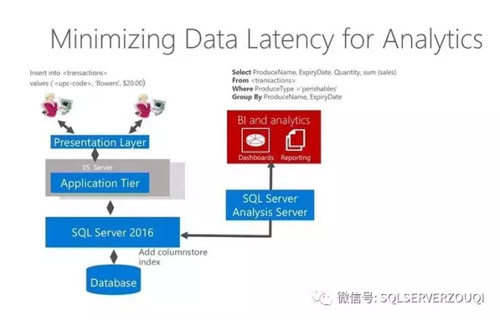
SQL Server 2016之所以能够实现如此简化的实时分析,底气是来源于SQL Server 2016的列存储技术,我们可以建立基于磁盘存储或者基于内存存储的列存储表来进行实时数据分析。
Disk-based Tables with Nonclustered Columnstore Index
使用SQL Server 2016列存储索引实现实时分析的***种方法是为表建立非聚集列存储索引。在SQL Server 2012版本中,仅支持非聚集列存储索引,并且表会成为只读,而无法更新;在SQL Server 2014版本中,支持聚集列存储索引表,且数据可更新;但是非聚集列存储索引表还是只读;而在SQL Server 2016中,完全支持非聚集列存储索引和聚集列存储索引,并且表可更新。所以,在SQL Server 2016版本中,我们完全可以建立非聚集列存储索引来实现OLAP的查询场景。创建方法示例如下:
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (OrderID, AutoID, UserID, OrderQty, Price, OrderDate, OrderStatus)
- ;
- GO
在这个实例中,我们创建了SalesOrder表,并且为该表创建了非聚集列存储索引,当进行OLAP查询分析的时候,SQL Server会直接从该列存储索引中读取数据。
Memory-based Tables with Columnstore Index
SQL Server 2014版本引入了In-Memory OLTP,又或者叫着Hekaton,中文称之为内存优化表,内存优化表完全是Lock Free、Latch Free的,可以***限度的增加并发和提高响应时间。而在SQL Server 2016中,如果你的服务器内存足够大的话,我们完全可以建立基于内存优化表的列存储索引,这样的表数据会按列存储在内存中,充分利用两者的优势,***程度的提高查询查询效率,降低数据库响应时间。创建方法实例如下:
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED HASH (OrderID) WITH (BUCKET_COUNT = 10000000)
- ) WITH(MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) ;
- GO
- ALTER TABLE dbo.SalesOrder
- ADD INDEX CCSI_SalesOrder CLUSTERED COLUMNSTORE
- ;
- GO
在这个实例中,我们创建了基于内存的优化表SalesOrder,持久化方案为表结构和数据;然后在这个内存表上建立聚集列存储索引。当OLAP查询分析执行的时候,SQL Server可以直接从基于内存的列存储索引中获取数据,大大提高查询分析的能力。
Minimizing impacts of OLTP
考虑到OLTP数据源的高并发,低延迟要求的特性,在某些非常高并发事务场景中,我们可以采用以下方法***限度减少对OLTP的影响:
- Filtered NCCI + Clustered B-Tree Index
- Compress Delay
- Offloading OLAP to AlwaysOn Readable Secondary
- Filtered NCCI + Clustered B-Tree Index
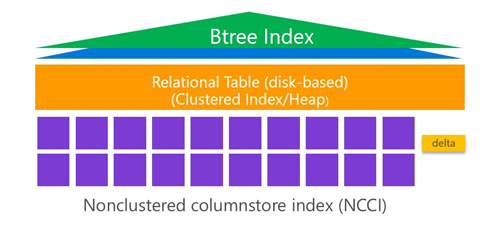
带过滤条件的索引在SQL Server产品中并不是什么全新的概念,在SQL Server 2008及以后的产品版本中,均支持创建过滤索引,这项技术允许用户创建存在过滤条件的索引,以加速特定条件的查询语句使用过滤索引。而在SQL Server 2016中支持存在过滤条件的列存储索引,我们可以使用这项技术来区分数据的冷热程度(数据冷热程度是指数据的修改频率;冷数据是指几乎或者很少被修改的数据;热数据是指经常会被修改的数据。比如在订单场景中,订单从生成状态到客户收到货物之间的状态,会被经常更新,属于热数据;而客人一旦收到货物,订单信息几乎不会被修改了,就属于冷数据)。利用过滤列存储索引来区分冷热数据的技术,是使用聚集B-Tree索引来存放热数据,使用过滤非聚集列存储索引来存放冷数据,这样SQL Server 2016的优化器可以非常智能的从非聚集列存储索引中获取冷数据,从聚集B-Tree索引中获取热数据,这样使得OLAP操作与OLTP事务操作逻辑隔离开来,最终OLAP***限度的减少对OLTP的影响。
下图直观的表示了Filtered NCCI + Clustered B-Tree Index的结构图(图片来自微软培训教程):
实现方法参见以下代码:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- /*
- — OrderStatus Description
- — 0 => ‘Placed’
- — 1 => ‘Closed’
- — 2 => ‘Paid’
- — 3 => ‘Pending’
- — 4 => ‘Shipped’
- — 5 => ‘Received’
- */
- CREATE CLUSTERED INDEX CI_SalesOrder
- ON dbo.SalesOrder(OrderStatus)
- ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WHERE orderstatus = 5
- ;
- GO
在这个实例中,我们创建了SalesOrder表,并在OrderStatus字段上建立了Clustered B-Tree结构的索引CI_SalesOrder,然后再建立了带过滤条件的非聚集列存储索引NCCI_SalesOrder。当客人还未收到货物的订单,会处于前面五中状态,属于需要经常更新的热数据,SQL Server查询会根据Clustered B-Tree索引CI_SalesOrder来查询数据;客人已经收货的订单,处于第六种状态,属于冷数据,SQL Server查询冷数据会直接从非聚集列存储索引中获取数据。从而***限度减少对OLTP影响的同时,提高查询效率。
Compress Delay
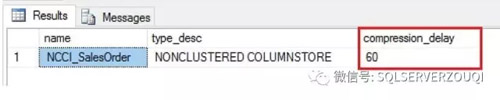
如果按照业务逻辑层面很难明确划分出数据的冷热程度,也就是说很难从过滤条件来逻辑区分数据的冷热。这种情况下,我们可以使用延迟压缩(Compress Delay)技术从时间层面来区分冷热数据。比如:我们定义超过60分钟的数据为冷数据,60分钟以内的数据为热数据,那么我们可以在创建列存储索引的时候添加WITH选项COMPRESSION_DELAY = 60 Minutes。当数据产生超过60分钟以后,数据会被压缩存放到列存储索引中(冷数据),60分钟以内的数据会驻留在Delta Store的B-Tree结构中,这种延迟压缩的技术不但能够达到隔离OLAP对OLTP作用,还能***限度的减少列存储索引碎片的产生。
实现方法参见以下例子:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WITH(COMPRESSION_DELAY = 60 MINUTES)
- ;
- GO
- SELECT name
- ,type_desc
- ,compression_delay
- FROM sys.indexes
- WHERE object_id = object_id('SalesOrder')
- AND name = 'NCCI_SalesOrder'
- ;
检查索引信息截图如下:
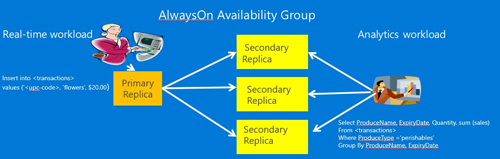
Offloading OLAP to AlwaysOn Readable Secondary
另外一种减少OLAP对OLTP影响的方法是利用AlwaysOn只读副本,这种情况,可以将OLAP数据源从OLTP剥离出来,接入到AlwaysOn的只读副本上。AlwaysOn的主副本负责事务处理,只读副本可以作为OLAP的数据分析源,这样实现了OLAP与OLTP的物理隔离,将影响减到***。架构图如下所示(图片来自微软培训教程):
一个实际例子
在订单系统场景中,用户收到货物过程,每个订单会经历6中状态,假设为Placed、Canceled、Paid、Pending、Shipped和Received。在前面5中状态的订单,会被经常修改,比如:打包订单,出库,更新快递信息等,这部分经常被修改的数据称为热数据;而订单一旦被客人接受以后,订单数据就几乎不会被修改,这部分数据称为冷数据。这个例子就是使用SQL Server 2016 Filtered NCCI + Clustered B-Tree索引的方式来逻辑划分出数据的冷热程度,SQL Server在查询过程中,会从非聚集列存储索引中取冷数据,从B-Tree索引中取热数据,***限度提高OLAP查询效率,减少对OLTP的影响。
具体建表代码实现如下:
- -- create demo table SalesOrder
- DROP TABLE IF EXISTS dbo.SalesOrder;
- GO
- CREATE TABLE dbo.SalesOrder
- (
- OrderID BIGINT IDENTITY(1,1) NOT NULL
- ,AutoID INT NOT NULL
- ,UserID INT NOT NULL
- ,OrderQty INT NOT NULL
- ,Price DECIMAL(8,2) NOT NULL
- ,OrderDate DATETIME NOT NULL
- ,OrderStatus SMALLINT NOT NULL
- CONSTRAINT PK_SalesOrder PRIMARY KEY NONCLUSTERED (OrderID)
- ) ;
- GO
- /*
- — OrderStatus Description
- — 0 => ‘Placed’
- — 1 => ‘Closed’
- — 2 => ‘Paid’
- — 3 => ‘Pending’
- — 4 => ‘Shipped’
- — 5 => ‘Received’
- */
- CREATE CLUSTERED INDEX CI_SalesOrder
- ON dbo.SalesOrder(OrderStatus)
- ;
- GO
- --Create the columnstore index with a filtered condition
- CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_SalesOrder
- ON dbo.SalesOrder (AutoID, Price, OrderQty, orderstatus)
- WHERE orderstatus = 5
- ;
- GO
为了能够直观的看到利用SQL Server 2016列存储索引实现实时分析的效果,我虚拟了一个网络汽车销售订单系统,使用NodeJs + SQL Server 2016 Columnstore Index + Socket.IO来实现实时订单销量和销售收入的分析页面。
总结
这篇文章讲解利用SQL Server 2016列存储索引技术实现数据实时分析的两种方法,以解决传统RDBMS数据分析的高延迟、高成本的痛点。***种方法是Hekaton + Clustered Columnstore Index;第二种方法是Filtered Nonclustered Columnstore Index + Clustered B-Tree。本文并以此理论为基础,展示了一个网络汽车在线销售系统的实时订单分析页面。