前言
多图预警、多图预警、多图预警。秋招季,毕业也多,跳槽也多。我们的职业发展还是要顺应市场需求,那么各门编程语言在深圳的需求怎么呢?工资待遇怎么样呢?zone 在上次写了这篇文章之后 用Python告诉你深圳房租有多高 ,想继续用 Python 分析一下,当前深圳的求职市场怎么样?顺便帮一下秋招的同学。于是便爬取了某拉钩招聘数据。以下是本次爬虫的样本数据:
样本
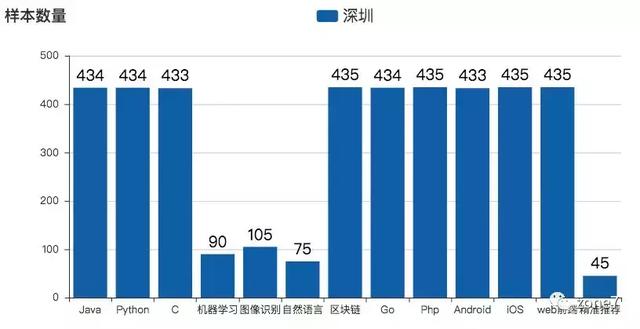
本次统计数据量为 4658 ,其中某拉钩最多能显示 30 页数据,每页 15 条招聘信息,则总为:
30 x 15 = 450
首页爬取跳过一页,则为 435 条,故数据基本爬完。其余不够数量的语言为该语言在深圳只有这么多条招聘信息。
统计结果
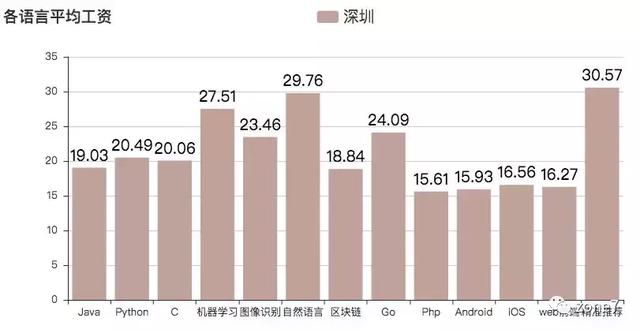
各语言平均工资
其中
- 精准推荐
- 自然语言
- 机器学习
- Go 语言
- 图像识别
独领风骚啊!!!平均工资都挺高的。区块链炒得挺火的,好像平均薪资并没有那么高。我统计完之后,感觉自己拖后腿了,ma 的!!!要删库跑路了!(注:下图为月薪,单位:K)
各语言平均薪资
平均工资计算方式:
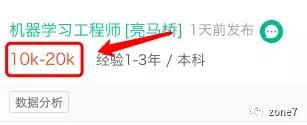
某钩 item
***值与***值,求平均数,如图薪资则为:
(10k + 20k)/2 = 15k
***,再总体求平均数。
公司福利词云
看福利还是挺丰富的,带薪休假、下午茶、零食、节假日。

福利词云
公司发展级别排行
总体由 A 轮向 D 轮缩减,大部分公司不需要融资,嗯,估计是拿不到资本融资,但是自家人又有钱的。
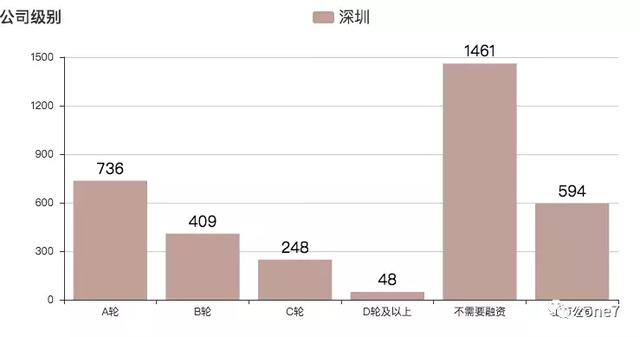
公司发展级别
各语言工作年限要求与学历要求
看看你的本命语言的市场需求怎么样?你达标了吗?其中三至五年的攻城狮职位挺多的,不怕找不到工作。还有一个趋势是,薪资越高,学历要求越高高。看来学历还是挺重要的。
Java
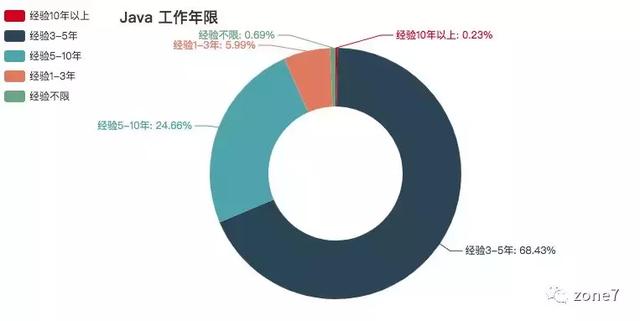
Java 工作年限要求
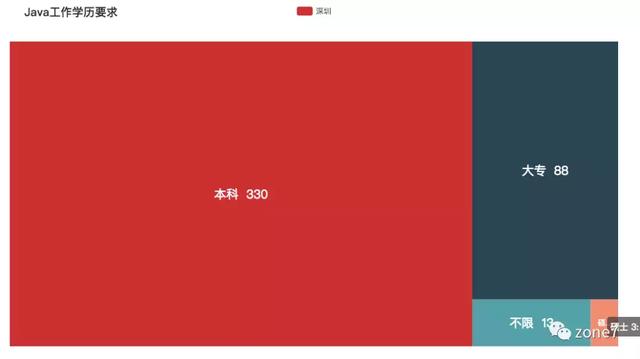
Java 学历要求
Python
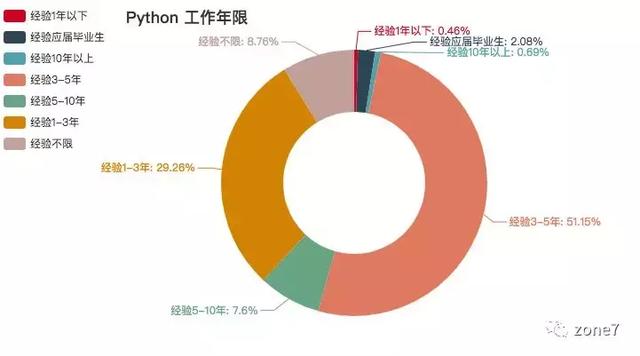
Python 工作年限要求

Python 学历要求
C 语言
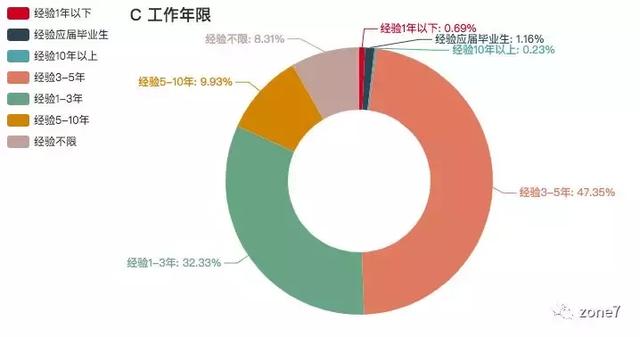
C 语言工作年限要求

C 语言学历要求
机器学习
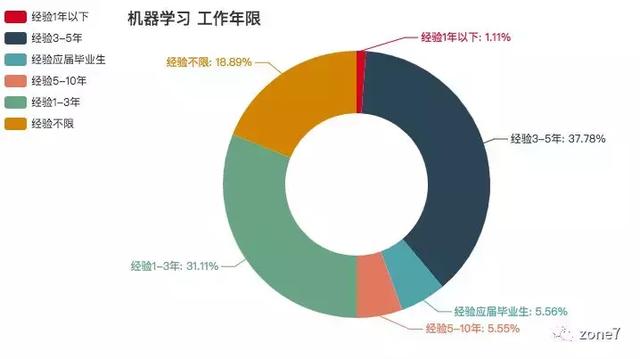
机器学习工作年限要求
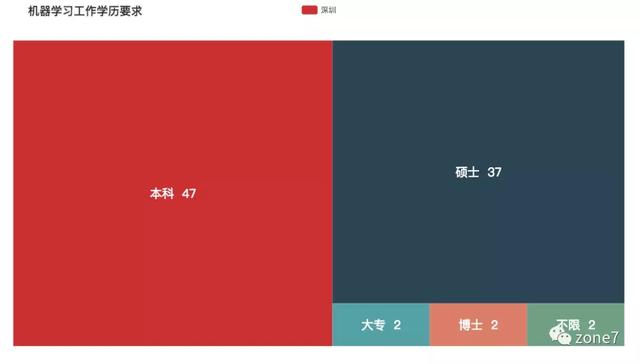
机器学习学历要求
图像识别
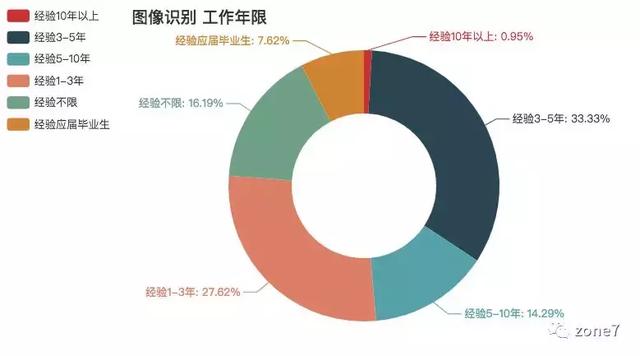
图像识别工作年限要求
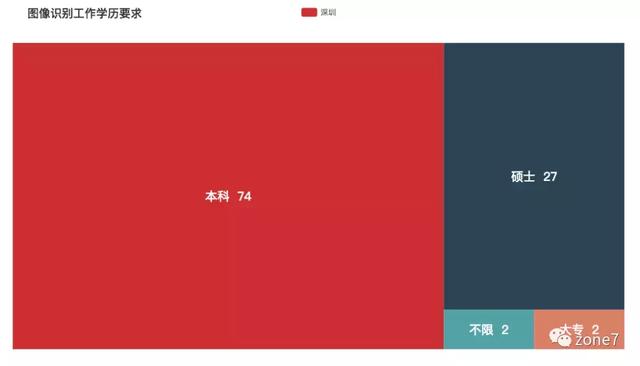
图像识别学历要求
自然语言
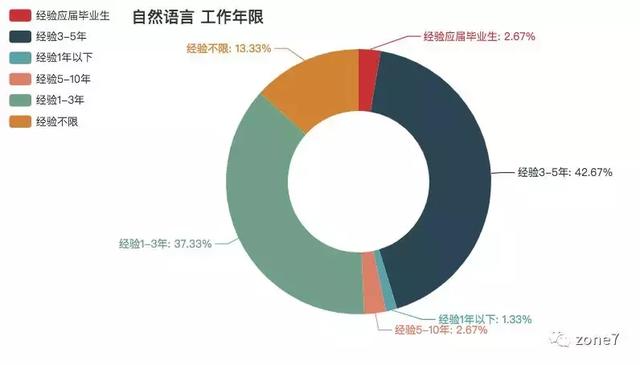
自然语言工作年限要求
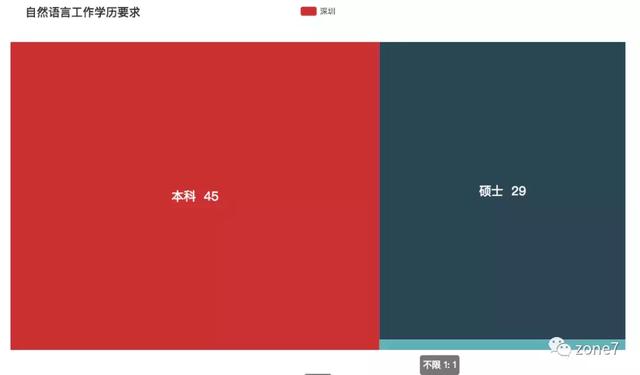
自然语言学历要求
区块链
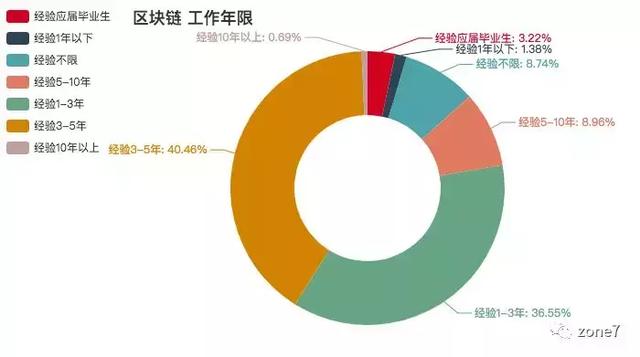
区块链工作年限要求
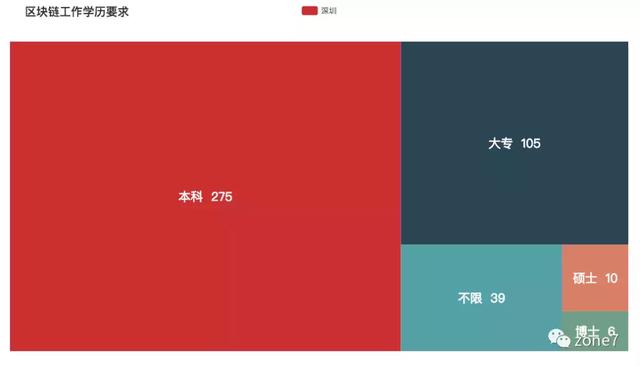
区块链学历要求
Go 语言
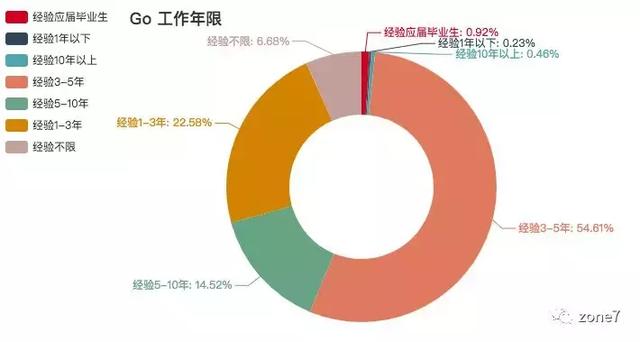
Go 语言工作年限要求

Go
PHP
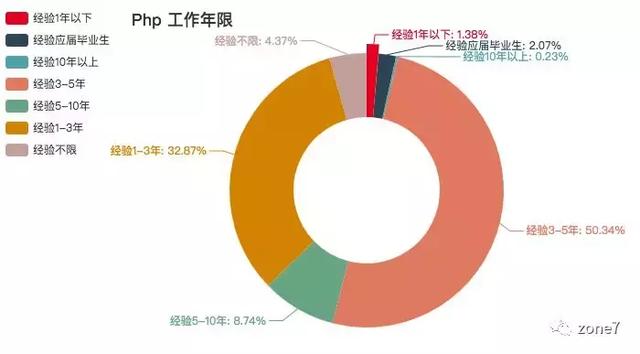
PHP 工作年限要求
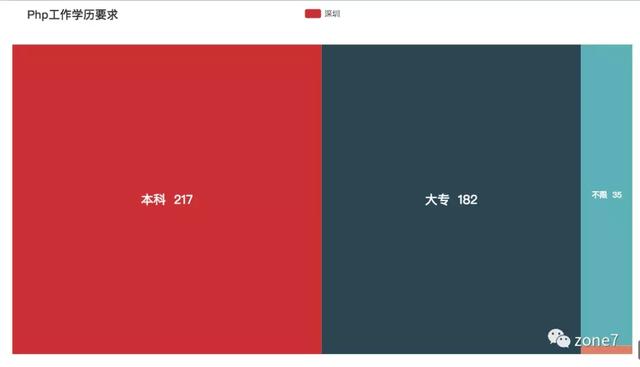
PHP 学历要求
爬虫技术分析
- 请求库:selenium
- HTML 解析:BeautifulSoup、xpath
- 词云:wordcloud
- 数据可视化:pyecharts
- 数据库:MongoDB
- 数据库连接:pymongo
爬虫代码实现
看完统计结果之后,有没有跃跃欲试?想要自己也实现以下代码?以下为代码实现。
对网页右击,点击检查,找到一条 item 的数据:
网页源码
数据库存储结构:
- /* 1 */
- {
- "_id" : ObjectId("5b8b89328ffaed60a308bacd"),
- "education" : "本科",# 学习要求
- "companySize" : "2000人以上",# 公司人数规模
- "name" : "python开发工程师",# 职位名称
- "welfare" : "“朝九晚五,公司平台大,发展机遇多,六险一金”",# 公司福利
- "salaryMid" : 12.5,# 工资上限与工资下限的平均数
- "companyType" : "移动互联网",# 公司类型
- "salaryMin" : "10",# 工资下限
- "salaryMax" : "15",# 工资上限
- "experience" : "经验3-5年",# 工作年限
- "companyLevel" : "不需要融资",# 公司级别
- "company" : "XXX技术有限公司"# 公司名称
- }
由于篇幅原因,以下只展示主要代码:
- # 获取网页源码数据
- # language => 编程语言
- # city => 城市
- # collectionType => 值:True/False True => 数据库表以编程语言命名 False => 以城市命名
- def main(self, language, city, collectionType):
- print(" 当前爬取的语言为 => " + language + " 当前爬取的城市为 => " + city)
- url = self.getUrl(language, city)
- browser = webdriver.Chrome()
- browser.get(url)
- browser.implicitly_wait(10)
- for i in range(30):
- selector = etree.HTML(browser.page_source) # 获取源码
- soup = BeautifulSoup(browser.page_source, "html.parser")
- span = soup.find("div", attrs={"class": "pager_container"}).find("span", attrs={"action": "next"})
- print(
- span) # <span action="next" class="pager_next pager_next_disabled" hidefocus="hidefocus">下一页<strong class="pager_lgthen pager_lgthen_dis"></strong></span>
- classArr = span['class']
- print(classArr) # 输出内容为 -> ['pager_next', 'pager_next_disabled']
- attr = list(classArr)[0]
- attr2 = list(classArr)[1]
- if attr2 == "pager_next_disabled":#分析发现 class 属性为 ['pager_next', 'pager_next_disabled'] 时,【下一页】按钮不可点击
- print("已经爬到***一页,爬虫结束")
- break
- else:
- print("还有下一页,爬虫继续")
- browser.find_element_by_xpath('//*[@id="order"]/li/div[4]/div[2]').click() # 点击【下一页】按钮
- time.sleep(5)
- print('第{}页抓取完毕'.format(i + 1))
- self.getItemData(selector, language, city, collectionType)# 解析 item 数据,并存进数据库
- browser.close()
爬虫分析实现
- # 获取各语言样本数量
- def getLanguageNum(self):
- analycisList = []
- for index, language in enumerate(self.getLanguage()):
- collection = self.zfdb["z_" + language]
- totalNum = collection.aggregate([{'$group': {'_id': '', 'total_num': {'$sum': 1}}}])
- totalNum2 = list(totalNum)[0]["total_num"]
- analycisList.append(totalNum2)
- return (self.getLanguage(), analycisList)
- # 获取各语言的平均工资
- def getLanguageAvgSalary(self):
- analycisList = []
- for index, language in enumerate(self.getLanguage()):
- collection = self.zfdb["z_" + language]
- totalSalary = collection.aggregate([{'$group': {'_id': '', 'total_salary': {'$sum': '$salaryMid'}}}])
- totalNum = collection.aggregate([{'$group': {'_id': '', 'total_num': {'$sum': 1}}}])
- totalNum2 = list(totalNum)[0]["total_num"]
- totalSalary2 = list(totalSalary)[0]["total_salary"]
- analycisList.append(round(totalSalary2 / totalNum2, 2))
- return (self.getLanguage(), analycisList)
- # 获取一门语言的学历要求(用于 pyecharts 的词云)
- def getEducation(self, language):
- results = self.zfdb["z_" + language].aggregate([{'$group': {'_id': '$education', 'weight': {'$sum': 1}}}])
- educationList = []
- weightList = []
- for result in results:
- educationList.append(result["_id"])
- weightList.append(result["weight"])
- # print(list(result))
- return (educationList, weightList)
- # 获取一门语言的工作年限要求(用于 pyecharts 的词云)
- def getExperience(self, language):
- results = self.zfdb["z_" + language].aggregate([{'$group': {'_id': '$experience', 'weight': {'$sum': 1}}}])
- totalAvgPriceDirList = []
- for result in results:
- totalAvgPriceDirList.append(
- {"value": result["weight"], "name": result["_id"] + " " + str(result["weight"])})
- return totalAvgPriceDirList
- # 获取 welfare 数据,用于构建福利词云
- def getWelfare(self):
- content = ''
- queryArgs = {}
- projectionFields = {'_id': False, 'welfare': True} # 用字典指定
- for language in self.getLanguage():
- collection = self.zfdb["z_" + language]
- searchRes = collection.find(queryArgs, projection=projectionFields).limit(1000)
- for result in searchRes:
- print(result["welfare"])
- content += result["welfare"]
- return content
- # 获取公司级别排行(用于条形图)
- def getAllCompanyLevel(self):
- levelList = []
- weightList = []
- newWeightList = []
- attrList = ["A轮", "B轮", "C轮", "D轮及以上", "不需要融资", "上市公司"]
- for language in self.getLanguage():
- collection = self.zfdb["z_" + language]
- # searchRes = collection.find(queryArgs, projection=projectionFields).limit(1000)
- results = collection.aggregate([{'$group': {'_id': '$companyLevel', 'weight': {'$sum': 1}}}])
- for result in results:
- levelList.append(result["_id"])
- weightList.append(result["weight"])
- for index, attr in enumerate(attrList):
- newWeight = 0
- for index2, level in enumerate(levelList):
- if attr == level:
- newWeight += weightList[index2]
- newWeightList.append(newWeight)
- return (attrList, newWeightList)