公司旧电脑到期,换了一台电脑的原因之前爬取的数据全部忘了备份,全部弄丢了。所以这个项目好久没开工了。
本文需要进一步研究知识图谱的数据存储。由于知识图谱的图结构特点,使用传统的关系型数据库存储大量的关系表,在做查询的时候需要大量的表连接,速度非常慢,所以往往知识图谱采用的是图数据库。
一、图数据库和关系型数据库的差别
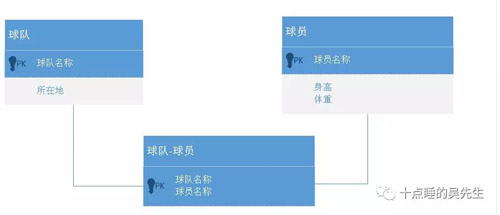
还是以NBA里的数据为例,为了表示球员和球队的效力关系,关系型数据库需要增加一张球员和球队关系表来存储这个关系。如下图:
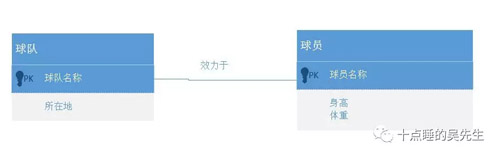
而图数据库通过引入“效力于”关系边的概念来加以解决。不需要建表,关系边上可以存储属性,比如效力时间这一字段。
工作中我们团队的知识图谱是存储在阿里自研的图数据库上,鉴于数据安全问题,在这个项目里我采用了比较流行的neo4j图数据库。
二、Neo4J的使用
neo4j的使用,主要参考了官方文档https://neo4j.com/docs/developer-manual/current/drivers/client-applications/。Neo4J设计了一种叫做Cypher的查询语言,语法非常奇怪。官方提供的一个二跳的查询例子,查询John的朋友的朋友:
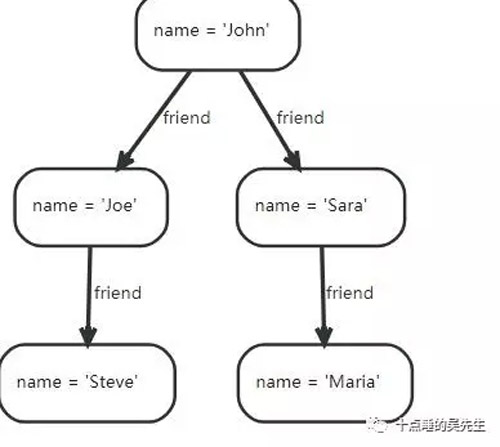
Query:
- MATCH(john{name:'John'})-[:friend]->()-[:friend]->(fof)RETURNjohn.name,fof.name
Result:
- +----------------------+
- | john.name | fof.name |
- +----------------------+
- | "John" | "Maria" |
- | "John" | "Steve" |
- +----------------------+
- 2 rows
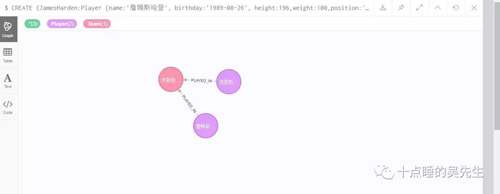
我尝试创建了一个NBA的DB,用create语句创建了NBA火箭队、保罗和哈登三个实体。创建语句如下

创建了2个球员实体,包括了身高/体重/生日/合同情况,创建了一个球队实体,包括了球馆、城市等信息,创建了两条球员和球队的关系边,每条边上定义球员在该球队效力时间。可视化结果如下图:
OK,至此一个小的知识图谱就在图数据库里被创建完毕了,后续要做的是把大规模数据导入图数据库