












JVM是JAVA平台的重要组成之一,因涉及知识点太多,故从以下几个方面对JVM进行浅层面的介绍,如果需要深入理解,推荐学习机械工业出版社的《深入理解JAVA虚拟机》。
一、JAVA内存结构
Java虚拟机规范中规定的JVM运行时数据区如下图所示:
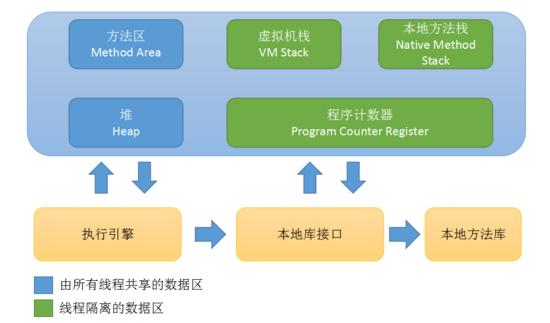
总体来说,分为线程共享部分(方法区、堆)和线程隔离区(虚拟机栈、本地方法栈和程序计数器)。
1.方法区
用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。其中常量存储于运行时常量区中,运行时常量区是区的一部分,用于存储编译期生成的字面量和符号引用。但运行时常量区的内容并不只是在编译期间产生,通过String.intern()也可以实现在运行时向常量区中添加内容。
2.堆
是JVM中***的一块内存区域,该区域的目的只是用于存储对象实例及数组。该区域也是GC的最主要区域。
3.虚拟机栈
每个线程方法在执行时都会创建一个栈帧,包含局部变量表、返回地址、操作数栈等信息。每个方法的执行与完成就对应的栈帧的入栈与出栈过程 。局部变量表占用空间的大小在编译期就确定了。
4.本地方法栈
与虚拟机栈类似,不过其中执行是本地方法。对于HotSpot虚拟机而言,本地方法栈和虚拟机栈是统一的。
5.程序计数器
是一个小的内存空间,如果线程正在执行的是一个java方法,则此内存区域记录正在执行的虚拟机字节码指令;如果线程正在执行的是native方法,则计算器中的值为空。
二、JAVA垃圾回收机制
JAVA的垃圾回收主要涉及到确定对象是否存活、垃圾收集等算法,其中确定对象回收算法采用的是可达性分析算法,垃圾收集目前各JVM厂商广泛采用的是分代收集算法。这里面主要描述下分代收集算法的过程。
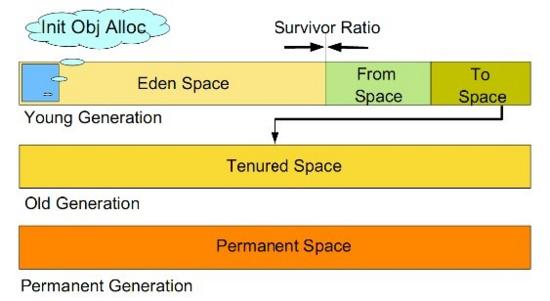
分代收集算法的核心思想是将内存区域按照对象的生存周期阶段进行划分,其中将堆区划分为新生代(young generation)和老年代(old generation)。将非堆区(一般指方法区)划分为持久代(permanent generation)。
1.新生代
新生代又可再分为Eden区和两个Survivor区(两个Survivor区的大小是一样的,便于交换)。新生成的对象都会先在新生代的Eden区进行保存。新生代的特点是每次垃圾回收都会有大量的内存被回收,而且收集比较频繁,所以新生代适合如下的收集算法:
首先,新生成的对象分配到Eden区,如果eden区满了,则将可达性的对象复制到survivor1区,后清空eden区。
然后,如果survivor1区满了,则将eden区与survivor1区的可达性对象复制到survivor2区,后清空eden区和survivor1区,清空完后将survivor2区与survivor1区交换,即保持survivor2是空的。
再次,如果survivor2区也满了,则将eden区、survivor1区、survivor2区的可达性对象复制到老年代中,并清空新生代中。
***,如果老年代也满了,就触发full gc了。
2.老年代
老年代的内存比新生代大的多,这个区域执行垃圾回收的频度不高。当老年代满时,会触发full gc。
3.持久代
持久代一般指方法区,该区需要回收的有废弃的常量和类。对于常量可用可达性分析的方法进行判断回收,对于类则需要同时满足以下条件才会被回收:
首先,该类的所有实例对象都已被回收;
其次,该类的类加载器也已被回收;
再次,该类的Class方法没有在任何地方被引用,即无法通过在任何地方通过反射访问到该类的方法。
4.什么时候会解决垃圾回收?
综上所述,当eden满时,就会触发scavenge gc,当出现以下情况时会触发full gc:
老年代已满;
持久代已满;
调用System.gc()方法;
三、JAVA类加载过程
JVM类加载过程具体装载、验证、准备、解析、初始化这五个部分。
1.装载
在装载过程中,需要完成以下事情:
1)通过类的全限定名获取类的二进制字节流;
2)将类的二进制字节流转换为方法区的运行时数据结构;
3)生成一个代表此类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
2.验证
验证、解析和初始化又称为是连接阶段,在验证验证主要是确保二进制字节流符合JVM的规范,不会危害计算机的安全。具体验证阶段需要做的事情如下:
1)文件格式验证,验证字节流是否符合Class文件格式规范;
2)元数据验证,对字节码进行语义验证,以保证其描述信息符合JAVA语言规范;
3)字节码验证,通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的;
4)符号引用验证,对常量池中的各种符号引用的信息进行匹配性验证。
3.准备
准备的过程其实是分配内存的过程。在这个阶段有两个容易产生混淆的概念:一是此阶段分配内存的只是类变量(static变量),不包含实例变量,实例变量的内存分配是在对象实例化时随对象一起分配在堆中;二是该阶段分配内存中保存的值只是数据类型的零值,具体值需要在初始化阶段进行赋值。也有特殊情况,就是对于静态常量(final修饰)会在准备阶段将值赋值为真实值。
4.解析
解析阶段就是将常量池内折符号引用转换为直接引用的过程,具体包括类和接口的解析、字段的解析、方法的解析、接口方法和解析。
5.初始化
初始化阶段其实就是执行类构造函数(clinit)的阶段。对于clinit()需要说明以下几点:
1)clinit()中的程序是自动收集类中static变量及static块产生的,执行顺序与代码中的顺序一致。静态语句块中只能访问在其之前声明的static变量,在其之后声明的static变量只能赋值,不能访问。
2)执行clinit()方法前,JVM会自动调用父类的clinit()方法;
3)虚拟机会保证一个类的clinit()在多线程环境中,自动加锁、同步。
四、JVM的类加载器
JVM的类加载是通过类加载器实现的,常用的类加载器包括下面三种:
1.启动类加载器(bootstrap classloader):加载{JDK_HOME}/lib下的类
2.扩展类加载器(extension classloader):加载{JDK_HOME}/lib/ext下的类
3.应用程序类加载器(application classloader):加载classpath指定的类
对于不同类加载器以及他们之间的协作可以参考下面的双亲委派模型。
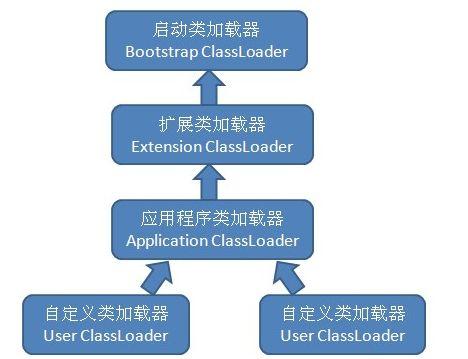
双亲委派模型的工作过程是:如果一个类加载器收到了类的加载请求,会首先把请求委派给自己的父类,每个层次的类加载器都会如此,因为所有的加载请求最终都会发送到bootstarp加载器中,只有当父加载器确实无法自己完成加载请求时,子加载器才会尝试自己加载。
双亲委派模型使得JAVA类能够按层次进行加载,不会造成混乱。
五、JVM的相关工具
JDK中有很多强大的监控工具,可以直接在命令行运行。这对于在生产环境进行监控是非常有用的。例如SUN JDK中就包含了以下监控和故障处理工具。
jps: jvm process status tool,显示指定系统内所有的hotspot虚拟机进程
jstat: jvm statistics monitoring tool,用于收集hotspot虚拟机各方面的运行数据
jinfo: configuration info for java,显示虚拟机配置信息
jmap: memory map for java,生成虚拟机的内存转储快照(heapdump文件)
jhat: jvm heap dump browser,用于分析heapmap文件,它会建立一个http/html服务器,让用户可以在浏览器上查看分析结果
jstack: stack trace for java ,显示虚拟机的线程快照



























