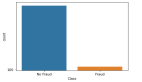
在学术研究与教学中,很多算法都有一个基本假设,那就是数据分布是均匀的。当我们把这些算法直接应用于实际数据时,大多数情况下都无法取得理想的结果。因为实际数据往往分布得很不均匀,都会存在“长尾现象”,也就是数据不平衡”。
以下几种方法是针对数据不平衡问题所做的处理,具体包括:
- smote采样
- adasyn采样
- 欠采样
- 一分类
- 改进的adaboost方法
一、smote采样
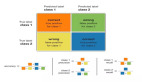
SMOTE全称是Synthetic Minority Oversampling Technique即合成少数类过采样技术,它是基于随机过采样算法的一种改进方案,由于随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题,即使得模型学习到的信息过于特别(Specific)而不够泛化(General),SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,算法流程如下。
- 对于少数类中每一个样本x,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
- 根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本x,从其k近邻中随机选择若干个样本,假设选择的近邻为xn。
- 对于每一个随机选出的近邻xn,分别与原样本按照如下的公式构建新的样本 xnew=x+rand(0,1)∗|x−xn|
部分代码如下:
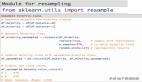
- df=get_data()
- x, y = load_creditcard_data(df)
- X_resampled_smote, y_resampled_smote = SMOTE().fit_sample(x, y) # print(y_resampled_smote)
- X_train, X_test, y_train, y_test = train_test_split(X_resampled_smote, y_resampled_smote, test_size=0.3,random_state=0)
二、adasyn采样
本文介绍的是 ADASYN: 自适应综合过采样方法。
算法步骤如下:
(1)计算不平衡度
记少数类样本为ms,多数类为ml,则不平衡度为 d = ms / ml,则d∈(0,1]。(作者在这里右边用了闭区间,我觉得应该用开区间,若是d = 1,则少数类与多数类样本数量一致,此时数据应该平衡的)
(2)计算需要合成的样本数量
G = (ml - ms)* b,b∈[0,1],当b = 1时,即G等于少数类和多数类的差值,此时合成数据后的多数类个数和少数类数据正好平衡
(3)对每个属于少数类的样本用欧式距离计算k个邻居,为k个邻居中属于多数类的样本数目,记比例r为r = / k,r∈[0,1]
(4)在(3)中得到每一个少数类样本的 ri ,
用 计算每个少数类样本的周围多数类的情况
(5)对每个少数类样本计算合成样本的数目 (6)在每个待合成的少数类样本周围k个邻居中选择1个少数类样本,根据下列等式进行合成
重复合成直到满足需要步骤(5)合成的数目为止。
部分代码如下:
- df=get_data()
- x, y = load_creditcard_data(df)
- X_resampled_smote, y_resampled_smote = ADASYN().fit_sample(x, y)
三、欠采样
以下两种方法都属于欠抽样,不同于直接欠抽样,他们将信息的丢失程度尽量降低。两者的核心思想为:
1. EasyEnsemble 核心思想是:
- 首先通过从多数类中独立随机抽取出若干子集
- 将每个子集与少数类数据联合起来训练生成多个基分类器
- 最终将这些基分类器组合形成一个集成学习系统
EasyEnsemble 算法被认为是非监督学习算法,因此它每次都独立利用可放回随机抽样机制来提取多数类样本
2. BalanceCascade 核心思想是:
- 使用之前已形成的集成分类器来为下一次训练选择多类样本
- 然后再进行欠抽样
四、一分类
对于正负样本极不平衡的场景,我们可以换一个完全不同的角度来看待问题:把它看做一分类(One Class Learning)或异常检测(Novelty Detection)问题。这类方法的重点不在于捕捉类间的差别,而是为其中一类进行建模,经典的工作包括One-class SVM等。
我们只对一类进行训练,模型的结果会聚集在某个范围内,测试集进行测试,则模型的输出结果为1和-1两种,当落在这个区间,结果为1,不在这个区间,则结果为-1
部分代码如下:
- def MechanicalRupture_Model():
- train = pd.read_excel(normal)
- test = pd.read_excel(unnormal)
- clf = svm.OneClassSVM(nu=0.1, kernel=rbf, gamma=0.1)
- clf.fit(train)
- y_pred_train = clf.predict(train)
- y_pred_test = clf.predict(test)
五、改进的adaboost方法
AdaCost算法修改了Adaboost算法的权重更新策略,其基本思想是对于代价高的误分类样本大大地提高其权重,而对于代价高的正确分类样 本适当地降低其权重,使其权重降低相对较小。总体思想是代价高样本权重增加得大降低得慢。
具体adacost代码如下:
- #!/usr/bin/env python3# -*- coding:utf-8 -*-import numpy as npfrom numpy.core.umath_tests import inner1dfrom sklearn.ensemble import AdaBoostClassifierclass AdaCostClassifier(AdaBoostClassifier):#继承AdaBoostClassifier
- def _boost_real(self, iboost, X, y, sample_weight, random_state):
- implement a single boost using the SAMME.R real algorithm.
- :param iboost:
- :param X:
- :param random_state:
- :param y:
- :return:sample_weight,estimator_error
- estimator = self._make_estimator(random_state=random_state)
- estimator.fit(X, y, sample_weight=sample_weight)
- y_predict_proba = estimator.predict_proba(X) if iboost == 0:
- self.classes_ = getattr(estimator, 'classes_', None)
- self.n_classes_ = len(self.classes_)
- y_predict = self.classes_.take(np.argmax(y_predict_proba, axis=1),axis=0)
- incorrect = y_predict != y
- estimator_error = np.mean(np.average(incorrect, weights=sample_weight, axis=0)) if estimator_error = 0: return sample_weight, 1., 0.
- n_classes = self.n_classes_
- classes = self.classes_
- y_codes = np.array([-1. / (n_classes - 1), 1.])
- y_coding = y_codes.take(classes == y[:, np.newaxis])
- proba = y_predict_proba # alias for readability
- proba[proba np.finfo(proba.dtype).eps] = np.finfo(proba.dtype).eps
- estimator_weight = (-1. * self.learning_rate * (((n_classes - 1.) / n_classes) *
- inner1d(y_coding, np.log(y_predict_proba)))) # 样本更新的公式,只需要改写这里
- if not iboost == self.n_estimators - 1:
- sample_weight *= np.exp(estimator_weight *
- ((sample_weight 0) |
- (estimator_weight 0)) *
- self._beta(y, y_predict)) # 在原来的基础上乘以self._beta(y, y_predict),即代价调整函数
- return sample_weight, 1., estimator_error def _beta(self, y, y_hat):
- adjust cost function weight
- :param y:
- :param y_hat:
- :return:res
- res = [] for i in zip(y, y_hat): if i[0] == i[1]:
- res.append(1) # 正确分类,系数保持不变,按原来的比例减少
- elif i[0] == 0 and i[1] == 1: # elif i[0] == 1 and i[1] == -1:
- res.append(1) # 将负样本误判为正样本代价应该更大一些,比原来的增加比例要高
- elif i[0] == 1 and i[1] == 0: # elif i[0] == -1 and i[1] == 1:
- res.append(1.25) # 将正列判为负列,代价不变,按原来的比例增加
- else: print(i[0], i[1]) return np.array(res)
总结:
其中
smote采样 、adasyn采样、欠采样、一分类是针对数据集做出处理。
改进的adaboost方法是对模型方法进行的改进。
具体采用哪种方式,需要结合具体情况。