












在任何快速发展的话题上,总是有一些新的东西可以学习,机器学习也不例外。这篇文章将指出5件关于机器学习的事,5件你可能不知道的,可能没有意识到,或是可能曾经知道,现在被遗忘了。
请注意,这篇文章的标题不是关于机器学习的"最重要的5件事情"或"前5件事";这只是"5件事"。它不具有权威性的,也并不是事无巨细的,仅仅是5件可能有用的东西的集合。
1.数据准备是机器学习的80%,所以……
在机器学习任务中,数据准备花费了很大一部分的时间;或者,至少花费了一个看似很大一部分的时间。许多人都是这样认为的。
我们经常讨论执行数据准备时的细节以及其重要性的原因;但除了这些之外,我们还应该关注到更多的东西。那就是为什么我们应该关心数据准备。我的意思不是仅仅为了得到一致性的数据,但更像一个哲学性的谩骂,以便让你明白为什么应该接受数据准备。做好数据准备工作,做一个有数据准备的人。
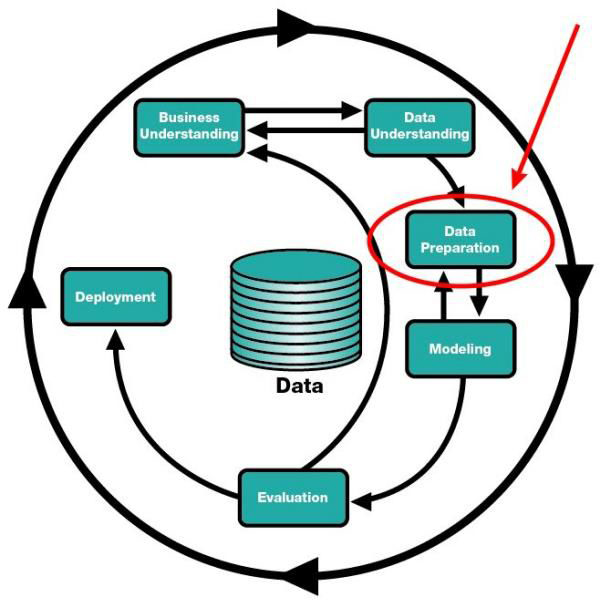
CRISP-DM模型中的数据准备。
我可以想到的一些关于机器学习最好的建议就是,既然你注定要为一个大项目花非常多的时间准备数据,那么决心做一名最好的数据准备的专业人士,是一个相当好的目标。因为它不仅仅只是费时费力的工作,数据准备其实对对后续的步骤(无效数据的输入、无效数据的输出等)有很大的重要性,并且因为作为一个糟糕的数据准备人员而产生坏名声也不会是世界上最糟糕的事情。
所以,是的,虽然数据准备可能需要一段时间来执行和掌握,但这真的不是一件坏事。在数据准备存在的必要性中有着很多机会,无论是对一名脱颖而出的专业人士,还是展现你工作能力很强的内在价值。
2.性能基线的值
当你用一个特定的算法模拟了一些数据,并且花了很多时间来调整你的超参数,执行一些工程特点和/或着挑选;你很高兴,因为你已经钻研出了如何训练准确性,比方说,准确性是75%。你对自己完成的工作十分满意。
但是,你将你得到的结果与什么进行了比较?如果你没有基线——一个比拇指规则都简单的完整检查来比较你的数据——然后你实际上并没有把那些辛勤劳动的结果与任何东西进行比较。所以就有理由理所当然的认为任何准确性在没有与其他数据比较时都是有价值的了么?显然不是。
随机猜测不是基线的最佳方案;相反,的确存在广为接受的用于确定比较基准精度的方法。例如,Scikit-learn在其DummyClassifier的分类中提供了一系列基线分类器:
- stratified 通过尊重训练集类分布来生成随机预测。
- most_frequent总是预测训练集中最频繁的标签。
- prior总是预测最大化优先级的类(像most_frequent')和"predict_proba返回类的优先级。
- uniform随机生成预测。
- constant总是预测用户提供的常量标签。
基线也不仅是分类器;例如,基线回归任务中也存在统计方法。在探索性数据分析、数据准备和预处理之后,建立基线是机器学习工作流程中的一个合乎逻辑的下一步。
3.验证:不止于训练和测试
当我们建立机器学习模型时,我们训练他们使用训练数据。当我们测试结果模型时,我们使用测试数据。那么验证是在哪里出现的呢?
fast.ai的Rachel Thomas最近写了一篇关于如何以及为什么创建良好的验证集的文章,并介绍了以下3类数据:
- 用于训练给定模型的训练集
- 用于在模型之间进行选择的验证集
(例如,随机森林和神经网络哪个更好地解决了您的问题?你想要一个有40棵或者50棵树的随机森林吗?)
- 告诉您您的工作方式的测试集。如果你尝试了很多不同的模型,你可能会得到一个很好的验证集,但这只是偶然的,因为总有一个测试集不属于这样的情况。

因此,将数据随机拆分为测试、训练和验证集一定是个好主意吗?事实证明,答案是否定的。雷切尔在时间序列数据的文中解答了此问题:Kaggle目前正努力解决预测厄瓜多尔杂货店销售量的预测问题。Kaggle的"训练数据"从2013年1月1日运行到2017年8月15日,测试数据跨越了2017年8月16日到2017年8月31日。使用2017年8月1日到8月15日作为您的验证集不失为一种好的方法,并且所有早期的数据也可以作为您的训练集。
这篇文章的其余部分将涉及到分裂到Kaggle竞争数据的数据集,这是十分实用的;并且我将会把交叉验证纳入讨论,读者可以按照我的方法自行探究。
其他许多时候,数据的随机分割会是有用的;它取决于进一步的因素,如当你得到数据时数据的状态,(它是否已被分为训练/测试数据?),以及它是什么类型的数据(见上面的时间序列分类)。
对于什么条件下随机拆分是可行的,Scikit可能没有train_validate_test_split的方法,但您可以利用标准的Python库来创建您自己的方法。
4.集成方法可比树还要多
选择算法对于机器学习新手来说可能是一个挑战。在构建分类器时,特别是对于初学者来说,通常采用一种方法来解决单个算法的单实例问题。然而,在给定的情况下,把分类器串联或是组合起来会更加有效;这种方式使用了投票、加权、和组合的技术,以追求最准确的分类器。集成学习就是用多种方式来提供此功能的分类器。
随机森林是集合学习者的一个非常重要的例子,它在一个预测模型中使用许多个决策树。随机森林已成功地应用于各种问题,并据此取得了很好的效果。但它们不是唯一存在的集成方法,许多其他的也值得一试。
关于套袋操作的简单概念:建立多个模型,观察这些模型的结果,并解决大多数的结果。我最近有一个关于我的车后桥总成的问题:我没有采取诊断问题的经销商的建议,并且我把它带到其他两个修车的地方,这两个都认为这个问题是和经销商所提出的不同问题。这就说明,套袋在实际生活中的运用。随机森林就是基于套袋技术所改进的。
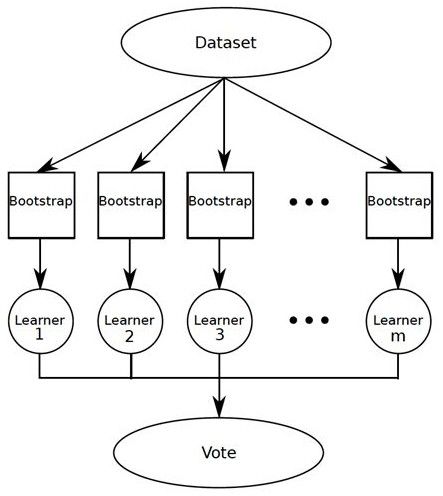
加速类似于套袋,但有一个概念上的略微不同。它不是将相等的权重分配给模型,而是增加了对分类器的权重分配,并导出了基于加权投票的最终结果。再以我的汽车问题为例,也许我过去曾多次去过一个修车行,并且比其他人更信任他们的诊断。同时假设我之前并没有和经销商有过互动或打过交道,并且相比较而言我更不相信他们的能力。我分配的重量将是反射性的。
堆叠与前两个技术有所不同,因为它训练多个单一分类器,而不是各种相同的学习者的集合。虽然套袋和加速使用了许多建立的模型,使用了相同的分类算法的不同实例(如决策树),但堆叠建立模型也使用了不同的分类算法(比如决策树,逻辑回归,一个ANNs或其他的组合)。
然后,通过对其他算法的预测,对合并算法进行训练,以得到最终的预测。这种组合可以是任何集成技术,但逻辑回归往往被认为是一个来执行这一组合最充分和最简单的算法。随着分类的进行,堆叠也可以在非监督学习任务(如密度估计)中使用。
5.谷歌Colab?
最后,让我们来看看一些更实用的东西。Jupyter Notebook事实上已成为数据科学开发最实用的工具,大多数人都在个人电脑,或者通过一些其他配置——比较复杂的方法(如在Docker容器或虚拟机中) 运行该软件。首先第一个受到关注的就是谷歌的Colaboratory,它允许Jupyter风格和兼容的Notebook直接运行在您的Google驱动器中,不需要任何配置。
Colaboratory是预先配置了一些近期较为流行的Python库,并通过支持的打包管理,使其可以把自己安装在Notebooks中。例如,TensorFlow就属于这一类,但Keras不是;但通过pip安装Keras仅需要几秒钟的时间。
在这一问题上的好消息就是,如果你使用的是神经网络,你可以在你的训练中启用GPU硬件加速,开启一次就可以享受长达12小时的免费服务。这个好消息其实并没有它一开始看起来那么完美,但这也算是一个额外的好处,也是一个全民化GPU加速的良好开端。
















