本文介绍了如何利用隐藏表示可视化来更加直观地理解神经网络训练过程。本文使用的工具是 Neural Embedding Animator,大家可以利用该工具更好地理解模型行为、理解训练过程中数据表示的变化、对比模型、了解此词嵌入的变化。
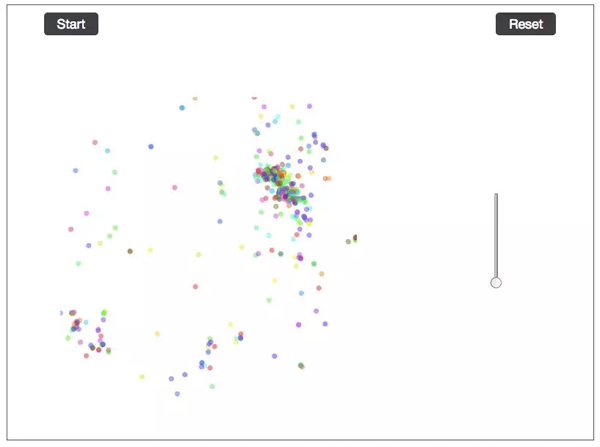
词嵌入的交互式可视化
将神经网络可视化是非常有趣的。对于监督学习而言,神经网络的训练过程可以看做是学习如何将一组输入数据点转换为可由线性分类器进行分类的表示。本文我想利用这些(隐藏)表示进行可视化,从而更加直观地了解训练过程。这种可视化可以为神经网络的性能提供有趣的见解。
我联想到很多想法,最终从 Andrej Karpathy 的研究(t-SNE visualization of CNN codes)中获得了理论支持。
这个想法很简单,可以由以下步骤简单说明:
- 训练一个神经网络。
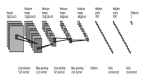
- 一旦经过训练,网络可为验证/测试数据中的每个数据点生成最终的隐藏表示 (嵌入)。这个隐藏表示基本上就是神经网络中***一层的权重。该表示近似于神经网络对数据的分类。
- 为便于可视化,需要将权重降维到二维或三维。然后,在散点图上可视化这些点以观察它们是如何在空间中分离的。有一些比较流行的降维技术,如 T-SNE 或 UMAP。
尽管上述步骤是对训练完成后的数据点进行可视化,但我认为可以实现一个有趣的拓展,即在训练过程中在多个时间点进行可视化。这样我们就可以单独观察每一个可视化,对事物如何变化产生一些见解。例如,我们可以在每一个 epoch 后进行可视化直到训练完成,然后对它们进行对比。它的进一步扩展是生成可视化动画。这可以通过这些静态可视化图和它们之间的插入控制点来实现——从而实现逐点转换。
这个想法让我很兴奋。为了生成这些可视化,我开发了基于 D3.js 的 Javascript 工具。它能产生静态可视化图和动图。对于动态图,我们需要上传两个我们想要进行对比的 csv 文件,这些文件包含隐藏表示。该工具能使文件中的点动起来。我们也可以控制动画,以便观察一组特定的点在训练过程中的移动轨迹。本文开头有一个例子,读者可以去试一下。
- 工具(Neural Embedding Animator)地址:https://bl.ocks.org/rakeshchada/raw/43532fc344082fc1c5d4530110817306/
- README:https://bl.ocks.org/rakeshchada/43532fc344082fc1c5d4530110817306
这绝对不是个复杂的工具。我只是想把我的设想付诸实践。
但是,该动画方法有一个问题:在 T-SNE/UMAP 完成后,每个 2D/3D 表示存在不一致性。首先,设置超参数和随机种子的时候要格外小心。其次,据我所知,T-SNE 只是尝试以这种方式嵌入:使相似的对象靠近,而不同的对象远离。所以当我们基于两个可视化图制作动画时,比如 epoch1 和 2,我们可能很难区分由纯粹随机性引起的运动和神经网络实际学习过程中的权重变化。也就是说,在我的实验中,我有时能够创作出合理的动画,帮助我得到一些有趣的结论。
动图一览:
这个可视化框架有很多有趣的应用。以下是分类问题的一些例子:
- 更好地了解关于数据的模型行为
- 理解神经网络训练过程中数据表示的变化
- 在给定数据集上对比模型——包括超参数更改,甚至架构更改
- 了解训练过程中词嵌入的变化(当调整时)
下文将用具体的实际例子对上述情况进行说明。
一、更好地理解关于数据的模型行为
1. 恶意评论分类任务
我们在这里使用的***个例子是 Kaggle 的一项有趣的自然语言处理竞赛:恶意评论分类,当时我正在开发这个工具。该竞赛的目标是将文本评论分为不同类别:toxic、obscene、threat、insult 等。这是一个多标签分类问题。
在神经网络模型中,我尝试了几种架构,从最简单的(没有卷积/循环的前馈神经网络)到更复杂的架构。我在神经网络的***一层使用了二进制交叉熵损失和 sigmoid 激活函数。这样,它只为每个标签输出两个概率,从而实现多标签分类。为得到演示结果,我们使用来自双向 LSTM 的隐藏表示,该 LSTM 使用未调优的预训练词嵌入进行初始化。
所以我采取了上述相同的步骤,从***一层提取验证集中每个文本评论的隐藏表示,执行 T-SNE/UMAP 操作将它们降维到 2 维,并使用该工具进行可视化。在早停之前,训练进行了 5 个 epoch。使用 UMAP 的一个优点是它的速度提高了一个数量级,并且仍能有高质量的表现。谷歌最近发布了实时 TSNE,但我还没去研究。
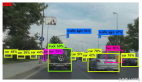
这是第 5 个 epoch 结束时可视化的放大版本。接受可视化的类别是 insult,所以红点是_insult_s,绿点是_non-insult_s。

让我们看一下上图蓝色箭头指向的两个点。其中一个是 insult,另一个不是。那文本说的什么意思呢?
- Text1(带蓝箭头的绿点):「废话废话废话废话废话废话」
- Text2(带蓝箭头的红点):「我讨厌你我讨厌你我讨厌你我讨厌你我讨厌你我讨厌你」
有趣的是,模型怎么将两个重复的文本放在一起的呢?而且这里 insult 的意味似乎比较微弱!
我也很好奇红色点簇中心的一些绿点。为什么模型会分不清它们?他们的文本是什么样的?例如,这是上图中黑色箭头指向的点的文本:
「不要喊我麻烦制造者,你和 XYZ 一样是种族主义右翼」(我对原文进行了一些稍微改动,包括名称代指)。
嗯,这似乎是 insult——所以它算一个错误的标签!这里应该是一个红点!
可能并非所有被错误放置的点都是错误标签,但按照上述步骤通过可视化进行深入挖掘,可能会发现数据的所有特征。
我也认为这有助于我们揭示分词/预处理等操作对模型性能的影响。在上面的 Text2 中,标点符号正确(可能是在每次「我讨厌你」之后用一个句号)可能对模型有所帮助。还有其他一些例子,我认为大写可能有所帮助。
2. Yelp 评论情感分类任务
我还想在不同的数据集上尝试这种方法。所以我选择了 Kaggle 的 Yelp 评论数据(https://www.kaggle.com/yelp-dataset/yelp-dataset),并决定实现一个简单的情感分类器。我将***评分转换为二进制——这样更容易操作。所以 -1、2 和 3 星是消极的,4 星、5 星是积极的评论。同样,我用一个简单的前馈神经网络架构处理嵌入,压缩嵌入,然后输入全连接层并输出概率。这是 NLP 分类任务的非常规架构,但我很想知道它是如何做的。在早停之前,训练进行 10 个 epoch。
这是***一个 epoch 结束时的可视化内容:
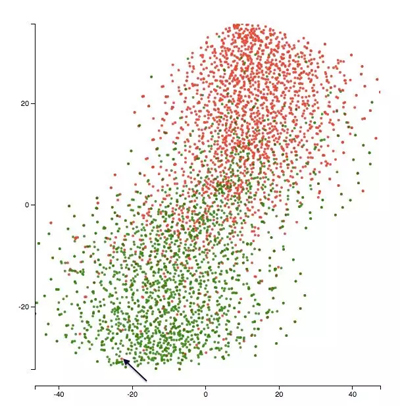
黑色箭头所指的点的文本是:
「每次去这里,食物都很美味。不幸的是服务不太好(not very good),我只为我喜欢的食物而来。」
这是个中立的评论,可能更倾向于积极的一面。因此,对于模型而言,将这一点放在积极的点簇中还算差强人意。此外,这个模型单独处理单词(没有 n-gram),这解释了漏掉上面文本「not very good」中的「not」这类现象。以下是与上图消极点最接近的积极点的文本。
「喜欢这个地方。虽然基本菜单就是拉面,但味道很好,而且服务很好。价格合理,氛围优美。绝对是 neighborhood gem。」
模型将上面的两个文本置于空间中非常接近的位置,这可能再次证实了该模型的局限性(诸如不捕捉 n-gram)。
我有时会想,这样的分析可以帮助我们理解哪个例子对模型来说是「难」或者「简单」。这可以通过观察相邻的被错误分类的点来理解。一旦我们理解这些,就可以利用这些知识来增加更多的人工提取特征以帮助模型更好地理解这些示例,或者更改模型的架构,以便更好地理解那些「难」的示例。
二、理解神经网络训练过程中数据表示的变化
我们将使用动画来理解这一点。我理解动画可视化的方式通常是选择一个点的子集,并观察其邻域在训练过程中如何发生变化。当神经网络学习时,该邻域在分类任务中越来越有代表性。换句话说,如果我们定义分类任务的相似性,那么当网络学习时,相似的点将在空间中更加接近。前面提到的 Neural Embedding Animator 工具中的滑块可以帮助我们控制动画,并持续关注这一组点。
下图是一个动画,展示了数据的隐藏表示在用于恶意评论分类任务的 4 个 epoch 中的演化过程(第 2 个 epoch 到第 5 个 epoch)。我选择了一小组点,以便更容易地观察它们的移动过程。绿点代表无恶意,红点代表恶意类别。
有一些成对的点移动时相距范围变化较大(F 和 G 或 C 和 I),也有一些点始终接近(D 和 K 或 N 和 O)。
因此,当我手动查看与这些点相对应的句子时,我可以了解到当前 epoch 的神经网络可能学到了什么。如果我看到两个完全不相关的句子挨在一起(例如,epoch2 中的 E 和 F),那么我会认为模型仍需学习。有时我也会看到神经网络将相似的句子放在一起,而整个句子的含义并不同。随着训练的进行(验证损失减少),这种影响会逐渐消失。
正如文章开头所说,这种行为并不能保证一致性。有时候一个(些)点的邻域根本没有任何意义。但我确实希望,通过制作这些动画,观察点运动轨迹的显著变化,我们能够得出一些有用的见解。
我还使用 yelp 数据集重复了相同的实验,并有相同发现。
以下是该神经网络在经过一个 epoch 的训练后的结果:
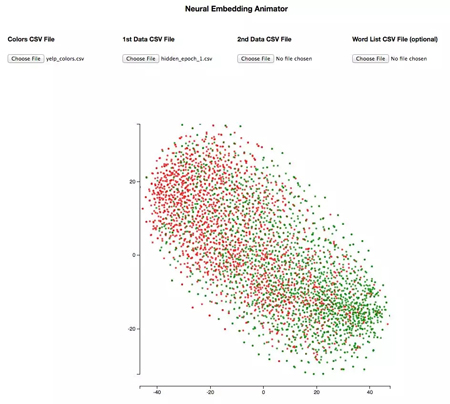
这两个类之间有很多重叠,网络没有真正学习到类别间的清晰边界。
以下是经过 5 个 epoch 的训练后的表示演变动画:
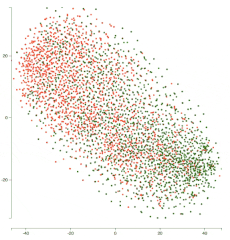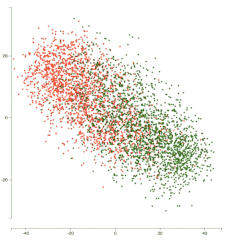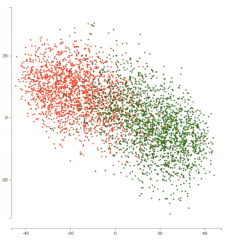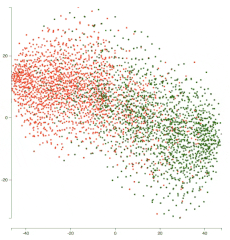
你可以看到两个簇在各自的类上变得更密集,并且网络在分离这两个类方面做得更好。
注:我正在为这些 epoch 间的表示变化制作动画。所有人都应该更加细化这些内容——比如 mini-batch 或 half-epoch 或者其他。这可能有助于发现更细微的变化。
三、模型对比
这做起来非常直观。我们只需在想要对比的模型的***一个 epoch 结束时选择表示,并将它们插入到工具即可。
这里我比较的两个模型是简单的前馈神经网络(没有卷积或循环)和双向 LSTM。它们都使用预训练的词嵌入进行初始化。
因此,对于恶意评论分类挑战,以及 obscene 类,下图展示了模型之间的表示变化。
所有红点代表 obscene 类,绿点代表非 non-obscene 类。
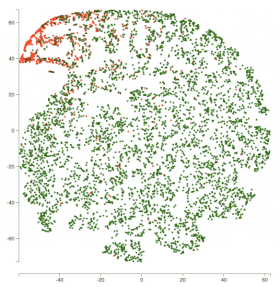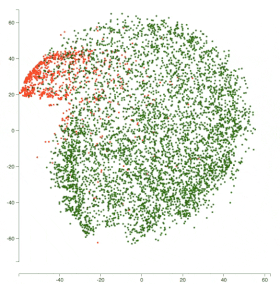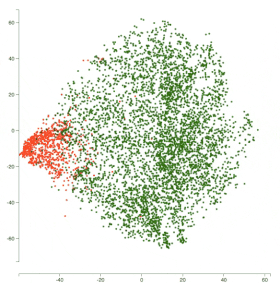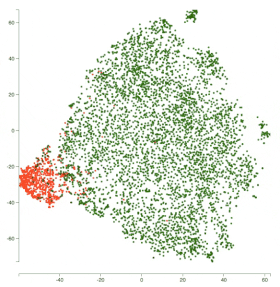
你可以看到,BiLSTM 在分离两个类别方面表现更好。
四、词嵌入可视化
我喜欢词嵌入,在任何 NLP 相关的分析中都会尝试词嵌入。这个框架应该特别适合词嵌入。那么让我们看看可以用它来理解什么吧。
这是一个示例动画,说明在 yelp 任务上调整模型时词嵌入的变化。它们用 50 维 Glove 词向量进行初始化。下图与本文开头的动图相同。为了便于说明,我们将颜色去掉并将标签添加到了几个数据点上。

有趣的是,当我们对嵌入进行调整时,最初单词「food」与「ramen」(拉面)、「pork」(猪肉)等食物内含类别的空间距离相距甚远,然后它们之间的距离逐渐接近。所以这个模型可能学习到「ramen」、「pork」等都属于食物。同样,我们也看到「table」靠近「restaurant」等等。该动画可以很容易地发现这些有趣的模式。
另一个可尝试的有趣事情是对该工具进行反向工程并进行一些自定义分析。例如,我很好奇恶意评论分类任务中恶意词的嵌入如何发生变化。我在上述恶意评论分类任务中创建了一个模型,从头开始学习嵌入(因此没有使用预训练嵌入进行权重初始化)。给定的数据量可能会对模型造成困难,但值得一试。该架构与 BiLSTM 相同。因此,我只是将所有恶意词汇变成红色并在动画中追踪它们。下图展示了词嵌入的变化轨迹:(PG-13 提示!)
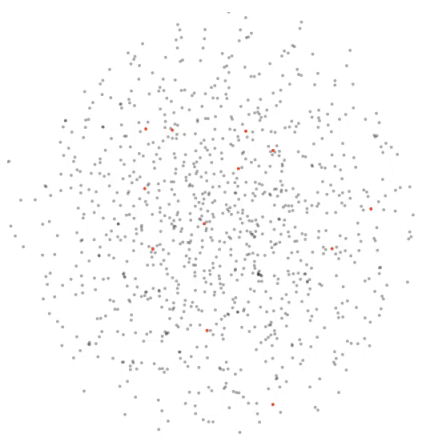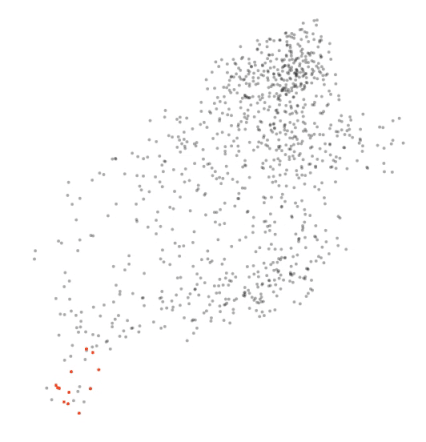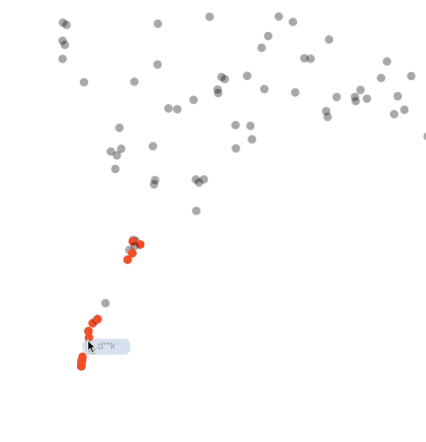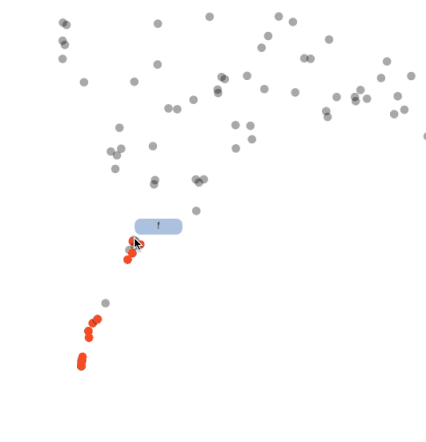
这看起来是不是很吸引人?该模型将脏话(表达恶意的单词)很好地分到一个集群中。
我希望这篇文章能让大家了解以不同的方式可视化数据点的隐藏表示,以及它们如何对模型提供有用解读。我期待将这些分析应用到越来越多的机器学习问题上。希望其他人也会这么想,并从中获得一些价值。我相信它们将有助于减少机器学习模型的黑盒子!
PS:我尝试使用 PCA 将隐藏表示减少到两个维度,然后从中生成动画。PCA 的一个好处是它不是概率形式的,因此最终的表示是一致的。然而,PCA 中的局部邻域可能不像 T-SNE 那样具有可解释性。所以这是一种权衡,但是如果有人对同时利用两种方法的优势有些想法,就太棒了!
参考原文:https://rakeshchada.github.io/Neural-Embedding-Animation.html
【本文是51CTO专栏机构“机器之心”的原创文章,微信公众号“机器之心( id: almosthuman2014)”】