从时间轴上看,我们的 DBA 运维平台每年会有一个比较大的进步,从人肉→工具化→平台化→自助化,我们只用了两年半时间完成全部迭代。
其中平台化&自助化+数据库多活改造,我们用了 8 个月的时间一口气完成全部开发及改造工作。

在完成平台化改造的同时,我们数据库架构也从传统的主从架构发展到异地多活架构,这对 DBA 的挑战是巨大的,但这也是平台必须能够解决的。
因为传统的数据库管理方式在当前这种架构下依靠 DBA 手工或者借助简单的工具是无法应对多活架构 + 大规模管理带来的复杂性,因此平台化显得非常重要。
随着平台化的推进,DBA 职能角色也在发生变化,过去 DBA 在运维和维护上消耗,现在 DBA 更加专注业务做价值输出。
我觉得 DBA 长期在运维层面过多花费时间不断修补各种层面漏缺,其实是不健康的,虽然每天很忙但是新问题依旧会很多。
饿了么 DBA 运维平台概览

我们的数据库平台主体功能概览如下:
- DB-Agent:数据采集 + 进程管理 + 远程脚本 & Linux 命令调用 + 与平台耦合的接口。
- MM-OST:无伤 DDL 系统根据 GH-OST 源码改造实现多活场景下的数据库发布。
- Tinker:Go 重写了 Linux Crontab 的逻辑支持到秒级 + 管理接口与平台整合实现调度集群管理日常任务调度。
- Checksum:多机房数据一致性检查。
- SqlReview:Go 实现的类似开源的 Inception SQL 审核工具并做了功能上的增强。
- Luna:优化后的报警系统(大规模实例下如何减少报警且不漏关键报警)。
- VDBA:报警自动处理系统,代替 DBA 完成对线上 DB 的冒烟&报警的处理。
我不擅长讲一些方法论,下面给大家介绍具体点的内容,让大家有个更清楚的了解。
实时监控&快速排障

这对于 DBA 是非常常见的事情,一般出问题或者接到报警,通常都要登录到服务器,一通命令敲下来可能花的时间最少两分钟,然后得出一个有慢 SQL 或者其他的什么原因。
这个诊断过程完全可以被自动化掉,日常处理问题的核心原则是“快”(我们高峰期线上故障一分钟损失几万单)。
而平台必须能提供这样的能力,出问题时尽量减少 DBA 思考的时间直接给出现象 + 原因缩短决策时间(甚至必要时系统可以自动处理掉有些问题都不必 DBA 参与)。

基于我们的监控大盘,DBA 可以清晰的知道当前全服所有实例是否有异常,哪些有异常及是什么类型的异常或冒烟都会清晰呈现。监控大盘将 DBA 日常管理过程中所有的命令集都整合到一起。
DBA 只需要简单的点点按钮,系统就会自动执行所有命令并做好 SQL 执行计划分析、锁分析、SQL 执行时间分布、历史趋势分析,数据库历史 Processlist 快照查看等常见操作。
虽然这些功能看似简单,但是却非常实用,提高了 DBA 故障定位的效率。
报警处理自动化
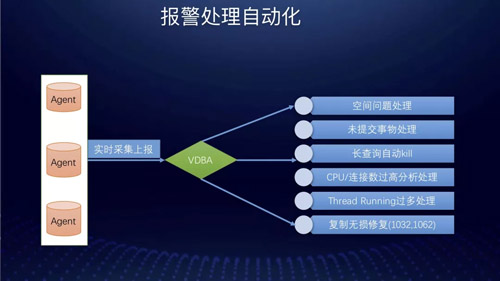
报警处理自动化目前主要包括:
- 空间问题自动处理
- 未提交事物处理
- 长查询自动 Kill
- CPU / 连接数据 / thread runing 过多分析及处理
- 复制无损修复(1032,1062)
过去在处理复制数据不一致异常时同行都是 Skip 掉,但是这样缺陷很多同时会留下数据不一致的隐患。
目前我们采用的是解析 Binlog 的方式来做到精确修复,避免了传统的 Skip 方式的缺陷。
有人可能会说目前社区有很多开源的工具能解决你前面提到的报警问题,为啥非要自己写一个呢?
比如 PT 工具能帮你处理,Auto Kill 一些数据库有问题的 SQL,也能帮你跳过复制的错误,或者 Github 上也有开源的实现能做到无损修复复制问题?
这里的关于重复造轮的问题,我觉得是对待开源态度的问题,开源固然能解决一些问题,但是不同的场景对应不同的开源工具。 当你把这些轮子拼凑到一起时难以形成一个有机整体。
尤其是你在进行平台化建设时必须要考虑清楚这个问题,否则纯粹的开源堆砌出来的系统是难以维护的不可靠的,对于开源我们可以用其思想造自己合适的轮子。
MHA 自动化管理
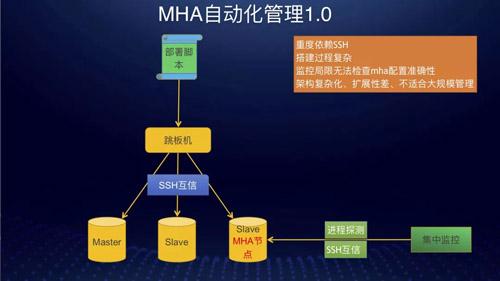
在 8.0 之前绝大部分公司高可用实现还是基于 MHA。MHA 的实现不可避免要解决部署的问题。
最初我们是做一个部署脚本在跳板机上,MySQL 安装时就打通与跳板机的互信工作,然后由该脚本在来打通集群节点间的互信工作,然后在一个 Slave 上启动 MHA 管理进程。
或者是将该管理进程固定在集群外面的某一个或者多个服务器上集中部署&监控,然而这样会有什么问题呢?
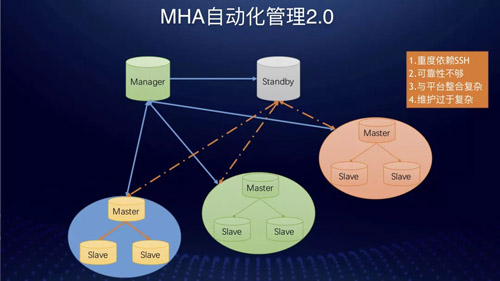
这样会有如下几点问题:
- 重度依赖 SSH。
- 搭建过程复杂。
- Manager 管理节点外溢到一台或多台机器后影响可靠性的因素增多。
- 维护复杂,配置有效性存疑会因此造成稳定性风险。
- 与平台整合过于复杂,平台如果要管理监控 Manager 节点需要借助 SSH 或单独实现一个 Agent。
这种架构管理几十套或者上百套集群时还能勉强应付。当上千套时,管理就很复杂,整体很脆弱,出问题后维护工作量大。
我们在做 MHA 的方案时,做了充分调查及论证,最终没有选择这种方式。
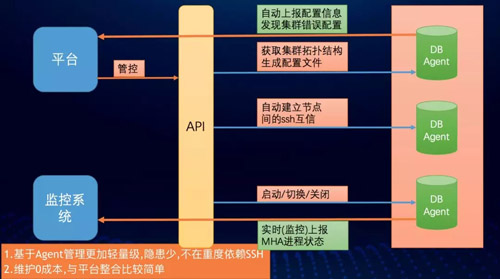
最终我们决定单独搞一套管理方式出来,大致逻辑是依托 Agent 来做到,基本原理如下。
- 每个 DB-Agent 上都独立实现如下接口:
- 获取集群拓扑结构&:(self *MHA)GetDBTopology()
- 生成配置文件:(self *MHA)BuildMHAConfig()
- 节点互信:(self *MHA)WriteRsaPubilcKey()
- 启动:(self *MHA)StartMHA()
- MHA 进程实时监控:(self *MHA)MHAProcessMonitor()
- 定时配置文件与拓扑结构匹配巡查:(self *MHA)InspectMHAConfigIsOK()
- 关闭:(self *MHA)StopMHA()
- 切换:(self *MHA)SwitchMHA()
平台按照一定顺序依次调用上述接口来完成整个 MHA 的从搭建到管理的全部过程。
整个过程完全由平台来完成,极大的减少了 DBA 维护 MHA 的成本。过去 DBA 要配置或者 MHA 切换后的维护时间在 2-10 分钟左右,现在控制在 3 秒以内。
基于 Agent 的管理更加轻量级,也避免了 Manager 节点外溢带来的各种问题,也避免了传统的部署方式上的复杂性,维护零成本,与平台整合非常简单。
平台在将上述接口调用封装成独立的 API 后可供其他自动化平台调用,这将为下一步的完全无人管理提供支持。
资源池&一键安装
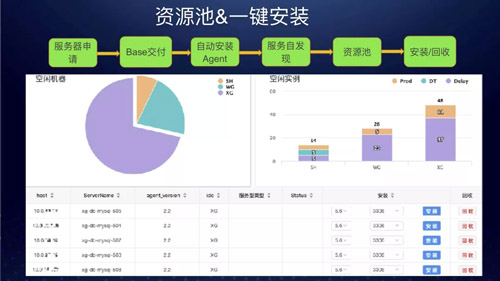
过去业务扩容需要 100 台机器,提交给 Base 需求两天后给你一个 EXCEL 或者一个 Wiki 页面。
我们拿到机器之后去写一些脚本,通过一些工具或者自动化平台刷资源环境检查和安装脚本,但是每个人可能做法不一样,做出来东西五花八门,非常不统一。
别人维护的时候觉得没有问题,当换你维护时候觉得很奇怪,为什么这样做?不够整齐划一,标准化推行不是太好。
现在我们的 DBA 基本上不需要关心这些,DBA 只需要看我们资源池是否有空闲机器,如果资源不足只要负责申请资源即可,其他工作基本都可以由 Agent 自动完成。
一键扩容与迁移
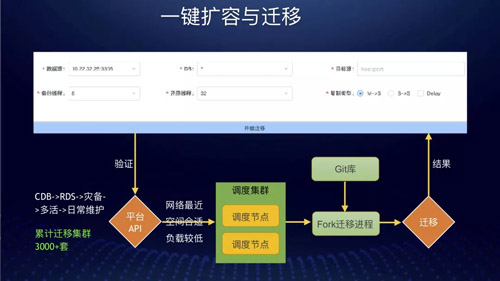
我们 2015 年到 2016 年先后经历了迁移到 CDB,然后又迁移到 RDS,***又做自己的数据库灾备系统。
这期间迁移的集群数超过 3000+ 套,平均每套集群迁移两到三次,这么多迁移量,通过人工很难完成的。
以灾备为例,做灾备时候公司给我们 DBA 的团队迁移时间是两周之内,那时候将近 300 多套集群全部迁移到灾备机房里面去,实际上我们只用了两天时间。
当时我们一个人用了不到一个小时的时间写了一个从集群搭建到调用数据库迁移接口的脚本快速的拉起全部迁移任务。
自动迁移会依托我们调度集群来完成全部的迁移工作。对于日常的自动扩容迁移,DBA 只需要一键即可完成全部迁移过程。
这里我们思考一下有什么手段可以完全避免 DBA 来点这一下按钮呢?这里我觉得对于平台化的过程其实也是所有操作 API 化的一个过程。
对于这点,按钮的动作本身就是调用一个 API,假设我们现在有一套更加高度自动化的系统(有的大公司称为智能系统^_^)能自动判断出容量不足时自动调用该 API 不就完全自动扩容了吗?
DBA 都不需要去人工触发,虽然这是小小的一个操作也能被省略(那么 DBA 后面该何去何从呢?)。
我们现在可以说依靠平台基本上完成了绝大部分标准化、规范化的工作,任何一个 DBA 只要通过平台来完成日常必要的工作,做出来的东西都是整齐划一的,完全避免人的因素导致的差异。
误操作闪回
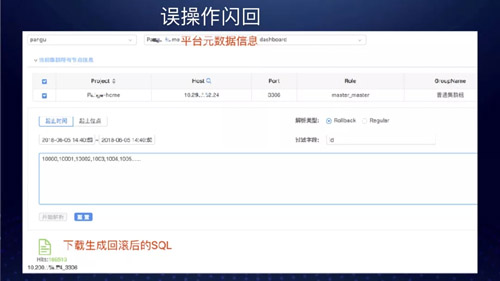
2018 年至今,我们已经做了差不多 4 次线上失误操作,我们都在很短时间内帮用户做到快速回滚。
目前社区有很多关于回滚的解决方案,但是充分调研之后我还是决定自己造轮子(这里又回到前面提到的关于开源及造轮子的问题)。
这里简单阐述原因:开源的优点是通用性、普适性比较强,但是场景化的定制一般比较麻烦。
目前的开源工具都是基于命令行来完成必要的操作,当真的线上需要紧急回滚时还要登录到服务器然后再输入一堆的参数解析,这不符合我对平台化的要求。
既然是平台化,这一系列的操作起码必须是能在界面里面选一选、点一点就能完成的。
也就是说使用要足够简单,尤其这类紧急操作花费的时间要足够短,没必要当着一堆开发的面把命令行敲的贼溜来秀肌肉。
我们的场景复杂举例说明:我们有一套集群单表分片是 1024 片,总共分了 32 套集群,有一天开发突然找来说有部分数据被误操作了,你该如何进行处理?
这里表是被 Sharding 的,开发可能是不知道这批数据落在哪个 Sharding 片里面。
所以你必须解析全部的 32 个节点上的 Binlog, 这时你通过开源的脚本吭哧吭哧起了 32 个进程然后你的 CPU 爆了,网卡爆了……这里分片解析实际上在 32 个进程是不行的。
如果解析脚本不支持对解析的 rowsEvent.Table 表名的正则匹配的话,恐怕要起 1024 个进程……
考虑到上述场景有合适自己场景的解析工具是非常必要的。这里我用 Go 来实现采用了 github.com/siddontang/go-mysql/replication 解析模块。
实现后的解析工具是一个服务化的组件,可以多节点部署应对上述 Sharding 的解析场景,被服务化后可以被平台直接调用。
当真的出现失误操作时,DBA 操作时也不用揪心手抖……所以造每个轮子都有它的理由而不仅仅是爱好。
任务调度&归档
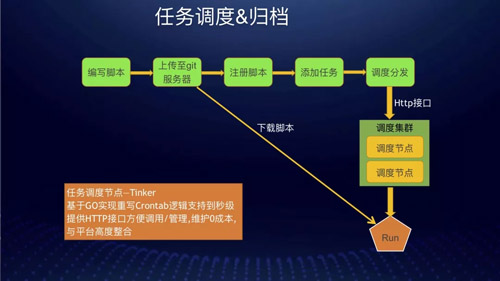
我们的调度服务其实是用 Go 重写了 Linux Crontab 的逻辑并且支持到了秒级。
同时也为了方便管理加了一些管理模块实现服务化,主要还是方便平台调用(也是避免 DBA 手工去配置 Crontab )。
平台对调度节点进行整合实现一个逻辑上的调度集群(后续会改造成真正意义上的调度集群。其实改造方式也很简单,只要在调度节点里面加上节点自动注册然后加一个简单的任务分发器实现负载均衡即可)。
同时对日志功能做了增强,通过调度可以自动的把执行过程中输出的日志记录下来,方便日后追溯原因。
也支持捕获并记录调度脚本 Exit Code,方便对于有些特殊脚本并非只有成功 or 失败两种状态的记录。
举个例子:比如一个脚本执行过程中可能会有很多种 Panic 的可能,但是如果把这些 Panic 的原因都归结为脚本执行异常并 exit(-1) [系统默认的退出码],这样似乎也是可以的。
但是这样 DBA 在检查自己的任务状态时,发现异常时不能直接的定位错误而是要去翻具体的执行错误日志,显得不够快捷(这也是用户体验的点)。
因此 DBA 只需要在平台里面定义好错误代码对照表即可在 Painc 时捕获异常,然后 Exit(exit_code) 就可以,当 DBA 巡查自己的任务时能清晰的知道错误原因。
SQLReview

最初我们的 SQL 审核由开源的 Inception 实现,但是由于我们需要加入更多校验规则,所以需要做一些定制修改。
然而团队内队友不太了解 C,因此很多情况下开发提交发布 SQL 工单后,都是由我们的 DBA 再来人肉审核一遍的。
我们现在平均每天 100+ 的 DDL,DBA 根本审核不过来。即使审核到了,还是会漏很多规则,人工是不能保证一定可靠的。
所以做自己的审核系统是很必要的,但是要独立写一个 sql-parser 模块难度还是非常大的。
在充分调研了 Python&Go 的开源实现后最终选择了 TiDB 的解析模块,于是项目很快就落地了。
在完全覆盖 Inception 的规则后也做了相关扩展,也就是加入我们自定义的规则。
扩展索引的相关校验:
- 冗余索引的校验。(如 ix_a(a),ix_ab(a,b))
- 索引中枚举类型的校验。
- 组合索引中不能包含主键或者唯一索引。
- 建表时必须包含自增 id 的主键。
- 重复索引的校验。(如啼笑皆非的ix_a(a),ix_aa(a)求开发的心理阴影面积?)
- 组合索引列不能超过 3 个。
- 组合索引列时间等可能涉及范围查询的列(类型)必须放在***一位。(如ix_created_time_userid(created_time,userid)这样的索引意义大吗?)
- 索引泛滥拦截。(恨不得每个字段都建立一个索引……)
- Varchar (N>128)拦截或者提示。(警惕!开发可能要写 like 了……)
- 索引命名规范检查。(开发取的索引名称五花八门,甚至有用的劣质 orm 框架生成一个 uuid 的索引名称,当 DBA 在进行执行 explain 时看到这个很头疼根本看不出到底使用了什么索引,往往还要多执行一次 show……)
风险识别拦截或者放行:
- 删索引会根据元数据来判断是否表或者索引是否在使用。(这依托大量的元数据收集&分析,过去 DBA 看见删除操作很头疼要各种验证,最终在操作时还要集群内灰度操作)
- 禁止删列操作。
- Modify 操作损失进度检查。(如 text->varchar,varchar(100)->varchar(10) 等都是禁止的)
- Modify 操作丢失属性检查。(该问题很隐蔽可能有天开发说 default 值丢失了,那多半是某次 DDL 时 Modify 语句没有带上原字段属性导致的,当这引发故障时肯定有人会指责 DBA 为啥你没审核到?MMP......)
- 禁止跨库操作。(防止开发通过 create table Notmydb.table 来意外的给别人创建表)
- 禁止一切 Truncate,Drop 操作。
内建规范检查:
- 大字段使用规范约束。(比如一个表里面超过一定比例的 Varchar,包含 longtext 等大文本类型)
- DB,表,索引命名规范约束检查。
- 多活必要的字段及属性检查。
历史校验结果数据沉淀:
- 通过数据分析准确的知道哪些产研或者开发在上述方面犯错最多。(DBA 跟开发的关系往往也是斗智斗勇的关系你懂得……)
这里不得不说的是过去我们为了防止开发违反上述规则,除了人肉审核外还对开发去培训但是这往往都没有用,该犯的错误还是会不断的犯。
所以我们现在基本不在去搞什么培训了,完全由系统自动来完成审核。
这里我一直强调的是任何标准化/规范化都是必须能够写进代码里的,否则实施起来必然有缺漏。
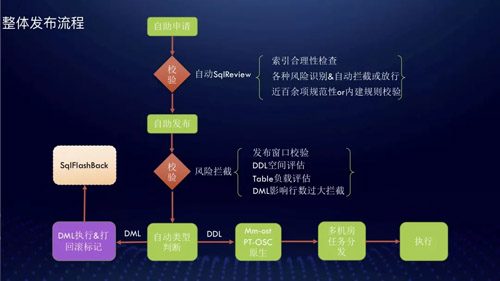
多活下的发布系统
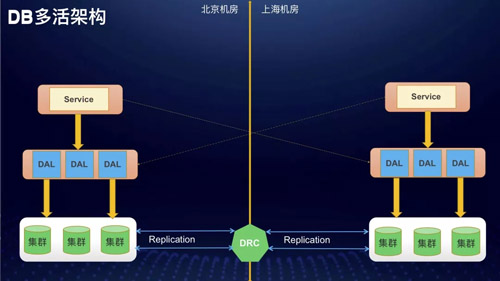
数据库多活的架构大致是这样:M?DRC?M。这里 DRC 是我们的多机房数同步工具,这里可以把数据库多活理解成双 Master 系统,只是用 D 代替了双 Master 下的原生复制。
这种架构下对 DBA 的维护挑战还是非常大的,时间关系只分享关于数据库发布的相关内容,这也是最重要的一块。
说到数据库发布基本上就是在说 DDL 对吧,一直以来 DDL 对开发来说都是非常头疼的,DBA 往往会选择 PT 工具来完成 DDL 操作。
但是受到 PT 是基于触发器实现的,影响 DDL 期间会产生锁等待现象,这会造成业务上的影响,过去我们也在这上面吃过很多次亏。
Alter 通过什么方式来进行?有如下几个方式:
原生 DDL 多机房并行执行:DRC 不支持,机房间延迟不可控,机房内延迟巨大。
PT-OSC 多机房并行执行:Row 模式下大表的 DDL 会产生大量的 Binlog,IDC 间的网络瓶颈造成全局性影响。
PT 工具在不同机房间最终的 Rename 阶段时间点不同,造成机房间数据结构不一致导致 DRC 复制失败,最终导致不可控的数据延迟。
基于触发器的实现会产生额外的锁,对业务影响明显;基于 PT 源码改造困难也难以与平台整合(3P 语言只剩下了 Python……)。
Gh-OST 多机房并行执行(基于 Go 实现):增量数据基于 Binlog 解析实现避免触发器的影响;基于 Go 实现为改造提供可能。

关于 GH-OST 我不打算多讲,大家可以去 Github 上看作者对实现原理的说明,这里还是简要提一下大致工作流程:
- 创建中间表临时表。
- 对该临时表进行 DDL。
- 在 Master 或者 Slave 上注册,Slave 接收 Binlog 并解析对应表的 Events 事件。
- Apply Events 到临时表。
- 从原表 Copy 数据到临时表。
- Cut-Over(我们的改造点从这里开始)相当于 PT 的 Rename 阶段。

我们做了一个协调器,每个 GH-OST 在 DDL 过程中都上报自己的执行进度,同时我们在 Cut-Over 前加了一层拦截。
必须等待多个 GH-OST 都完成数据 Copy 后,多个 GH-OST 节点才会同时进入 Cut-Over 阶段。
这样就保证了多机房同步 Rename 进而来避免延迟的产生(事实上我们机房间的延迟都控制在秒级)。这里大家可能会有疑问直接在一个机房做不行吗?可以依靠 DRC 同步啊?
首先 DRC 不支持 DDL 操作,这样就决定了没法通过 DRC 同步方式来进行,其次机房间带宽有限 DDL 期间产生大量 Binlog 会造成带宽打满的问题。
我们在进行双机房同步 DDL 时,为了防止 DRC 应用了 GH-OST 产生的 Events,DRC 会主动丢弃 GH-OST 产生的 Binlog 具体是根据 TableName
命名规则来区分。
对 GH-OST 的改造还包含添加多机房负载均衡功能,由于 DB 是多机房部署的,你的 GH-OST 工具肯定不能部署在一个机房里(解析 Binlog 速度太慢,Copy 数据过程非常慢主要是消耗在网络上的延时了)。
但是多机房部署也还是不够的,还得是每个机房都部署几套 GH-OST 系统。
因为当开发同时 DDL 的量比较大时,单台 GH-OST 系统会因为要解析的 Binlog 量非常大导致 CPU、网卡流量非常高,影响性能(跟前面提到的闪回功能是同一个道理)。
搞定发布系统后,DBA 再也不用苦逼的值班搞发布了,起初我们搞了一个自动化执行系统,每天系统会自动完成绝大多数的工单发布工作。后来我们完全交给开发来执行。
现在从开发申请发布到最终发布,完全由开发自助完成,自助率平均在 95% 左右,极少有 DBA 干预的情况。
随着数据库的不断进步与完善甚至开始往 SelfDrive 上发展加之这两年 DevOps,AIOps 的快速发展。
也许留给传统运维 DBA 的时间真的不多了(不是我在鼓吹相信大家也能感受的到),我想除了时刻的危机感 + 积极拥抱变化外没有其他捷径了。
作者:蔡鹏
简介:2015 年加入饿了么,见证了饿了么业务&技术从 0 到 1 的发展过程,并全程参与了数据库及 DBA 团队高速发展全过程。同时也完成个人职能的转型,由运维 DBA 到 DEV-DBA 的转变,也从 DB 的维稳转变到专心为 DBA 团队及 DEV 团队的赋能。