主要讲了Logistic regression的内容,里面涉及到很多基本概念,是学习神经网络的基础。下面我们由Logistic regression升级到神经网络,首先我们看看“浅层神经网络(Shallow Neural Network)”
一、什么是神经网络
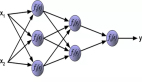
我们这里讲解的神经网络,就是在Logistic regression的基础上增加了一个或几个隐层(hidden layer),下面展示的是一个最最最简单的神经网络,只有两层:
两层神经网络:
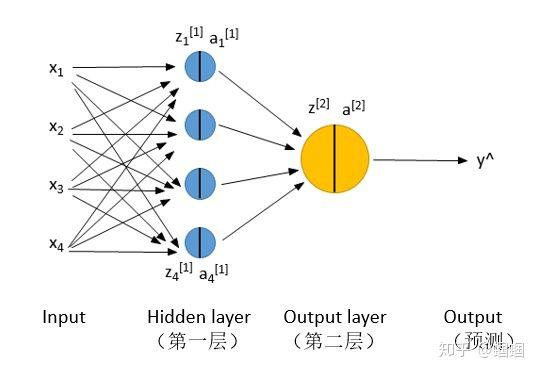
需要注意的是,上面的图是“两层”,而不是三层或者四层,输入和输出不算层!
这里,我们先规定一下记号(Notation):
- z是x和w、b线性运算的结果,z=wx+b;a是z的激活值;下标的1,2,3,4代表该层的第i个神经元(unit);上标的[1],[2]等代表当前是第几层。y^代表模型的输出,y才是真实值,也就是标签
另外,有一点经常搞混:
- 上图中的x1,x2,x3,x4不是代表4个样本!而是一个样本的四个特征(4个维度的值)!
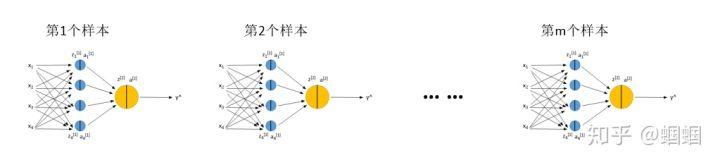
你如果有m个样本,代表要把上图的过程重复m次:
神经网络的“两个传播”:
- 前向传播(Forward Propagation)前向传播就是从input,经过一层层的layer,不断计算每一层的z和a,***得到输出y^ 的过程,计算出了y^,就可以根据它和真实值y的差别来计算损失(loss)。反向传播(Backward Propagation)反向传播就是根据损失函数L(y^,y)来反方向地计算每一层的z、a、w、b的偏导数(梯度),从而更新参数。
- 前向传播和反向传播:
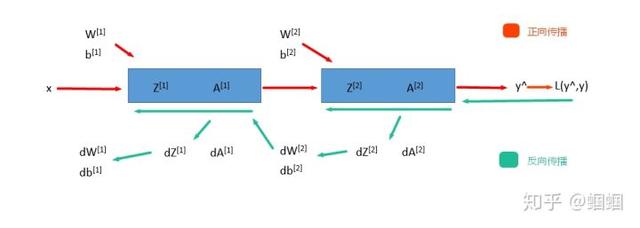
每经过一次前向传播和反向传播之后,参数就更新一次,然后用新的参数再次循环上面的过程。这就是神经网络训练的整个过程。
二、前向传播
如果用for循环一个样本一个样本的计算,显然太慢,看过我的前几个笔记的朋友应该知道,我们是使用Vectorization,把m个样本压缩成一个向量X来计算,同样的把z、a都进行向量化处理得到Z、A,这样就可以对m的样本同时进行表示和计算了。
这样,我们用公式在表示一下我们的两层神经网络的前向传播过程:
Layer 1: Z[1] = W[1]·X + b[1]A[1] = σ(Z[1])
Layer 2: Z[2] = W[2]·A[1] + b[2]A[2] = σ(Z[2])
而我们知道,X其实就是A[0],所以不难看出:每一层的计算都是一样的:
Layer i: Z[i] = W[i]·A[i-1] + b[i]A[i] = σ(Z[i])
(注:σ是sigmoid函数)
因此,其实不管我们神经网络有几层,都是将上面过程的重复。
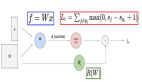
对于 损失函数,就跟Logistic regression中的一样,使用 “交叉熵(cross-entropy)”,公式就是二分类问题:L(y^,y) = -[y·log(y^ )+(1-y)·log(1-y^ )]- 多分类问题:L=-Σy(j)·y^(j)
这个是每个样本的loss,我们一般还要计算整个样本集的loss,也称为cost,用J表示,J就是L的平均:
J(W,b) = 1/m·ΣL(y^(i),y(i))
上面的求Z、A、L、J的过程就是正向传播。
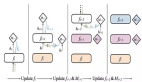
三、反向传播
反向传播说白了根据根据J的公式对W和b求偏导,也就是求梯度。因为我们需要用梯度下降法来对参数进行更新,而更新就需要梯度。
但是,根据求偏导的链式法则我们知道,第l层的参数的梯度,需要通过l+1层的梯度来求得,因此我们求导的过程是“反向”的,这也就是为什么叫“反向传播”。
具体求导的过程,这里就不赘述了,有兴趣的可以自己推导,虽然我觉得多数人看到这种东西都不想推导了。。。(主要还是我懒的打公式了T_T")
而且,像各种 深度学习框架TensorFlow、Keras,它们都是 只需要我们自己构建正向传播过程, 反向传播的过程是自动完成的,所以大家也确实不用操这个心。
进行了反向传播之后,我们就可以根据每一层的参数的梯度来更新参数了,更新了之后,重复正向、反向传播的过程,就可以不断训练学习更好的参数了。
四、深层神经网络(Deep Neural Network)
前面的讲解都是拿一个两层的很浅的神经网络为例的。
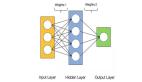
深层神经网络也没什么神秘,就是多了几个/几十个/上百个hidden layers罢了。
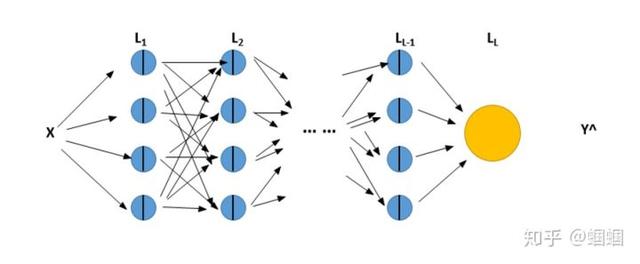
可以用一个简单的示意图表示:
深层神经网络:

注意,在深层神经网络中,我们在中间层使用了 “ReLU”激活函数,而不是sigmoid函数了,只有在***的输出层才使用了sigmoid函数,这是因为 ReLU函数在求梯度的时候更快,还可以一定程度上防止梯度消失现象,因此在深层的网络中常常采用。关于激活函数的问题,可以参阅:【DL碎片3】神经网络中的激活函数及其对比
关于深层神经网络,我们有必要再详细的观察一下它的结构,尤其是 每一层的各个变量的维度,毕竟我们在搭建模型的时候,维度至关重要。
我们设:
总共有m个样本,问题为二分类问题(即y为0,1);
网络总共有L层,当前层为l层(l=1,2,...,L);
第l层的单元数为n[l];那么下面参数或变量的维度为:
- W[l]:(n[l],n[l-1])(该层的单元数,上层的单元数)b[l]:(n[l],1)z[l]:(n[l],1)Z[l]:(n[l],m)a[l]:(n[l],1)A[l]:(n[l],m)X:(n[0],m)Y:(1,m)
可能有人问,为什么 W和b的维度里面没有m?
因为 W和b对每个样本都是一样的,所有样本采用同一套参数(W,b),
而Z和A就不一样了,虽然计算时的参数一样,但是样本不一样的话,计算结果也不一样,所以维度中有m。
深度神经网络的正向传播、反向传播和前面写的2层的神经网络类似,就是多了几层,然后中间的激活函数由sigmoid变为ReLU了。