大数据文摘出品
编译:CoolBoy
大家好!文摘菌发现了一份过去的一个月机器学习项目的Top 10,特地为大家搬运过来,看看你pick哪一个呢?
这个榜单是从过去一个月的250项开源机器学习项目中挑选出来的。作者比较了这段时间内的新的,重大的成果,并根据一系列的因子来衡量它的专业水准。
开源项目对程序员非常有用,希望你也可以从中找出启发你的那一个!
第十名
GANimation:基于单图的结构性脸部动画(Albert Pumarola等人)[Github中获得344星]
https://github.com/albertpumarola/GANimation?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

这是一个基于动作单元(AU)的新型GAN体系,它展示了一个连续多样的结构性脸部变化,从而定义面部表情。此方法允许调整每个动作单元的度量,并且可以结合其中的几个单元。
第九名
Sg2im:基于场景图的图像生成(谷歌开源) [Github中获得670星]
https://github.com/google/sg2im?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

场景图是一个视觉场景的结构表示图,其中节点表示物体,连线表示物体间的关系。此研究介绍了一个输入场景图,输出图像的端到端神经网络模型。
第八名
Stt-benchmark:语音到文字的基准衡量(Picovoice) [Github中获得294星]
https://github.com/Picovoice/stt-benchmark?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
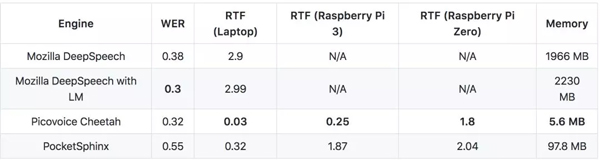
Cheetah是Picovoice为物联网应用设计的语音识别引擎。与其他模型相比,Cheetah的表现几乎接近于***的DeepSpeech(0.3 vs 0.32 WER)。但是,它有着快100倍的速度和少398倍的内存。这让Cheetah可以在嵌入小型货品的平台(例如Raspberry Pi)运行,并且便利于大型的,需要更多计算与存储资源的模型。
第七名
Artificial-adversary:生成对抗文本的工具,测试机器学习模型 (Airbnb Engineering)[Github中获得155星]
https://github.com/airbnb/artificial-adversary?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

在区分用户生成的文本时,用户可以有很多方式修改内容,以免被监测。这包括将字符换为类似的长相的字符。例如please wire me 10,000 US DOLLARS to bank of scamland (请给我转10,000美元)可能是一条诈骗信息,但是如果写成pl3@se.wire me 10000 US DoLars to,BANK of ScamIand,很多鉴别器将失灵。
使用这个扩展库,你就可以利用这些方法生成文本,并在你自己的机器学习算法上测试。
第六名
Soccerontable: 在你的桌面上观看足球比赛(Konstantinos Rematas)[Github中获得247星]
https://github.com/krematas/soccerontable?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

第五名
DanceNet:使用Autoencoder,LSTM和混合密度网络的舞蹈生成器 (Keras)[Github中获得282星]
https://github.com/jsn5/dancenet?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more


第四名
UnsupervisedMT:基于短语与神经非监督机器翻译(Facebook Research)[Github中获得490星]
https://github.com/facebookresearch/UnsupervisedMT?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
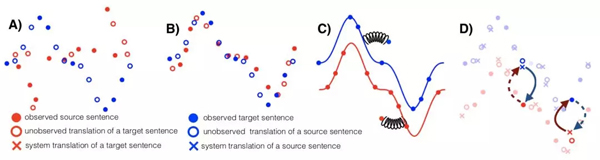
如今的机器翻译系统虽然接近人类的效率,但这和大量的平行语句有关。这篇文章研究了如何在单一语料库的情形下学习翻译。作者们提出了一种神经模型和一种基于短语的模型。两种模型都在初始化参数、模型降噪、平行数据的迭代生成上斟酌。它们的表现大幅超越之前的模型,并且有着更简单的结构和更少的超参数。
第三名
Vid2vid:视频到视频的合成(NVIDIA AI)[Github中获得1797星]
https://github.com/NVIDIA/vid2vid?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more
这篇文章提出一个新型的,利用对抗生成结构的视频到视频合成方法。Github包含了Pytorch的高分辨率实现。这个模型可以将语义标记图转为实际视频,从描边图生成真人讲话动作,或者是由姿势生成人类动作。
第二名
Glow:可逆的1x1卷积生成流(OpenAI)[Github中获得1664星]
https://github.com/openai/glow?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

Glow是一个可逆的生成模型,它被用来做1x1的可逆卷积。它延续了之前的研究(https://arxiv.org/abs/1605.08803),并简化了其结构。此模型可以生成高分辨率的图像,发现可操纵数据的特征。
***名
Autokeras:自动化机器学习(AutoML)的开源软件库(Haifeng Jin)[Github中获得2637星]
https://github.com/jhfjhfj1/autokeras?utm_source=mybridge&utm_medium=blog&utm_campaign=read_more

Auto-Keras是一个AutoML的开源软件库。它由德州农机大学的DATA Lab开发。AutoML的最终目的是将简易的深度学习工具提供给各个领域中不具有数据科学背景的专家。Auto-Keras提供了一些函数,以建立可自动寻找结构和超参数的深度学习模型。
相关报道:
https://medium.mybridge.co/machine-learning-open-source-of-the-month-v-aug-2018-ae85e7302ea5
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】