前言
很高兴认识大家,之前做过很多分享,今天这次终于讲到正题了。因为之前一直讲自动化运维,其实做这么多年运维,自动化运维没干多少年。这几年很多公司各方面机器数量多了,规模大了才开始去做自动化运维。
今天的课题是高性能Web架构之缓存体系,之所以讲这个体系是因为作为一名运维工程师,我们经常会遇到Web站点访问很慢的情况。要解决这个问题,直接找开发,问题也不一定能解决。因为这个问题不仅仅是开发的问题,
这个问题涉及到浏览器从发出请求到响应请求的一系列问题,所有地方都需要一点点摸清楚才能***找到问题所在。
1、认识Web缓存知识体系
1.1从HTTP请求说起
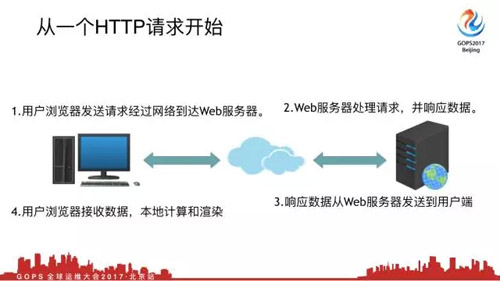
我们从一个Http的请求开始,先介绍下环境,左边是我们的用户端浏览器,右边是我们的Web服务器,当然Web服务器后面整体架构就不说了。
- ***步,当用户浏览器发出一个请求,这个请求会经过网络到达Web服务器。这句话说明了当一个数据包从用户端发送到Web服务器端,这个时间是时网络延迟时间。
- 第二步,Web服务器处理请求,并响应数据。如果是动态请求我需要查缓存,查数据库,最终把请求返回给浏览器,这个时间是响应时间。
- 第三步,响应数据从Web服务器发送给用户端,这又是网络传输时间。
- 第四步,用户浏览器接收数据,本地计算和渲染。这个时间就是计算和渲染的时间,你的JS脚本不一样,渲染时间也是不一样的,但是这个时间是比较小的。
1.2 处理数据的时间去哪了?
Web访问时间大家看主要花费在哪几个方面,客户端请求,从用户端发到服务器端,服务器端响应,服务器端发回用户端,还有一个比较大的时间是处理数据的时间。
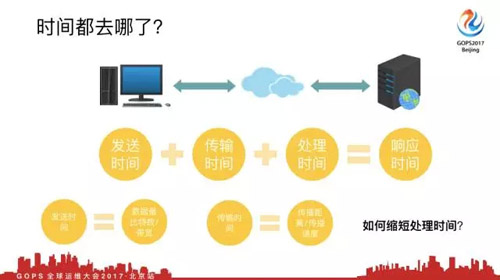
我们来研究一下时间都去哪儿了,发送时间+传输时间+处理时间=响应时间。发送时间=数据量比特数/带宽,传输时间=传输距离/传输速度,这就是整个数据包的传输时间。
目前网络的处理时间很多时候我们不是说不能去优化,至少可以说我们普通的运维和开发在这块接触的少一些。现在可能也有很多做网络传输优化的产品,这里我们暂不讨论。
1.3 如何缩短处理时间
我们今天讨论,如何缩短处理时间。因为返回数据我们可以通过各种各样方式解决。那么处理时间如何缩短也有很多方式。比如你去提高服务器并发,修改架构等等有非常多的处理方式。咱们今天讲如何使用缓存来减少处理时间这是今天的重点。
就像我说的在网上找不到一个完整的请求从出来一直到***所经历的缓存,怎么办?自己写一个,我按照一个Http请求从浏览器发出一直到***,把所经历的缓存全部做了一遍。
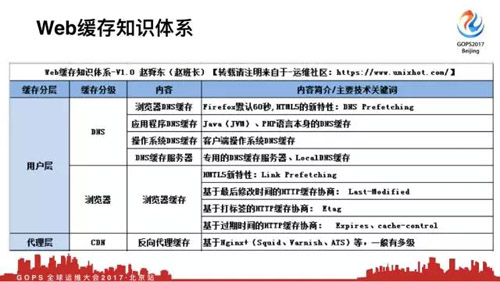
首先用户层在浏览器输入一个域名,这个时候***步不是DNS解析。***步是浏览器DNS缓存,比如谷歌、火狐浏览器默认的就是60秒。这没有严格意义上的上下级,应用程序DNS缓存,操作系统DNS缓存,DNS缓存服务器。***解析出IP地址,然后到浏览器缓存。
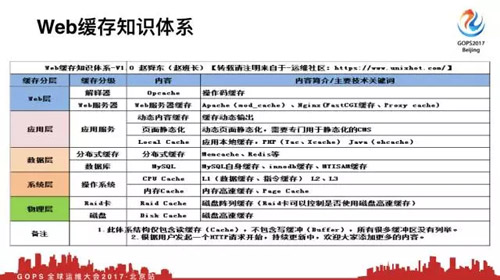
我们会讲浏览器缓存协商的三种办法。然后请求继续往下就走到代理层,CDN代理缓存。
然后请求会到达Web服务器,然后到应用层,然后到数据库,有数据库缓存,然后到系统层面。
***要访问硬盘上某一个文件,有系统层面缓存。***到物理层,要访问硬盘上的某一个数据,要读写某一个blog,这就涉及到物理层。我们仅包括读缓存,没有包括写缓存。
2、关于Buffer与Cache
2.1什么是Buffer和Cache?
- Buffer一般用于写操作,我们称之为写缓冲。为什么会有Buffer呢?因为不同的计算设备它的速度不同,比如说CPU能直接往硬盘写数据吗?因为硬盘太慢了,所以CPU只能写在内存里,内存再往硬盘写,我们称之为缓存。
- Cache一般用于读操作,我们可以称之为读缓存,我们把正常取用的数据放在离我们最近的地方,我们可以快速取到。
2.2 什么是Cache
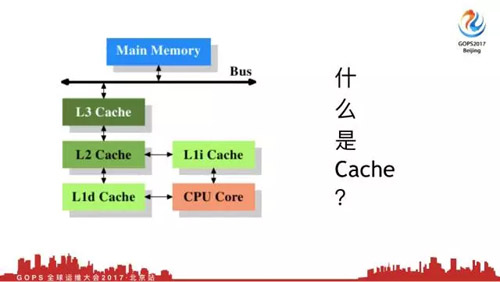
这是一个Cache案例,这是CPU有三级缓存,三级Cache,然后内存。现在先不要考虑Cache和Buffer的区别。
2.3 什么是Buffer?
白色曲线区域是左转弯待转区,它的作用是:比如现在是红灯,但是我们车可以越过停止线到左转弯待转区,待转区是弧形的,离目的地更近的区域,这就是生活中Buffer的案例。
我将车停在离目的地更近的地方,这样转弯的时候一下子就可以转过去,我可以转得更快,转得更快就可以减少道路的拥堵,这就是Buffer的作用。
2.4 再次定义Buffer与Cache!
在我们计算机中也是一样的,CPU写数据不能直接写硬盘,因为硬盘太慢了,我不能等待,这时候我把数据写在内存中返回,剩下内存再往硬盘里写。
但是很多时候我们不会特别区分Buffer和Cache,因为很多的区域会发现,不仅仅有读缓存Cache的功能,也有写缓存Buffer的功能。所以你经常看到有些区域是Buffer开始,或者统一叫做开始,这个时候怎么分辨呢?
根据它的功能不同来区分是Buffer还是Cache,有的Cache就仅仅指的是读缓存,它没有Buffer功能,但是有的Cache里面有Cache有Buffer,比如内存就是典型的。我们写数据写内存,读数据也是内存里面读,这个就是典型的名词的问题。所以很多时候我们不用纠结它是Buffer还是Cache,我们怎么分辨呢?
我们通过它的功能来分辨:
- Cache一般用于读缓存,用于将频繁读取的内容放入缓存,下次再读取相同的内容,直接从缓存中读取,提高读取性能,缓存可以有多级。
- Buffer一般用于写缓冲,用于解决不同介质直接存储速度的不同,将数据写入到比自己相对慢的不是很多的中间区域就返回,然后最终再写入到目标地址,提高写入性能,缓冲也可以有多级。就像内存写硬盘也很难,所以硬盘都会用缓存。
我们都知道硬盘都会有一个Cache,这个Cache其实有Buffer的功能,也有Cache的功能。因为写数据只要往硬盘里写数据,就会经过Cache区域,读数据,我们很多有预读的功能也要经过这个区域,这个区域就叫做Buffer开始或者简称开始。
可以看到缓存和缓冲都可以有多级,或者说可以分层。咱们很多做开发的,应该会知道分层分级这种设计是一个架构师最基本的设计方式。
- 3.关于Cache
- 3.1存放位置

Cache存放位置,我们还是站在Web架构角度。
- 客户端,我这个网页要存在客户端当然快了,用户根本不用发请求直接就打开了,这时候就是浏览器缓存。浏览器就是把我的缓存存在用户客户端,所以用户打开页面就会非常快。
- 内存,内存就分为最快本机内存,但是本机内存的容量有限,这时候可以存在远程服务器内存。比如分布式缓存其实就是存在远程服务器的内存,当然性能没有本地内存好,因为要经过网络传输。网络传输就会有时间,会有性能的影响。
- 硬盘,本机硬盘是***的,再往下远程服务器硬盘,比如我们用的分布式软件系统,或者共享文件系统,这就是典型的远程服务器硬盘。
3.2 内存文件存储之tmpfs介绍
还有一种方式,像这样存在本机内存,比如我们写一个应用程序,这个应用程序要把数据存在本机内存,开发就很容易做到。
举个例子,对于运维来说,我有一些数据访问非常频繁,但是我又没法快速把它放在内存中,这时候怎么办?其实linux系统给我们提供了一个文件系统,可以把我们数据直接放在内存中,就是tmpfs。
如果大家是老运维,你工作至少在七八年以上的运维,应该对这个比较熟悉,因为最早的时候基本都会用到tmpfs,tmpfs是怎么玩的呢?它是把数据直接放在共享内存中,它是特殊文件系统,我这里做了一个案例。
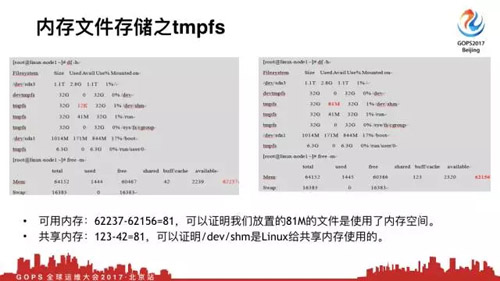
我们可以看到这个tmpfs,是系统默认的,是32G,使用率12k,这个时候我仅需放81兆文件,你会马上发现dev/shm目录就占用81兆,可用内存同62237变成62156,共享内存从42变成123。
这个时候做一个小学计算题,可用内存,说明我们放81兆文件是占用了内存空间的。然后共享内存,可以证明我们/dev/shm是Linux给共享内存用的,这就是典型的案例。
3.4 内存文件存储之tmpfs使用方法

这个tmpfs怎么用呢?直接#就可以了,当然你还可以设置不同大小。用tmpfs有什么优势呢?
- ***,存储空间的设置和动态变化,放里面就增加,删了就自动缩减。
- 第二,速度。天下武功,唯快不破,因为它是内存。
- 第三,没有持久性,这是它的缺点也是优点。为什么是缺点呢?机器一重启数据丢失了,为什么是优点呢?因为有些场景下机器重启就要让他丢失。
这就看你怎么用了,比如我把缓存数据放在这儿就会比较快,如果说你又想用它的优势,又想保持持久性,方式也很多,只要每次数据可实时同步就可以解决。
另外我们做反向代理缓存,数据是要落盘的,这时候可以考虑使用tmpfs。还有session文件放在tmpfs,还有将socket文件放在tmpfs,还有其他需要高性能读写的场景。
3.5 内存文件存储之tmpfs优势对比

为什么讲这个呢?因为我们之前有一个案例就使用到tmpfs,是电商有一次做活动,我们内部刚好有一个需求,需要一个性能读写的场景,要不停地写,不停地读,这个时候我们考虑了非常多其他的方案,发现I/O就是扛不住,这时候就想起了tmpfs,直接就可以用。这是讲Cache的存储位置就带出了tmpfs。
3.6 Cache的几个重要指标
这里有一个面试题,我们手机常用的一个功能,云备份,可以备份你的图片和短信到云端,这样的功能是否需要CDN加速,为什么?我的手机短信备份到云上,换一个手机再下载下来,这样的需求需要使用CDN加速吗?其实答案非常明确,不需要。当然有别的疑惑一会儿再说,我只是说云备份的场景是不需要的,为什么?

这就涉及到缓存几个重要的特性。缓存的***率,所有缓存如果没有***率,只会加慢整个流程,为什么?
因为我们加缓存相当于数据访问和读取加了一层路径,这个路径如果没有发挥作用就会变慢,所以缓存***率是缓存非常重要的指标,就可以解释为什么说这样的需求不需要CDN加速,原因是因为没有***率。
我的图片、短信只有我自己能访问到,我同步到云端,换手机的时候,只有我自己才下,缓存***率是0%,当然是不需要CDN加速的。
但是还有一种场景可能会需要,就是云盘。但云盘有两种不同场景,我们现在用的把数据同步到云盘上,这个是不是需要CDN加速呢?不一定,一般这种云盘都非常智能的,它在下载的时候会判断你这个资源的热度。
具体怎么做,因为我没有干过不知道,但是我们有类似相关系统,给资源热度打分。比如说当资源热度很高的时候,这个时候说明下载的人比较多,这个时候可以考虑放在CDN上。
但是存储的时候还有很多的比如验证,可能就不会上传等等很多存储功能,今天主要是缓存为主,讲读缓存。这个时候有可能需要CDN加速,但是云备份场景是不需要的。这就是说我们掌握问题要掌握知识的最根本的地方,这个时候不管我们做什么,你会发现所有问题都会迎刃而解。
4、关于客户端的优化
4.1浏览器与DNS缓存
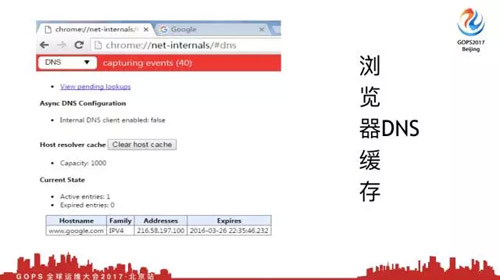
当我们发出一个Http请求,***步要做DNS解析。这是一个谷歌浏览器的截图,这就是DNS缓存保存的地方。可以看到我访问谷歌,我访问的时间刚好是1分钟60秒,下面这是浏览器DNS缓存。
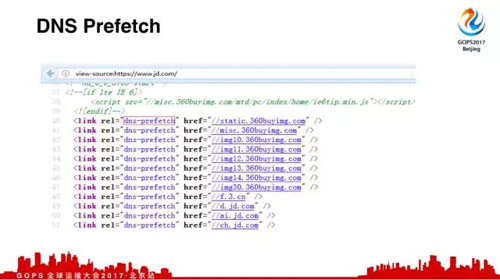
现在像HTML5有一个新特性,叫做DNS运货区,这是京东首页,可以看到很多的链接,什么意思呢?一个页面组件最多的是图片等等东西。我先讲一个前置条件,Http协议我们通常称为流式的,为什么?
因为我是边下载边渲染,一个浏览器首先会请求Web服务器,拿到整个HTML页面,浏览器会从上往下挨行读,每读到一个行,浏览器会提一个新的线程下载新的页面组件资源,下载完成就直接渲染出来了。
为什么我们打开网页会慢
问题一、当遇到阻塞的时候网页打开慢
当遇到什么情况下会阻塞?当遇到加载JS会阻塞,你会看到一个页面一直在转圈,JS阻塞,因为JS有可能会修改页面的道路数,所以加载JS的时候要等JS下载完毕,并执行完毕,才能继续往下加载。
所以我们经常做Web优化的时候,我们会把CSS放在页面顶端,把JS在页面放在底部,因为JS下载会阻塞。
问题二、为什么一个文件有多个域名
第二个问题,你会怀疑京东一个图片为什么值得上10—30这么多个域名呢?是因为浏览器访问一个Web站点,浏览器是有并发限制的,不可能单进程跑,像火狐这种一般不同版本可能6—8个并发,但是并发是针对的域名,所以他搞了很多域名,这样就可以让页面打开更快。
但是域名多了就会产生另外一个问题,DNS解析就多了,这时候怎么办呢?HTML5有一个新特性叫做DNS运货区,我可以把先把DNS解析获取一遍,等你下面用的时候直接用就可以了,不用再解析了。
这些手段其实都是来加快前端优化的手段,当然还有很多,比如减少页面组件,页面组件少了当然打开就快了。或者合并请求,比如咱们做运维,做淘宝的,就支持做组件合并,比如把某些小的CSS、JS合并起来发送,这样就会更快。
如何优化
当然还有CSS背景偏移,很多小图标,我其实只是一个图片,我下载下来再通过背景偏移技术,再把它展示在页面上。还有比如懒加载,为了加快首屏时间,我使用懒加载。我先把首屏需要的资源加载下来,鼠标往下拖的时候再一点点加载,这些手段都是加快首屏时间或者Web页面打开的时间。
当然DNS缓存还有很多其他的,除了浏览器DNS缓存,剩下的就是系统文件。系统DNS缓存,到localDNS,localDNS也是集群,有缓存,所以每一级都是DNS缓存。
很多时候我们对于一些比如你要改某一个DNS的A记录,我们会怎么做呢?我会提前把A记录TTL生存周期时间改得很短,这样我改A记录的时候就会很快,当然大家做运维会知道,中国有很多小的运营商耍流氓,把DNS缓存设了很长,我还见过设好几天的,所以改完以后在一些小的地方就是不生效。
DNS解析完毕,解析成公网IP地址,浏览器就会往公网IP地址发起请求。当然中间涉及到网络传输,一个request的网络传输,一个数据的网络传输,这个时候就涉及到Http缓存线上,一个客户端和server端要对话就是通过Http对话。
我发一个request告诉你服务器能不能使用本地缓存,缓存有没有过期,服务器告诉他你可以使用本地缓存。
4.2关于浏览器缓存

浏览器缓存协商有三种方式,首先我们看浏览器缓存在什么地方,上图是火狐浏览器,火狐放在内存和磁盘。有的时候火狐浏览器大家发现会打开比较慢,加载缓存,内存里有很多这样的数据。
4.2.1 基于Last-Modifiedh缓存协议
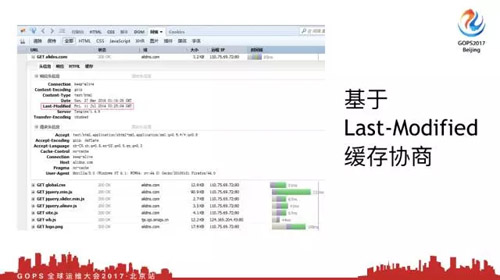
我们看***种缓存协商方式,基于***修改时间的缓存协商,我们都知道默认情况下,所有的系统都会有三个时间。
我们有一个***修改时间,那我们所有的Web浏览器都很聪明,默认情况下都会通过SDNT系统调用,可以获取到静态文件***修改时间。当你请求一个静态页面的时候,浏览器默认会返回给你这个页面***修改时间是什么。
***次请求会发现都是200,我们看一下request头部,请求头,响应头,在响应头里可以看到***修改时间是2016年,这就是我的文件修改时间,浏览器默认会把这个时间带上。
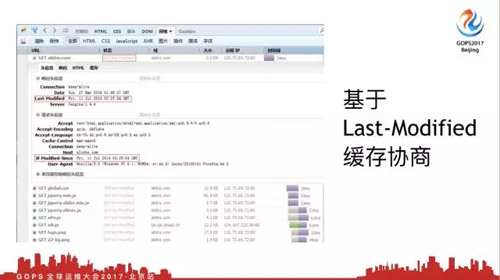
现在我点击刷新按钮,你会发现Web服务器返回了304,这就是基于***修改时间的缓存协商。这个时候请求头请求的时候怎么请求呢?
它会问浏览器,你告诉我这个页面保存修改时间是这个,你告诉我有没有改,浏览器就告诉它,兄弟这个页面没有改过,你直接使用本地缓存就可以。这个时候我们Web服务器不会发数据给浏览器,浏览器直接使用本地缓存就可以了。
但是你说动态的行不行,行,为什么?你伪造一个Http头部是可以的。所以为什么讲这个,不是说搞笑说段子。你要明白客户端、浏览器通过什么沟通,就是通过Http协议,只要你返回的时候返回一个头部有***修改时间,就能实现这个功能,只不过这是浏览器一个默认的行为。
4.2.2 基于Etag缓存协议
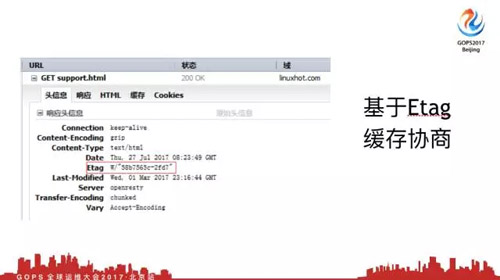
第二种缓存协商方式打标签,一个页面频繁在***修改时间变动,但是内容没有变,我的页面是每次重新生成的,但是页面内容并没有变。如果基于***修改时间,这个缓存就失效了,这时候就通过打标签方式,通过不同算法给页面算一个值,然后发给浏览器。
每次你问我这个值有没有发生改变,但这个算法每个浏览器都不一样,如果你不好理解,可以理解为做了HTML5给客户端,每次拿HTML5来问我对不对,但是它其实不是做HTML5加密出来的。
上面两种缓存协商都有一个问题,因为要发起协商,我发给你,你再发给我,虽然没有发生任何数据的产生,但是至少我返回了一个数据,证明你要给我建一个TCP三次握手和建立Http,这会占用我的资源。
4.2.3 基于Expires缓存协商cedilla消灭连接

第三次缓存协商就是基于过期时间,这个是针对运维的,对于开发知道就行了。那么客户端和服务器时间不同步怎么办?其实浏览器很聪明,它还有一个Cache—Control,它会算一个本地头部时间,告诉你文件生存周期多久,不管你客户端时间对不对,你都能正确使用过期时间。
4.3 你真的会刷新吗?

如果有了这些缓存,我们就来看一下到底会不会使用浏览器刷新。比如火狐浏览器有一个刷新按钮,你按刷新按钮的时候,这个时候对于基于***修改时间和打标签的方式就会受影响。
但是基于过期时间是不受影响的,所以说很多时候我只要设了一年过期,你狂点F5是没有用的。那么怎么办呢?强制刷新,ctrl+F5强制刷新,浏览器这时候就会发起一个全新的请求,不会使用任何缓存,所以我之前看到很多前端开发人员不会使用刷新,我觉得好尴尬,点了半天不起作用。跑过来问运维,运维说你怎么刷新的,F5,F5不行,要ctrl+F5。
这就延伸出另外一个问题,比如我给某个资源设过期时间一年,但是不到一年我想改怎么办,你总不能让我通知几千万用户按一下ctrl+F5吧。有几种方式,***是直接修改文件名,第二是使用时间戳。
当然这个时候如果还用到CDN的时候,就要注意了,我们做CDN配置的时候有两种,一种是URL带时间戳,一种是不带时间戳,URL做缓存的时候不带时间戳,那你就只能改名了,要不然你还要在CDN做强制刷新,当然也可以,不是说不可以。你做一个小系统,你直接调CDN做缓存刷新也是可以的,就比较费劲了,这个就看需求。
5、关于工作中的一些感悟
我看大家在座的都工作时间比较久,大家可以想工作时间早和工作时间久回答问题发生什么变化。我刚工作的时候别人问我问题我马上回答,我直接回答说这样是对的,等工作时间久了别人问我问题我会回答不一定,无论什么问题回答都是不一定。
为什么?要看你的需求,不同需求我的回答就是不一样的。所以后来别人说班长问什么你都不一定,我说是的,你以前学技术的时候,你只需要做到这个就可以了,当你知道多的时候就会发现就是不一定。我们为开始学的时候搞一个负载均衡,我觉得这就是集群。后来所有东西都是不一定,一定要看你的需求。
更有甚者在群里问,班长支撑千万PV是什么架构?“不一定”。这就很难说了,这一定要看需求的,你说一个小型网站,就一个Http页面,支持几十亿PV都没有问题。所以要看你的业务类型,如果说电商那就复杂了,电商的体系体量整个业务就很复杂,所以不同业务,不同架构就是不一样的。
这里延伸出另外一个问题,大家现在工作不好干,为什么不好干?不管你是做开发还是做运维,现在互联网发展都开始有场景化,你之前是做电商的,不管是开发还是运维,你跳一家游戏公司,想薪资翻倍不可能,因为你的经验复制不过去。
你之前是做支付接口开发的,现在跳到Web商城,没有支付是完全不同的。咱们做运维也是一样的,所以咱们要不停学习,如果不学习只能慢慢被淘汰。