【51CTO.com原创稿件】俗话说“三个臭皮匠,顶个诸葛亮”,多个比较弱的人若能有一种方法集中利用他们的智慧,也可以达到比较好的效果。
其实,集成学习的思路亦是如此——在对新的实例进行分类的时候,把若干个单个分类器集成起来,通过对多个分类器的分类结果进行某种组合来决定最终的分类,以取得比单个分类器更好的性能。
如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。
目前,集成学习的常用算法有三种,分别为:bagging,boosting和stacking。
Bagging 算法,或称 Bootstrap Aggregating 算法。大家通常使用 Bagging 这个名字,是因为它是综合了Bootstrapping和Aggregagtion而形成的一个组合模型。
Bagging算法主要对样本训练集合进行随机化抽样,通过反复的抽样训练新的模型,最终在这些模型的基础上选取综合预测结果。
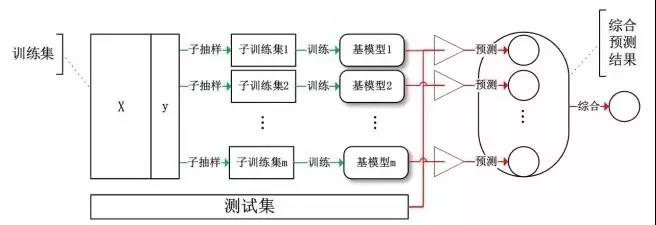
Bagging
基于Bagging的代表算法有随机森林
Boosting(提升)算法,是常用的有效的统计学习算法,属于迭代算法。Boosting和Bagging的区别在于是对加权后的数据利用弱分类器依次进行训练。
Boosting通过不断地使用一个弱学习器弥补前一个弱学习器的“不足”的过程,来串行地构造一个较强的学习器,这个强学习器能够使目标函数值足够小。
Boosting
Boosting系列算法里***算法主要有AdaBoost算法和GBDT算法。
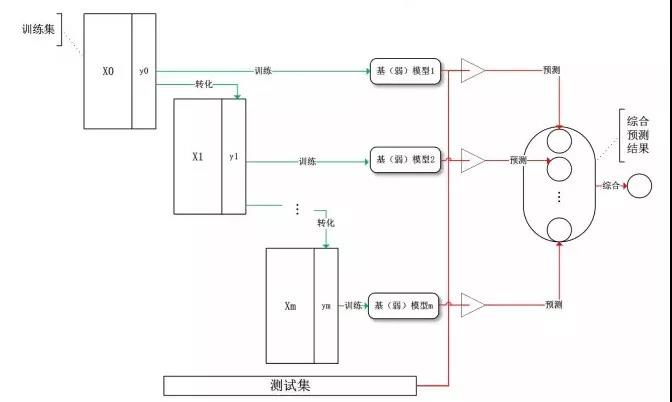
Stacking(堆叠)算法是通过一个元分类器或者元回归器来整合多个分类模型或回归模型的集成学习技术。基础模型利用整个训练集做训练,元模型将基础模型的特征作为特征进行训练。
Stacking
基础模型通常包含不同的学习算法,因此stacking通常是异质集成。
对数值型输出,最常见的结合策略是使用平均法。
-
简单平均法
-
加权平均法
但是对于规模比较大的集成来说,权重参数比较多,较容易导致过拟合。加权平均法未必一定优于简单平均法。
一般而言,在个体学习器性能相差较大时,宜使用加权平均法,而在个体学习器性能相近时,宜使用简单平均法。
相对多数投票法:预测为得票最多的标记。若同时有多个标记获得***票,则从中随机选取一个。
假设我们的预测类别是,对于任意一个预测样本x,我们的个弱学习器的预测结果分别是。 最简单的投票法是相对多数投票法,也就是我们常说的少数服从多数,也就是个弱学习器的对样本X的预测结果中,数量最多的类别为最终的分类类别。如果不止一个类别获得***票,则随机选择一个做最终类别。
绝对多数投票法:若某标记得票过半数,则预测为该标记;否则拒绝预测。
与相对多数投票法相比较为复杂,也就是我们常说的要票过半数。在相对多数投票法的基础上,不光要求获得***票,还要求票过半数。
加权投票法:算法更为复杂,和加权平均法一样,每个弱学习器的分类票数要乘以一个权重,最终将各个类别的加权票数求和,***的值对应的类别为最终类别。
当训练数据很多时,为了尽量缩小误差,可利用一种更为强大的结合策略,便是使用“学习法”,即通过另一个学习器来进行结合。
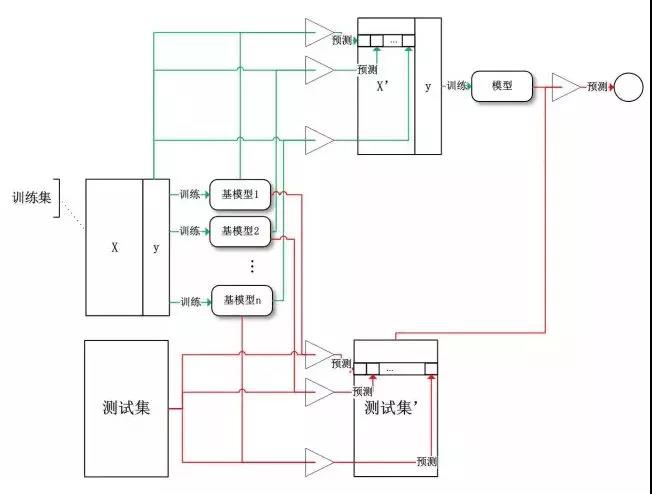
对于学习法,代表方法是stacking,当使用stacking的结合策略时, 我们不是对弱学习器的结果做简单的逻辑处理,而是再加上一层学习器,也就是说,我们将训练集弱学习器的学习结果作为输入,将训练集的输出作为输出,重新训练一个学习器来得到最终结果。
在这种情况下,我们将弱学习器称为初级学习器,将用于结合的学习器称为次级学习器。对于测试集,我们首先用初级学习器预测一次,得到次级学习器的输入样本,再用次级学习器预测一次,得到最终的预测结果。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】