根据Gartner所言,到2020年,每个智慧城市将使用约13.9亿辆联网汽车,这些汽车配备物联网传感器和其他设备。城市中的车辆定位和行为模式分析将有助于优化流量,更好的规划决策和进行更智能的广告投放。例如,对GPS汽车数据分析可以允许城市基于实时交通信息来优化交通流量。电信公司正在使用移动电话定位数据,识别和预测城市人口的位置活动趋势和生存区域。
本文,我们将讨论在数据处理管道中使用Spark Structured Streaming对Uber事件数据进行聚类分析,以检测和可视化用户位置实践。(注:本文所用数据并非Uber内部实际用户数据,文末附具体代码或者示例获取渠道)
首先,我们回顾几个结构化流媒体涉及的概念,然后探讨端到端用例:
使用MapR-ES发布/订阅事件流
MapR-ES是一个分布式发布/订阅事件流系统,让生产者和消费者能够通过Apache Kafka API以并行和容错方式实时交换事件。
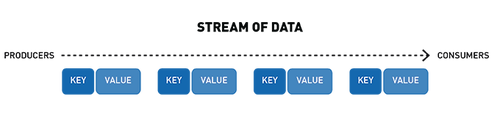
流表示从生产者到消费者的连续事件序列,其中事件被定义为键值对。
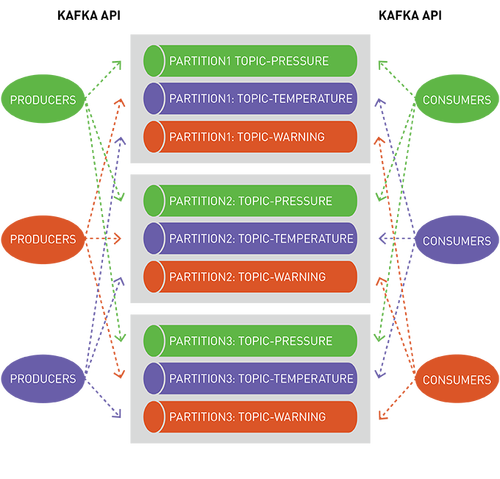
topic是一个逻辑事件流,将事件按类别区分,并将生产者与消费者分离。topic按吞吐量和可伸缩性进行分区,MapR-ES可以扩展到非常高的吞吐量级别,使用普通硬件可以轻松实现每秒传输数百万条消息。
你可以将分区视为事件日志:将新事件附加到末尾,并为其分配一个称为偏移的顺序ID号。
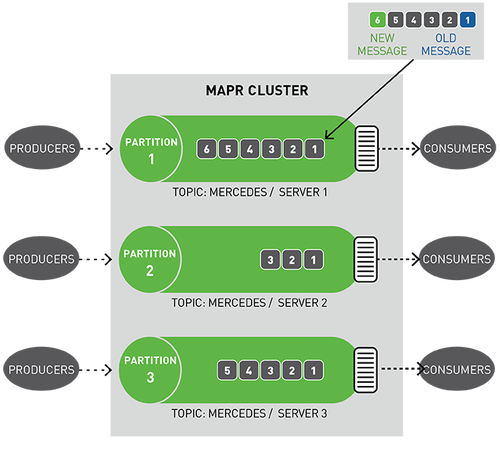
与队列一样,事件按接收顺序传递。
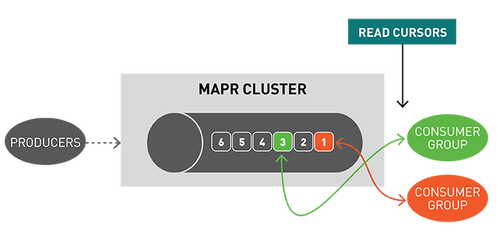
但是,与队列不同,消息在读取时不会被删除,它们保留在其他消费者可用分区。消息一旦发布,就不可变且永久保留。
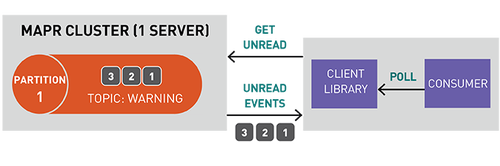
读取消息时不删除消息保证了大规模读取时的高性能,满足不同消费者针对不同目的(例如具有多语言持久性的多个视图)处理相同消息的需求。
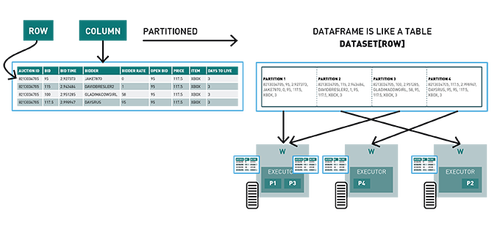
Spark数据集,DataFrame,SQL
Spark数据集是分布在集群多个节点上类对象的分布式集合,可以使用map,flatMap,filter或Spark SQL来操纵数据集。DataFrame是Row对象的数据集,表示包含行和列的数据表。
Spark结构化流
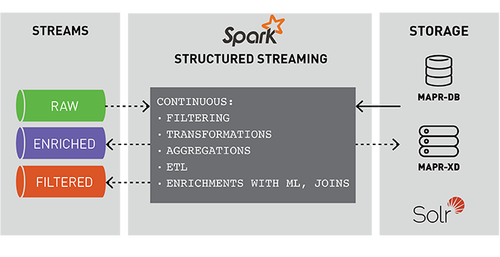
结构化流是一种基于Spark SQL引擎的可扩展、可容错的流处理引擎。通过Structured Streaming,你可以将发布到Kafka的数据视为无界DataFrame,并使用与批处理相同的DataFrame,Dataset和SQL API处理此数据。
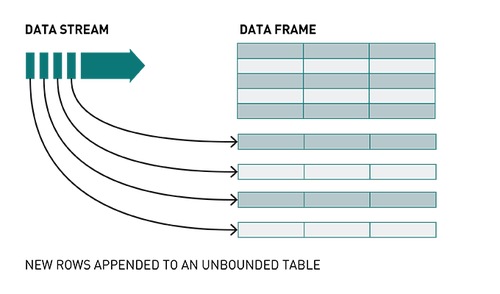
随着流数据的不断传播,Spark SQL引擎会逐步持续处理并更新最终结果。
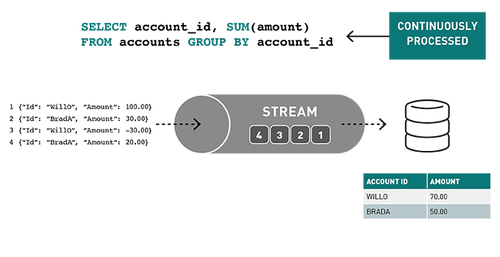
事件的流处理对实时ETL、过滤、转换、创建计数器、聚合、关联值、丰富其他数据源或机器学习、持久化文件或数据库以及发布到管道的不同topic非常有用。
Spark结构化流示例代码
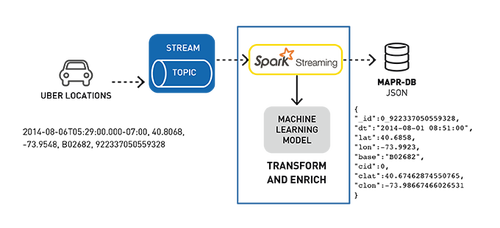
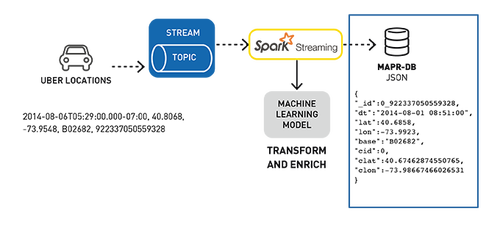
下面是Uber事件数据聚类分析用例的数据处理管道,用于检测位置。
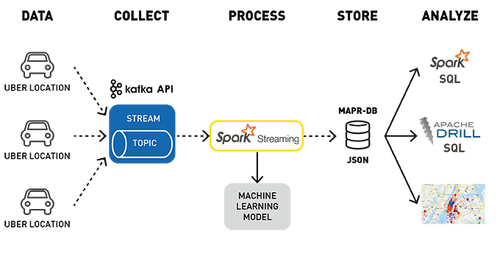
使用Kafka API将行车位置数据发布到MapR-ES topic
订阅该topic的Spark Streaming应用程序:
- 输入Uber行车数据流;
- 使用已部署的机器学习模型、集群ID和位置丰富行程数据;
在MapR-DB JSON中存储转换和丰富数据。
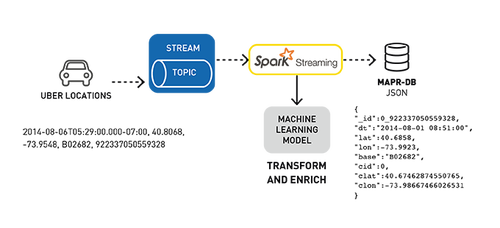
用例数据示例
示例数据集是Uber旅行数据,传入数据是CSV格式,下面显示了一个示例,topic依次为:
日期/时间,纬度,经度,位置(base),反向时间戳
2014-08-06T05:29:00.000-07:00,40.7276,-74.0033,B02682,9223370505593280605
我们使用集群ID和位置丰富此数据,然后将其转换为以下JSON对象:
- {
- "_id":0_922337050559328,
- "dt":"2014-08-01 08:51:00",
- "lat":40.6858,
- "lon":-73.9923,
- "base":"B02682",
- "cid":0,
- "clat":40.67462874550765,
- "clon":-73.98667466026531
- }
加载K-Means模型
Spark KMeansModel类用于加载k-means模型,该模型安装在历史uber行程数据上,然后保存到MapR-XD集群。接下来,创建集群中心ID和位置数据集,以便稍后与Uber旅行位置连接。

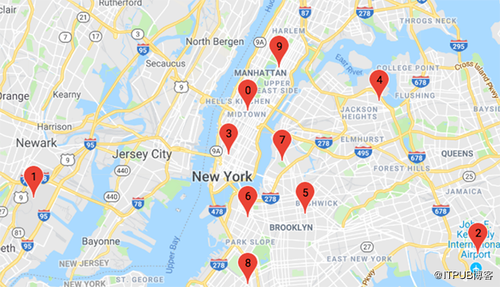
集群中心下方显示在Zeppelin notebook中的Google地图上:
从Kafka的topic中读取数据
为了从Kafka读取,我们必须首先指定流格式,topic和偏移选项。有关配置参数的详细信息,请参阅MapR Streams文档。

这将返回具有以下架构的DataFrame:

下一步是将二进制值列解析并转换为Uber对象的数据集。
将消息值解析为Uber对象的数据集
Scala Uber案例类定义与CSV记录对应的架构,parseUber函数将逗号分隔值字符串解析为Uber对象。

在下面的代码中,我们使用parseUber函数注册一个用户自定义函数(UDF)来反序列化消息值字符串。我们在带有df1列值的String Cast的select表达式中使用UDF,该值返回Uber对象的DataFrame。

使用集群中心ID和位置丰富的Uber对象数据集
VectorAssembler用于转换并返回一个新的DataFrame,其中包含向量列中的纬度和经度要素列。


k-means模型用于通过模型转换方法从特征中获取聚类,该方法返回具有聚类ID(标记为预测)的DataFrame。生成的数据集与先前创建的集群中心数据集(ccdf)连接,以创建UberC对象的数据集,其中包含与集群中心ID和位置相结合的行程信息。


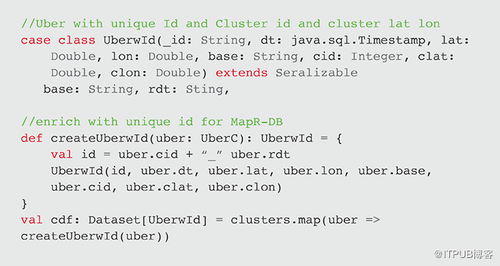
最后的数据集转换是将唯一ID添加到对象以存储在MapR-DB JSON中。createUberwId函数创建一个唯一的ID,包含集群ID和反向时间戳。由于MapR-DB按id对行进行分区和排序,因此行将按簇的ID新旧时间进行排序。 此函数与map一起使用以创建UberwId对象的数据集。
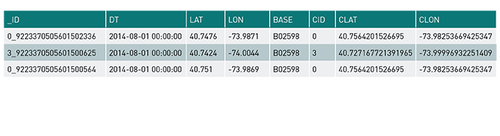
接下来,为了进行调试,我们可以开始接收数据并将数据作为内存表存储在内存中,然后进行查询。

以下是来自 %sqlselect * from uber limit 10 的示例输出:
现在我们可以查询流数据,询问哪段时间和集群内的搭乘次数最多?(输出显示在Zeppelin notebook中)
- %sql
SELECT hour(uber.dt) as hr,cid, count(cid) as ct FROM uber group By hour(uber.dt), cid
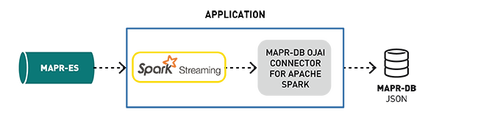
Spark Streaming写入MapR-DB
用于Apache Spark的MapR-DB连接器使用户可以将MapR-DB用作Spark结构化流或Spark Streaming的接收器。
当你处理大量流数据时,其中一个挑战是存储位置。对于此应用程序,可以选择MapR-DB JSON(一种高性能NoSQL数据库),因为它具有JSON的可伸缩性和灵活易用性。
JSON模式的灵活性
MapR-DB支持JSON文档作为本机数据存储。MapR-DB使用JSON文档轻松存储,查询和构建应用程序。Spark连接器可以轻松地在JSON数据和MapR-DB之间构建实时或批处理管道,并在管道中利用Spark。

使用MapR-DB,表按集群的键范围自动分区,提供可扩展行和快速读写能力。在此用例中,行键_id由集群ID和反向时间戳组成,因此表将自动分区,并按最新的集群ID进行排序。
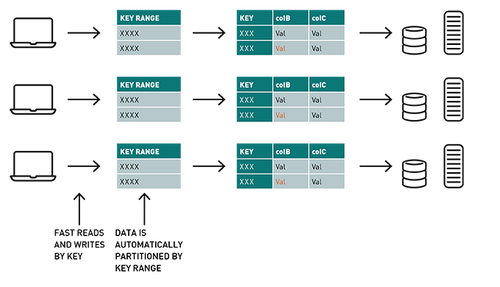
Spark MapR-DB Connector利用Spark DataSource API。连接器体系结构在每个Spark Executor中都有一个连接对象,允许使用MapR-DB(分区)进行分布式并行写入,读取或扫描。
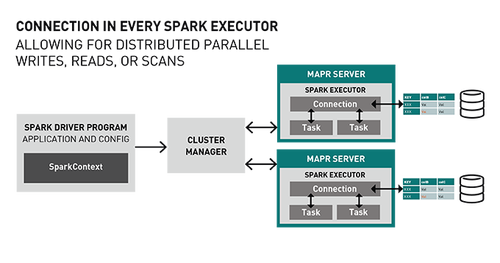
写入MapR-DB接收器
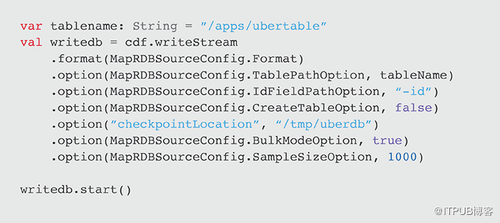
要将Spark Stream写入MapR-DB,请使用tablePath,idFieldPath,createTable,bulkMode和sampleSize参数指定格式。以下示例将cdf DataFrame写到MapR-DB并启动流。
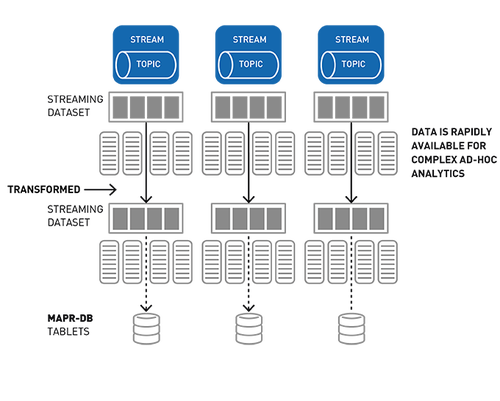
使用Spark SQL查询MapR-DB JSON
Spark MapR-DB Connector允许用户使用Spark数据集在MapR-DB之上执行复杂的SQL查询和更新,同时应用投影和过滤器下推,自定义分区和数据位置等关键技术。
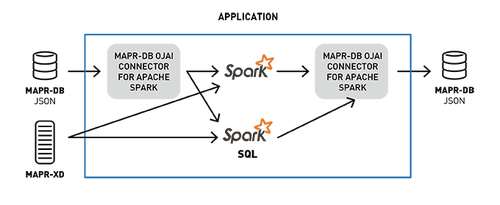
将数据从MapR-DB加载到Spark数据集中
要将MapR-DB JSON表中的数据加载到Apache Spark数据集,我们可在SparkSession对象上调用loadFromMapRDB方法,提供tableName,schema和case类。这将返回UberwId对象的数据集:


使用Spark SQL探索和查询Uber数据
现在,我们可以查询连续流入MapR-DB的数据,使用Spark DataFrames特定于域的语言或使用Spark SQL来询问。
显示第一行(注意行如何按_id分区和排序,_id由集群ID和反向时间戳组成,反向时间戳首先排序最近的行)。
- df.show
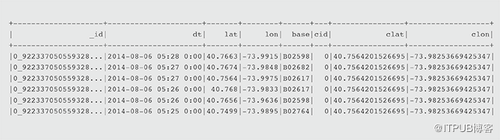
每个集群发生多少次搭乘?
- df.groupBy("cid").count().orderBy(desc( "count")).show

或者使用Spark SQL:
- %sql SELECT COUNT(cid), cid FROM uber GROUP BY cid ORDER BY COUNT(cid) DESC
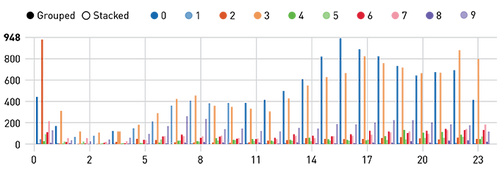
使用Zeppelin notebook中的Angular和Google Maps脚本,我们可以在地图上显示集群中心标记和最新的5000个旅行的位置,如下可看出最受欢迎的位置,比如位于曼哈顿的0、3、9。
集群0最高搭乘次数出现在哪个小时?
- df.filter($"\_id" <= "1")
- .select(hour($"dt").alias("hour"), $"cid")
- .groupBy("hour","cid").agg(count("cid")
- .alias("count"))show
一天中的哪个小时和哪个集群的搭乘次数最多?
- %sql SELECT hour(uber.dt), cid, count(cid) FROM uber GROUP BY hour(uber.dt), cid
按日期时间显示uber行程的集群计数
- %sql select cid, dt, count(cid) as count from uber group by dt, cid order by dt, cid limit 100
总结
本文涉及的知识点有Spark结构化流应用程序中的Spark Machine Learning模型、Spark结构化流与MapR-ES使用Kafka API摄取消息、SparkStructured Streaming持久化保存到MapR-DB,以持续快速地进行SQL分析等。此外,上述讨论过的用例体系结构所有组件都可与MapR数据平台在同一集群上运行。
代码:
你可以从此处下载代码和数据以运行这些示例:https://github.com/caroljmcdonald/mapr-spark-structuredstreaming-uber
机器学习notebook的Zeppelin查看器:https://www.zepl.com/viewer/github/caroljmcdonald/mapr-spark-structuredstreaming-uber/blob/master/notebooks/SparkUberML.json
Spark结构化流notebook的Zeppelin查看器:https://www.zepl.com/viewer/github/caroljmcdonald/mapr-spark-structuredstreaming-uber/blob/master/notebooks/SparkUberStructuredStreaming.json
SparkSQL notebook的Zenpelin查看器:https://www.zepl.com/viewer/github/caroljmcdonald/mapr-spark-structuredstreaming-uber/blob/master/notebooks/SparkUberSQLMapR-DB.json
此代码包含在MapR 6.0.1沙箱上运行的说明,这是一个独立的VM以及教程和演示应用程序,可让用户快速使用MapR和Spark。