python爬虫正则表达式介绍
元字符
^ $ * + . | ? {} [] () 这就是元字符了,学会这些应该就够你用的了。
python中的正则表达式通过import re 来使用。
1、python爬虫正则表达式,[] 常用来指定一个字符集,如:[abc ]; [a-z] 里面所有的字母会被一一匹配 例子:
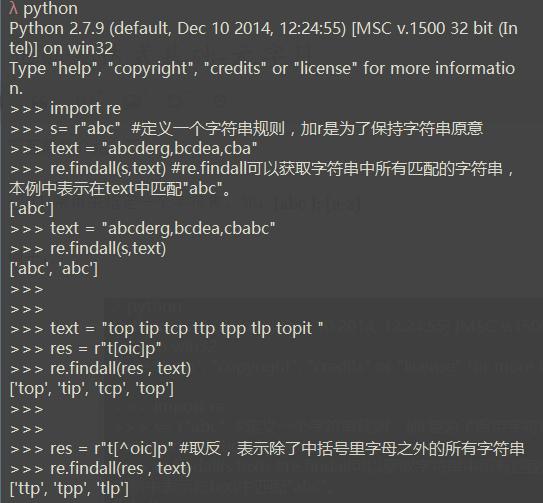
面例子都解释的很清楚了,我就不重复一行行解释了。 注: 示例中^表示取反。
[a-z]表示 从字母a到z所有的字母。
[0-9]等价于[0123456789] 也可以用d 表示。 所有其它的元字符在[]中将失去原有的意义,比如示例中的^在[]表示取反。
2、^ 表示匹配字符串的开头。在多行模式下匹配每一行的开头。
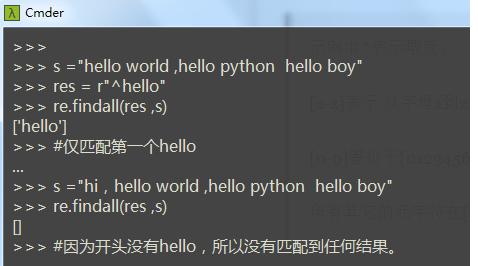
注:^一般放在字符串开头
3、$ 表示匹配字符串的结尾。在多行模式下匹配每一行的尾部。
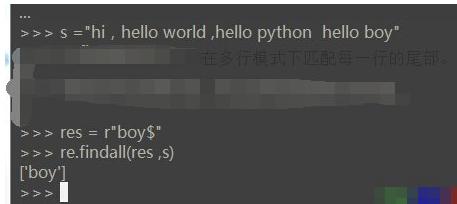
注:$一般放在字符串结尾。
上面三个可以看成一个小块,你记住了吗?理解了吗?看明白了吗?还有你自己敲一遍代码了吗?????!!!!一定自己尝试敲一遍代码!
好接下来,继续 由于元字符是特殊字符,如果我们要匹配元字符本身的字符应该怎么办呢? 当我们想把元字符变为为普通符号是可以使用(反斜杠)进行转义。
4、反斜杠后面可以加不同的字符以表示特殊意义。 也可用于取消所有元字符,变为普通符号。

你只要能记住加黑加粗的其它的我打赌你肯定也全会了。所以记住加粗的,自己把下面的代码敲一遍。 示例

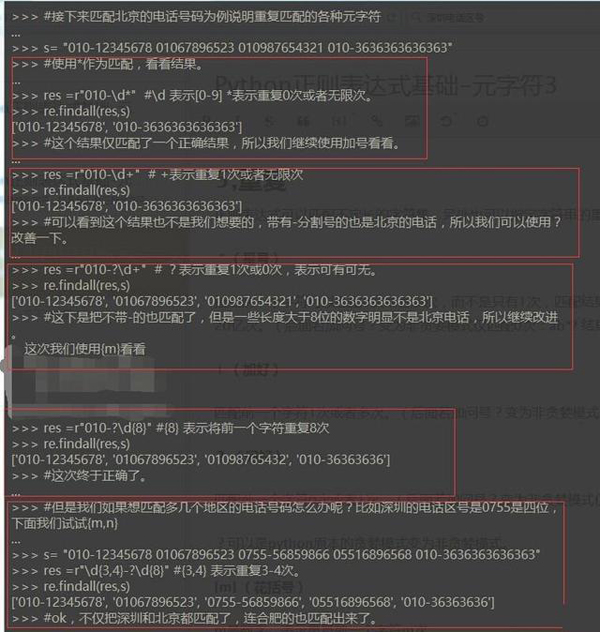
正则表达式可以匹配不定长的字符集,另外也可以指定字符串的重复次数。
* (星号) 指定前一个字符可以匹配0次或者多次,而不是只有1次,匹配结果会尽可能的重复多次***不超过20亿次。(后面若加问号?变为非贪婪模式仅匹配0次:ab*? 结果为a)
+ (加号) 匹配前一个字符1次或者多次。(后面若加问号?变为非贪婪模式仅匹配1次:ab+? 结果为ab)
? (问号) 匹配前一个字符0次或者1次。(后面若加问号?变为非贪婪模式仅匹配0次:ab?? 结果为a) ?可以是python原本的贪婪模式变为非贪婪模式。
{m} (花括号) m是数字,表示重复前一个字符m次。
{m,n} 表示重复前一个字符m-n次。若省略m则表示0-n次,若省略n表示m到***次。(后面若加问号?变为非贪婪模式仅匹配0次:ab{2,100}? 结果为abb)
() | . . 它匹配除了换行字符外的任何字符,在 alternate 模式(re.DOTALL)下它甚至可以匹配换行
| 代表左右表达式任意匹配一个。a|b 匹配a或者匹配b 。 如果没有被(...)括起来它的范围是整个正则表达式。
(...) 将正则表达式分组,每个分组为一个整体,将优先返回分组内的数据