在如今的云计算时代,计算的云化和分布式应用给运维工作带来了很大的挑战,让人海战术在运维面前失灵,所以基于算法和机器学习的智能运维(AIOps)必将是业务运维场景下的大势所趋。业界有个说法,公有云***的竞争是基于运维能力的综合竞争。现在各大公有云服务商也都在积极探索AIOps,此次我们采访了华为云应用运维域专家,为我们揭秘华为云的智能运维实践。
华为云的运维技术演进
华为云很早就在实践智能运维了,包括最早的IaaS运维,以及近几年的PaaS运维、服务洞察。只是之前的叫法不是现在谈论的“智能运维”,而是智能监控、应用分析、智能分析、自动诊断与调优、自动化运维等,华为云的AIOps在SRE和云服务中都有应用和实践。
前几年,华为云主要聚焦在企业云、私有云、混合云等建设,运维能力建设围绕数据中心,在统一运维架构、运维研发化的基础上,重点发展运维的标准化、自动化和智能化。
2017年华为Cloud BU成立,正式进入公有云市场。在这个阶段,SRE在统一运维架构基础上,整合了各种运维工具,形成了公有云管理面的统一运维。与此同时APM、AOM、CES等云服务直接面向云租户提供应用运维能力。
华为云专家华为云专家认为,传统运维和AIOps是紧密联系的,在数据分析层面二者也有些重叠区域,并且AIOps也依赖传统运维的数据基础、计算处理等。二者之间的区别主要体现在数据规模和实时性上。当云实体的规模扩大、应用栈的多样化、应用架构的容器化、微服务化后,运维对用户体验管理和业务高可用性越来越不可知性。而云服务对监测的实时性、反馈控制的及时性、故障预测、故障自愈等要求也是AIOps所擅长的。
如何使用AI利器
在华为云专家看来,针对不同的产品或者项目,构建AIOps所依赖的关键技术有所不同,比如企业资源故障预测项目与公有云上的应用性能监测服务就有比较大的区别。以广义的APM为IT运维的范围,一般涉及到以下关键点:
- 监测对象的完整建模:各层物理实体、虚拟实体与应用服务的映射关系;
- 监测数据的采集与预处理:比如元数据是否完备,海量数据的高效访问与扩展等;
- 子领域的算法选择:合理划分出问题域的边界,结合领域知识筛选或设计出合适的算法,并予与验证。
在华为云的实践中,AI技术主要应用在以下几个方面:
- 预测的智能化
- 诊断的智能化
- 自愈的智能化
- Agent的智能化
上面几个方面涵盖了运维闭环模型:监测感知 – 分析洞察 – 优化控制。
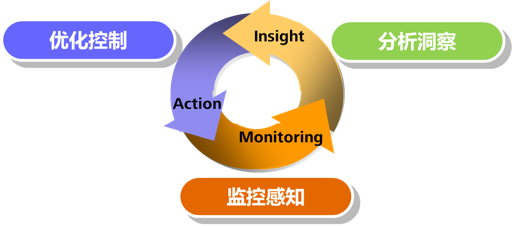
以传统运维中最常见的挑战——告警风暴——为例,静态阈值、多段式组合阈值、基线化阈值等基于统计计算的方法都难以满足应用运维的要求了。另一方面,云化后的应用所涉及计算节点,服务endpoint、指标等更多,不可能完全依靠人工来设置。这时候基于动态阈值或时序数据行为模式分析的AI方法就派上用场了。
所以AI技术首先适合用于复杂的场景中,尤其是各种可能组合数量远远超越了人力所能企及的范围,还比如复合因素下的趋势预测(磁盘寿命、性能指标、容量)、故障定界定位、根因分析等。
其次AI技术在一些时效性要求高的场景中得到应用,比如基于指标、日志、事件的告警。应用或者系统出现异常后,是需要***时间通知到运维值守人员的。还比如云服务的弹性伸缩(auto-scaling),是需要根据一些监测指标、服务模型、规则以及算法智能地及时做出适当调整动作。
除了中心化的AI技术应用外,数据采集端侧(Agent)的智能化也是一个重要发力领域,也包括IoT场景下的边缘节点(edge node)。在万物感知、万物互联、万物智能的趋势下,我们可以把训练好的模型发放到需要的Agent端。Agent智能化可以解决端侧更高的响应实时性要求,减少数据上传的网络带宽消耗、存储成本、计算成本等。
下图是华为云面向租户的立体运维平台,实际上是一个基于应用运维生态的大解决方案。这种统一、开放的云运维平台可以支撑华为云的底座运维、上百种云服务的SLA保障和运维,帮助客户监测管理部署在华为公有云上的业务应用。
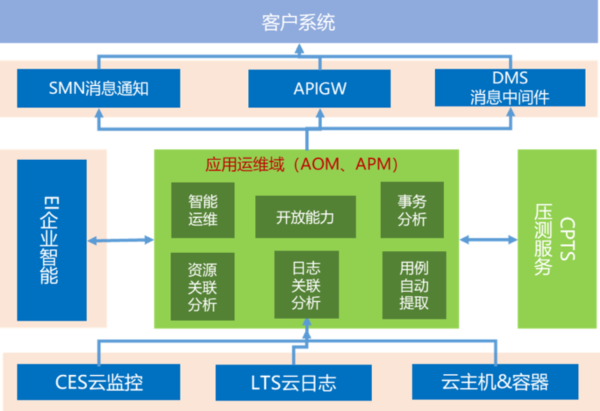
在运维工具和平台的构建过程中,华为云大量采用了开源项目,比如ELK、调用链有关的PinPoint、Zipkin、OpenTracing等规范、StatsD和Prometheus等数据接口规范、Spark、TensorFlow、MXNet等。
数据的收集与处理
大数据是AI的黑土地,前提是数据量要足够多。华为云针对运维目的,主要收集下面这些性能数据:
- 指标数据(metrics):既有IaaS层资源指标,也有PaaS层应用资源指标,客户所用云服务业务指标、客户业务自定义指标(由客户根据自身需求主动上报)。
- 日志数据(logs):客户指定的业务和各种中间件的运行日志
- 调用链数据(traces):客户通过非侵入式方法获得的调用链数据,或者客户开发应用在代码中引入SDK或者直接上报的调用链数据。
- 事件及告警(events&alerts):客户应用主动上报的各种事件和直接告警信息,还有根据预定义规则产生的事件和告警。
- 网络包数据(packets):主要是虚拟网络、容器网络中面向应用的网络性能数据。
这些数据根据自身特点,选择不同的存储方式,比如Cassandra、HDFS、ElasticSearch、GaussDB等。具体处理主要包括:
- 流式计算:主要用于指标、日志的告警,调用链分析;
- 离线计算:特定时间周期内的聚合计算、关联分析、模型训练等;
- 内存计算:为部分实时性要求高的算法所用。
区别于以前的运维,当前把很多指标数据中的一些维度属性和IaaS、PaaS层的基础信息结合起来形成面向应用的元数据集,和传统的CMDB有些类似,但粒度更细。其目的是为面向应用的数据分析提供各种可能的“关系网”。
AIOps落地之难点
AIOps面临的技术挑战主要有大量数据的获取、结合专业领域知识的算法验证、多种算法组合应用、新方法的探索以及服务化的工程化难度。
有了数据后,针对特定问题域去验证或者创新算法就需要领域专家和算法专家通力合作,找到合适的方法或者方法组合是很有挑战性的。华为云在弹性伸缩算法、事务黑盒分析、基于异常检测的智能告警和调用链洞察分析等方面采用机器学习进行了探索。
- 面向应用SLA实现容器的弹性伸缩,除了支持指标预定义条件的scaling外,还研究实现了基于强化机器学习算法的Auto-Scaling,为复杂的大规模应用提供了更智能选择。
- 在利用网络包分析推导应用调用关系及性能的BlackBox分析领域,经过理论分析和原型推导验证,华为云尝试过很多创新,***利用Hierarchical Clustering实现了服务间的因果路径推导,准确率基本达到了90~95%以上。分析结果以传统应用拓扑数据格式输出,展示效果近似于Whitebox方法得到的应用拓扑,可以感知整个应用的性能态势和识别性能瓶颈,对一些拥有legacy IT资产的客户监测需求特别适用。
- 调用链是云上应用性能诊断的重要一环。从调用链中先解析feature,利用聚类方法发现模式,针对每类事务做分钟级聚合,结合移位环算法实现10分钟的统计聚合,***实现对事务的“好”与“坏”的智能判断。Dashboard上采用heat map和histogram形式予以展示和引导,提供与人友好的应用性能直观洞察能力。
AIOps:让AI成为得力的助手
尽管在一些子领域或者单点技术上AIOps获得了一些进展,运维域AIOps还有很大的空间有待发展,离真正做到无人值守、NoOps还有很大的现实差距。比如复杂大系统中智能RCA分析、可信自愈能力、面向机器理解的无监督学习、智能化下沉到端侧等都有待业界共同努力。
华为云专家认为,IT运维是个很大的范畴,完全不用人工运维,即无人值守只会存在某些特定的小场景下。而从整个系统来看,一定需要人来做更高阶的工作,参与者也不会只限于操作者或者管理员,还会涉及DevOps、业务主管等。
这是一个融合的世界,真正的有机系统,非黑即白的界线会越来越模糊,未来世界也一定是人主导,而不会是机器主宰的。在应用运维领域,人不会被AI简单取代,而是利用AI辅助人类做那些自己不擅长或者不愿意做的事情。
据了解,2018华为全联接大会将于10月份在上海召开,届时将首发华为AI战略和全栈全场景的解决方案,并携合作伙伴带来更多诸如“秦渲云”这样AI、云、大数据、5G、IoT、视频等在各行业的创新与实践,惠及更多开发者人群,“+智能,见未来”我们拭目以待。