【导读】谈到人工智能(特别是计算机视觉领域),大家关注的都是这一领域不断取得的进步,然而人工智能到底发展到什么程度了?AI 已经成为***的了吗?Heuritech 的 CTO Charles Ollion 希望通过他的文章可以揭露一些当前的真实情况。接下来就让我们一起看看这位作者都谈了什么内容吧!

作者基于 Xkcd 的漫画改编
最近,我读了 Pete Warden 的一篇文章,这篇文章介绍了一种可以辨别植物疾病的分类器。在辨别病害类型方面,这个分类器的精确度要比人类肉眼辨别的精确度高的多。但是,这个分类器在面对一张随机不含有植物的图片时会给出一个非常惊人的错误结果(如下图所示:左图展现了分类器在真实植物上检测病害类型的良好效果;而右图,在指向计算机键盘时,一张随机的非植物图片,分类器仍会认为这是一种受损的作物)。然而这个错误,却不会发生在人类身上。

(来源:Pete Warden's blog —— What Image Classifiers Can Do About Unknown Objects)
上面的举例说明,计算机视觉系统的能力仍有别于人类的智力,下面我想通过一道测试题来进一步证明这一观点:
你知道当前人工智能系统最擅长做什么吗?
下面有五个不同的计算机视觉问题,通过给出的输入与得到的输出结果,试着猜一下哪类问题是计算机视觉系统最容易解决的?哪类问题是非常困难的?
1.检测糖尿病性视网膜病变
输入:有约束的视网膜图片
输出:5个类别(健康型以及处于不同阶段与形式的病变状态)
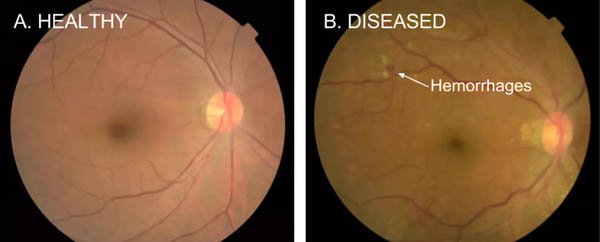
糖尿病性视网膜病变,一种影响到眼睛的糖尿病并发症
来源:https://ai.googleblog.com/2016/11/deep-learning-for-detection-of-diabetic.html
2.摄像头手势识别
输入:由摄像头拍摄的一系列短视频
输出:25种动作中可能性***的一种
(注:TwentyBN 现已发布了更丰富的数据集)
来源:TwentyBN
3.识别 Instagram 图片里的手提包
输入:Instagram 上的图片
输出:圈出图片里的手提包

4.识别行人
输入:由固定摄像机拍摄的图片
输出:圈出图中所有的行人

5.机器人抓取物体
输入:由固定摄像机拍摄的两张图
输出:机器人控制策略

左图为待抓取的物体,机器人上装有一台固定摄像机来学习如何抓取物体
来源:https://ai.googleblog.com/2017/10/closing-simulation-to-reality-gap-for.html
然而真相是?
- 糖尿病性视网膜病变:这类识别器是容易实现的,因为输入和输出都是有约束的(谷歌在他们的报道中声明已经实现并有良好表现了)。但当把这一系统投入到实际应用时,困难出现了。用户的体验以及系统与医生的配合是关键问题,因为对不同类型结果的判定可能会有失偏颇。
- 摄像头手势识别:这个问题相对来说很好定义,但多变性增加了它的难度:这些由摄像头拍摄的视频中,人们的距离不同,手势持续时间不同,等等... 此外,在对视频资料进行分析训练时,随之产生的还有诸多的工程问题。不得不说这个问题是非常困难的,但已经得到了解决。
- 识别 Instagram 图片里的手提包:这个问题看起来似乎很容易解决,但输入的图片是没有约束的,而且类别的定义也非常广(手提包有很多种形态,没有一个明确的视觉模式,因此很有可能被识别成很多其它物体)。这使得问题变的非常困难,看看下面图就明白了。

由经过手提包识别训练的模型给出的识别结果
我们的训练数据中没有“斧子”的图片作为反例,而斧子的头部和模型学习过的手提包的图像非常相似。它是褐色的,有着手提包的形状和大小,而且被握在手里。
然后我们就这样放弃了吗?不,我们可以通过主动学习来解决这个问题,即对模型给出的错误判断进行标记,然后把这些错误例子反馈给模型继续训练。但凭借现有的技术来说,想像 Instagram 中的图片,如此开放的领域上达到***的效果,仍然是一项巨大的挑战。
对于我们人类来讲,关于糖尿病相关的工作很难,但辨认斧子和手提包却很容易,这主要原因是斧子对我们来说是一种极为普遍的存在,一种大家都知道的常识,并且这些内容超出了输入到系统数据的范围。
- 识别摄像头中的行人:这类问题很简单:输入非常受限(固定摄像机),而且类别(行人)也很标准。可能会存在目标被遮挡等相关问题,但总体来说这个问题很容易就可以解决。不过,如果对这个问题稍作改动,就会变得困难很多:如摄像机是移动的;或从不同方位、角度、范围进行拍摄 —— 这个问题就变得更开放且棘手了。
- 机器人抓取物体:这个问题是极其困难的。它超出了标准分类和回归问题的范围,因为输出是控制机器人的策略,通常使用强化学习来进行训练,与有监督学习相比,这种学习方法还不太成熟。此外,对象在大小、形状和抓取的方式上都会有所不同,可能还要借助语义的理解。但是这个问题可以由一个2岁的小孩子轻易解决(即使没有固定摄像头、背景完全相同这些设定),但对我们来说,让人工智能做这件事还有很长的路要走。
作者声明:如果不同意我给出的答案,我很乐于和大家讨论,因为在这个领域要学的知识很多,我不认为我知道所有问题的答案。
对计算机视觉与人工智能的期望
对计算机视觉系统和我们人类来说,“难度”这个概念是有很大不同的,这一点很容易引导我们对人工智能产生错误的期望。工程师和科研人员不得不从现实出发来对待人工智能系统在开放域的表现。
当前我们在对人工智能系统发展情况的理解上也还存在很多问题。以自动化驾驶为例:在有约束(例如:高速公路)下驾驶与无约束(如: 市区、小路... ...)下对驾驶存在着极大的区别。如今大多数企业都基于在没有司机操控下,通过自动驾驶汽车所行驶的里程数来对自动化驾驶水平进行评估。这也促使了测试者更乐于把汽车放到容易驾驶的环境里,但其实我们更应该做的是建立一些指标,重点关注扩大自动化驾驶汽车正常驾驶的范围。
更概括地来讲,我认为我们不应该再说什么“计算机视觉已经实现了。”这样的话了。如果我们有足够多已经标记了的数据和有约束的类别,小范围内的问题可能已经解决了。但若将世界范围的常识知识引入计算机视觉系统,这仍然是一个巨大的挑战。

ClevR,用于组合式语言和初级视觉推理的诊断数据集
其实现在很多的研究人员已经开始在进行这方面的研究了,也有一些研究领域正在蓬勃的发展着,例如:视觉推理、物理发现法则、通过无监督/自我监督进行表征学习等。AI 科技大本营在文末给大家列出了相关的研究文章,方便大家学习。
鉴于我对计算机视觉的研究与发展了解多一些,上述都是我关于这方面的一些看法,但我相信同样的理由也可以应用到其它机器学习问题上,特别是关于 NLP 应用深度学习与机器学习的研究领域。
看了作者的一些看法,也欢迎大家在 AI 科技大本营后台留言,和大家一起交流自己的看法~
原文链接:
https://medium.com/@CharlesOllion/whats-easy-hard-in-ai-computer-vision-these-days-e7679b9f7db7
参考阅读:
- A diagnostic dataset for compositional language and elementary visual reasoning
https://arxiv.org/abs/1612.06890
- Discovering Causal Signals in Images
http://openaccess.thecvf.com/content_cvpr_2017/papers/Lopez-Paz_Discovering_Causal_Signals_CVPR_2017_paper.pdf
- Interaction Networks for Learning about Objects, Relations and Physics
http://papers.nips.cc/paper/6417-interaction-networks-for-learning-about-objects-relations-and-physics
- Iterative Visual Reasoning Beyond Convolutions
https://arxiv.org/abs/1803.11189
- Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles
https://arxiv.org/pdf/1603.09246.pdf
- World Models
https://arxiv.org/pdf/1803.10122.pdf