无论你如何将Hadoop与Spark进行对比,无论Spark生态多么成熟和完善,其底层终归要基于HDFS,毕竟这是目前最成熟的分布式底层文件系统,几乎没有哪家公司愿意重新花费精力研发一个全新的文件系统。
本文将讨论Hadoop分布式文件系统(HDFS)的基本概念以及管理HDFS的十大Hadoop Shell命令。HDFS是Apache Hadoop框架的底层文件系统,是一个分布式存储框架,跨越数千种商用硬件。该文件系统提供容错、高吞吐、流数据访问以及高可靠性等功能。HDFS的体系架构适用于存储大量数据及快速处理,HDFS是Apache生态系统的一部分。
在此之前,我们先来了解Apache Hadoop框架,其主要包含以下几大模块:
- Hadoop Common——包含Hadoop其他模块所需的库和实用程序;
- HDFS——商用机存储数据的分布式文件系统,在集群中提供非常高的聚合带宽;
- Hadoop YARN ——资源管理平台,负责管理集群上的计算资源并使用它们调度用户应用程序;
- Hadoop MapReduce——用于大规模数据处理的编程模型。
Hadoop中的所有模块都设计了一个基本假设,即硬件故障(单个机器或整个机架)是显而易见的,因此应由Hadoop框架在软件应用程序中自动处理,Apache Hadoop的HDFS组件最初来自Google的MapReduce和Google File System(GFS)。
HDFS是Hadoop应用程序使用的主要分布式存储,HDFS集群主要由NameNode和DataNode组成。NameNode管理文件系统元数据,DataNode用于存储实际数据。
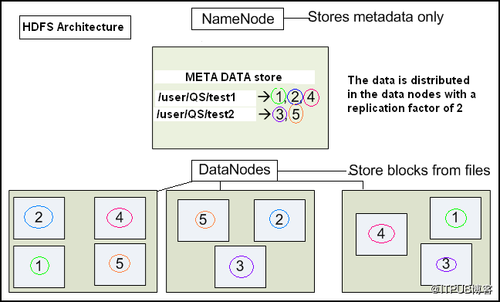
HDFS架构图解释了NameNode、DataNode和客户端之间的基本交互,客户端组件调用NameNode以获取文件元数据或修改,客户端直接使用DataNodes执行实际的文件I / O操作。HDFS可能存在一些用户感兴趣的显著特征:
非常适合使用低成本商用硬件进行分布式存储和处理。Hadoop具有可扩展性,容错性且易于扩展。MapReduce以其大量分布式应用程序的简单性和适用性而著称。HDFS则具有高度可配置性,默认配置足以满足大多数应用程序的需求。通常,仅需要针对非常大的集群调整默认配置;
- Hadoop是基于Java平台编写的,几乎在所有主要平台上都受支持;
- Hadoop支持shell和shell类命令与HDFS的通信;
- NameNode和DataNode具有内置Web服务器,可以轻松检查集群的当前状态;
- HDFS中经常实现新的功能和更新,以下列表是HDFS中可用的功能子集:
文件权限和身份验证;
Rackawareness:有助于在计划任务和分配存储时考虑节点的物理位置;
Safemode:管理主要用于维护的模式;
fsck:这是一个实用程序,用于诊断文件系统的运行状况以及查找丢失的文件或块;
fetchdt:这是一个用于获取DelegationToken并将其存储在本地系统文件中的实用程序;
Rebalancer:当数据在DataNode之间分布不均时,这是一个用于平衡集群的工具;
升级和回滚:软件升级后,可以在升级前回滚到上一状态,以防出现任何意外;
SecondaryNameNode:此节点执行命名空间的Checkpoint,并帮助将包含HDFS修改日志的文件大小保持在NameNode的特定限制内;
Checkpoint节点:此节点执行命名空间的Checkpoint,并有助于最小化存储在NameNode中的日志大小,其中包含对HDFS所做的更改,它还替换了以前由Secondary NameNode填充的角色或功能。作为替代方案,NameNode允许多个节点作为Checkpoint,只要系统没有可用(注册)的备份节点即可;
Backup节点:可以将其定义为Checkpoint节点的扩展。除了Checkpoint之外,它还用于从NameNode接收编辑流。因此,它维护自己命名空间的内存副本,始终与活动的NameNode和命名空间状态同步,一次只允许向NameNode注册一个备份节点。
HDFS的设计目标
Hadoop的目标是在非常大的集群中使用常用服务器,并且每个服务器都有一组廉价内部磁盘驱动器。为了获得更好的性能,MapReduce API尝试在存储要处理的数据的服务器上分配工作负载,这称为数据局部性。因此,在Hadoop环境中,建议不要使用 区域存储网络(SAN)或网络直接存储(NAS) 。对于使用SAN或NAS的Hadoop部署,额外的网络通信开销可能会导致性能瓶颈,尤其是在集群规模较大的情况下。
假设,我们目前拥有1000台机器集群,每台机器都有三个内部磁盘驱动器。因此,请考虑由3000个廉价驱动器+ 1000个廉价服务器组成的集群的故障率,这个数值会非常大!不过,好在廉价硬件相关的MTTF故障率实际上已被很好地理解和接受,这让用户对Hadoop的包容性变得很高。Hadoop具有内置的容错和故障补偿功能,HDFS也是如此,因为数据被分成块,这些块的副本存储在Hadoop集群的其他服务器上。为了使其易于理解,我们可以说单个文件实际上存储为较小的块,这些块在整个集群中的多个服务器之间进行复制,以便更快地访问文件。
我们可以考虑一个应用场景,假设我们现在需要存储某区域内所有居民的电话号码,将姓氏以A开头的存储在服务器1上,以B开头的在服务器2上,依此类推。在Hadoop环境中,此电话簿的各个部分将分布式存储在整个集群中。如果要重建整个电话簿的数据,程序需要访问集群中每个服务器的块。为了实现更高的可用性,HDFS默认将较小的数据复制到另外两台服务器上。这里会涉及到冗余的概念,但支持冗余是为了避免故障并提供容错解决方案,可以基于每个文件或针对整个环境增加或减少该冗余。这种冗余具备多种好处,最明显的一个是数据高可用。除此之外,数据冗余允许Hadoop集群将工作分解为更小的块,并在集群中的所有服务器上运行较小的作业,以实现更好的可伸缩性。最后,作为最终用户,我们获得了数据局部性的好处,这在处理大型数据集时至关重要。
管理HDFS的十大Hadoop Shell命令
以下是通过shell命令管理Hadoop HDFS的十大基本操作,这些操作对于管理HDFS集群上的文件非常有用。出于测试目的,你可以使用Cloudera或者Hortonworks等中的某些VM调用此命令,或者用于伪分布式集群设置。
1、在给定路径的HDFS中创建目录

2、列出目录内容

3、在HDFS中上传和下载文件
- Upload:
- hadoop fs -put:
将单个src文件或多个src文件从本地文件系统复制到Hadoop数据文件系统

将文件复制/下载到本地文件系统
- Download:
- hadoop fs -get:

4、查看文件的内容
与unix cat命令相同:

5、将文件从源复制到目标
此命令也允许多个源,在这种情况下,目标必须是目录。

6、将文件从(到)本地文件系统复制到HDFS

与put命令类似,但源仅限于本地文件引用。

7、将文件从源移动到目标
注意:不允许跨文件系统移动文件。

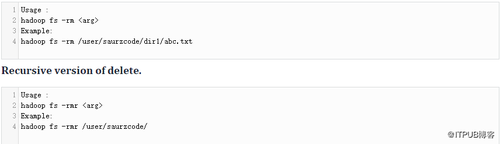
8、删除HDFS中的文件或目录
删除指定为参数的文件,仅在目录为空时删除目录:
9、显示文件的最后几行
类似于Unix中的tail命令

10、显示文件的聚合长度

结论
我们已经看到HDFS是Apache Hadoop生态系统的重要组件之一。相比于本地文件系统,HDFS确实非常强大。因此,所有大数据应用程序都使用HDFS进行数据存储,这也是作为大数据人必须了解HDFS的原因。