导读:Weld 是斯坦福大学 DAWN 实验室的一个开源项目,在 CIDR 2017 论文中描述了它的初始原型。Weld 用于对结合了数据科学库和函数的现有工作负载进行优化,而无需用户修改代码。我们在 VLDB 2018 论文中提出了 Weld 的自适应优化器,并得出了一些可喜的结果:通过在 Weld IR 上自动应用转换可以实现工作负载数量级的加速。消融研究表明,循环融合等优化具有非常大的影响。本文主要介绍如何使用 Weld 的自适应优化器进行数据分析的端到端优化。
分析应用程序通常会使用多种软件库和函数,比如使用 Pandas 操作表,使用 NumPy 处理数字,使用 TensorFlow 进行机器学习。开发人员通过使用这些库将来自各个领域的先进算法组合成强大的处理管道。
然而,即使每个库中的函数都经过精心优化,我们仍然发现它们缺少端到端的优化,在组合使用这些库时会严重影响整体性能。例如,多次调用经过优化的 BLAS 函数(使用了 NumPy)要比使用 C 语言实现单次跨函数优化(如管道化)慢 23 倍。
鉴于这种性能差距,我们最近提出了 Weld,一种用于分析工作负载的通用并行运行时。Weld 旨在实现跨多个库和函数的端到端优化,而无需改变库的 API。对于库开发人员来说,Weld 既可以实现库函数的自动并行化,也可以实现强大的跨函数优化,例如循环融合(loop fusion)。对于用户而言,Weld 可以在不修改现有管道代码的情况下带来数量级的速度提升,也就是说数据分析师可以继续使用 Pandas 和 NumPy 等流行库的 API。
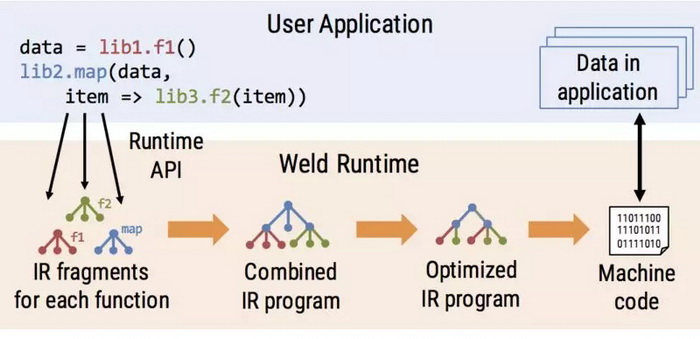
Weld 为开发人员提供了三个主要组件,用于与其他库集成:
- 库开发人员使用 Weld 的函数中间表示(Intermediate Representation,IR)来表达他们函数(例如映射操作或聚合)中的计算数据并行结构。
- 然后,使用 Weld 的库使用延迟评估运行时 API 将 Weld IR 片段提交给系统。Weld 将使用 IR 片段来自动跟踪和调度对其他函数的调用。
- 当用户想要计算结果(例如将它写入磁盘或显示它)时,Weld 将使用优化编译器对组合程序的 IR 进行优化和 JIT 编译,这样可以生成更快的并行机器代码,然后基于应用程序内存中的数据执行这些代码。
在大多数情况下,用户可以通过 import 语句切换到启用了 Weld 的库。
我们在 CIDR 2017 论文中描述了最初的 Weld 原型。通过在 IR 上应用手动优化,Weld 在合成工作负载上表现出了数量级的速度提升,这些工作负载包含了来自单个库和多个库的函数。
VLDB 2018:Weld 的自动优化
这个原型有一个很显著的限制,IR 的优化是手动进行的,需要预先知道数据的相关属性,例如聚合基数。简单地说就是系统缺少自动优化器。为此,我们在 VLDB 2018 上发表的***论文介绍了优化器的设计和实现,这个优化器可自动优化 Weld 程序。
因为 Weld 试图优化来自不同独立库的函数,所以我们发现,与实现传统的数据库优化器相比,在设计新的优化器时存在一些独特的挑战:
- 计算高度冗余。与人工编写的 SQL 查询或程序不同,Weld 程序通常由不同的库和函数生成。因此,消除由库组合产生的冗余是至关重要的。例如,可以对中间结果进行管道化或缓存昂贵的公共子表达计算结果,避免多次计算。
- Weld 在进行数据依赖决策时不能依赖预先计算的统计数据。因此,Weld 需要在不依赖目录或其他辅助信息的情况下优化 ad-hoc 分析。此外,我们发现,在没有任何统计数据的情况下进行的优化可能会导致速度减慢 3 倍,这说明做出自适应的决策是多么重要。
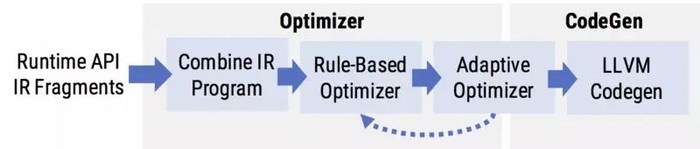
为了应对这些挑战,我们的优化器采用了双管齐下的设计,结合了静态的基于规则的优化(旨在消除冗余,以生成高效的 Weld IR)和自适应优化(在运行时确定是启用还是禁用某些优化)。
使用新优化器的评估结果是很喜人的:在 10 个真实的工作负载上使用常用库(如 NumPy 和 Pandas),Weld 可在单个线程上实现高达 20 倍的加速,并通过自动并行化实现进一步的加速。在评估 Weld 时,我们还分析了哪些优化对工作负载样本产生的影响***,我们希望这对该领域的进一步研究有所帮助。
基于规则的优化:从循环融合到向量化
Weld 的自动优化器首先会应用一组静态的基于规则的优化。基于规则的优化从 Weld IR 输入中查找特定模式,并用更有效的模式替换这些模式。Weld 基于规则的优化器在其闭合的 IR 上运行,这意味着每个优化的输入和输出都是相同的 IR。这种设计可以允许组合不同的规则并以不同的方式重新运行。
优化器包含了很多用于生成高效代码的规则,从折叠常量到合并并行循环。其他一些***影响力的基于规则的优化:
- 循环融合,通过合并两个循环来实现值的管道化,其中第二个循环直接消费***个循环的输入。管道化改进了 CPU 缓存中的数据位置,因为合并循环每次只从输入中加载一个元素。
- 向量化,它通过修改 IR 来生成显式的 SIMD 向量化代码。CPU 中的 SIMD 指令允许 CPU 在单个周期内完成更多工作,从而提高吞吐量。
- 尺寸推断,它通过分析 IR 来预先分配内存而不是动态增长缓冲区。这个优化避免了昂贵的库调用,如 malloc。
Weld 应用了其他额外的优化,在这篇论文中有描述 http://www.vldb.org/pvldb/vol11/p1002-palkar.pdf。
自适应优化:从预测到自适应哈希表
在使用基于规则的优化器转换 IR 之后,Weld 进行了一系列自适应优化。自适应优化器不是直接替换 IR 中的模式,而是将 Weld 程序变成在运行时动态选择是否应该应用优化。
其中的一个示例是决定是否要预测一个分支。预测会将分支表达式(即 if 语句)转换为无条件计算 true 和 false 表达式的代码,然后根据条件选择正确的选项。尽管预测代码会做更多的工作(因为同时计算了两个表达式),但它也可以使用 SIMD 运算符进行向量化,这与分支代码不同。请看下面的示例:

使用预测优化是否值得取决于两个因素:运行 foo 的性能成本(例如 CPU 周期)和条件 x 的选择性。如果 foo 计算很昂贵并且 x 很少是 true,那么无条件地计算 foo(即使使用了向量指令)可能导致比使用默认分支代码更差的性能。在其他情况下,使用 SIMD 并行化可以大幅提升速度。这里的数据相关因子就是 x 的选择性:这个参数在编译时是未知的。
Weld 的自适应优化器为预测生成代码,用于对 x 进行采样,以便在运行时获得选择性的近似。然后,根据获得的测量值,将在运行时使用设置了阈值的成本模型来选择是否进行预测。下面的代码展示了自适应预测转换:

Weld 的自适应优化器还提供了一些其他的转换:例如,在构建哈希表时,它可以选择是否使用线程本地或原子全局数据结构,具体取决于键的分布和预期的内存占用。在我们的论文中有更多相关内容。
Weld 在数据科学工作负载方面的表现
我们基于 10 个真实的数据科学工作负载对优化器进行评估,包括使用 NumPy 计算用于股票定价的 Black Scholes 方程、使用 Pandas 分析婴儿名称、使用 NumPy 和 TensorFlow 来增白图像并基于它们训练模型、使用 Pandas 和 NumPy 根据犯罪情况对城市进行评分,等等。结果如下:Weld 可以稳定地提升单个线程的性能,并自动并行化本机单线程库。从下图可以看出,Weld 的自动优化器可以有效地最小化因组合单个函数调用带来的效率损失和生成快速的机器代码。
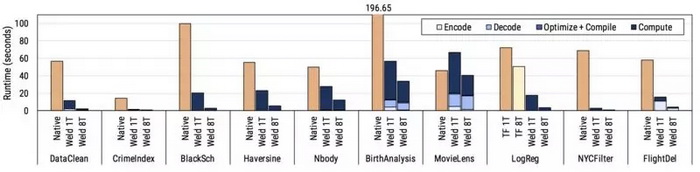
每种优化究竟有多重要?
为了研究每个优化对工作负载有多大的影响,我们还进行了一项消融研究,我们逐个关闭每种优化,并测量对性能的影响。下面的图表总结了我们分别在一个和八个线程上测试得到的结果。每个框中的数字表示禁用优化后的减速,因此数字越大意味着优化会产生更大的影响。实线下方的数字显示了带有合成参数(例如高选择性与低选择性)的工作负载,用以说明自适应优化的影响。***,“CLO”列显示了跨库优化或跨库函数优化的影响。
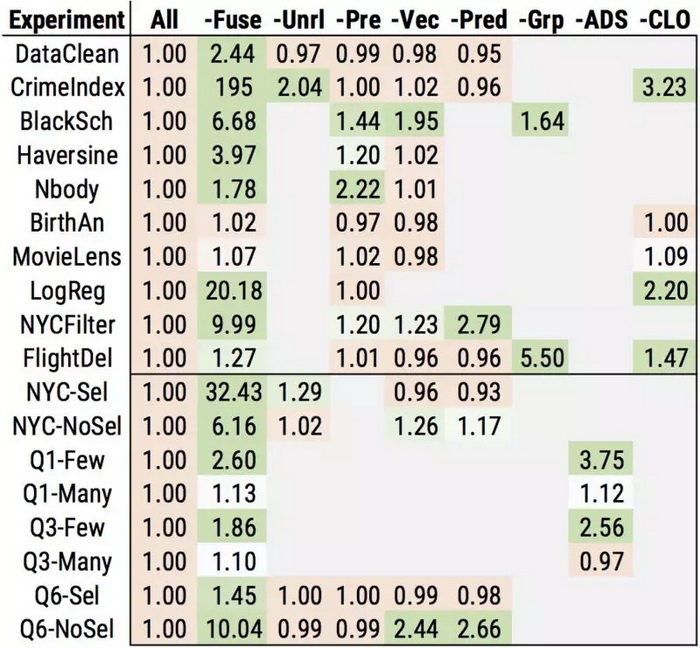
总的
来说,我们发现许多优化至少对一个工作负载具有中等以上的影响。此外,跨库优化具有相当大的影响,即使在 Weld 对库应用了优化之后,仍然可以将性能提高 3 倍之多。我们的研究还表明,一些优化非常重要:比如,循环融合和向量化对很多工作负载具有很大的影响。
总结Weld 是一种新的方法,用于对结合了数据科学库和函数的现有工作负载进行优化,而无需用户修改代码。我们的自动优化器得出了一些可喜的结果:我们可以通过在 Weld IR 上自动应用转换来实现工作负载数量级的加速。我们的消融研究表明,循环融合等优化具有非常大的影响。
Weld 是开源的,由 Stanford DAWN 负责开发,我们在评估中使用的代码(weld-numpy 和 Grizzly,是 Pandas-on-Weld 的一部分)也是开源的,可在 PyPi 上获得。这些包可以使用 pip 安装:

重要链接:
- Weld 官网:https://www.weld.rs/
- 评估代码 weld-numpy:https://www.weld.rs/weldnumpy
- 评估代码 Grizzly:https://www.weld.rs/grizzly
- CIDR 2017 论文:https://cs.stanford.edu/~matei/papers/2017/cidr_weld.pdf
- VLDB 2018 论文:http://www.vldb.org/pvldb/vol11/p1002-palkar.pdf