一、说明
近两年来直播行业越来越火,各个直播平台加一起差不多300多家。有些直播平台做秀场、综娱类的直播(来疯直播),有的做游戏直播(熊猫直播),有的做体育赛事的直播(乐视直播),分类也各种各样。下面一张图很好地反映了国内直播平台的大致分类。

本人有幸参与到了来疯Android手机直播的研发,本着技术分享的精神,现在写一系列的文章来介绍安卓手机直播,一方面希望能帮助大家了解Android手机直播相关的技术,另一方面也当作是自己工作一段时间的总结。
二、总体
如果让大家马上去开发一款Android直播应用,大家可能感觉到无从下手,因此从总体上了解整个手机直播过程是十分重要的。
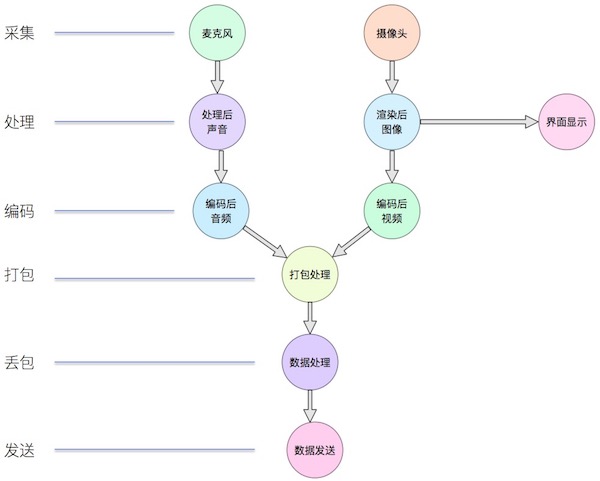
手机直播需要实现的无非是将手机采集到的视频和音频经过处理后以一定的格式发送到服务器端,整个过程如下所示:
三、采集
采集主要包括两个方面:视频采集和音频采集。视频通过摄像头进行采集,这里面涉及到摄像头的相关操作以及摄像头的参数设置,由于各个手机厂商的摄像头存在差异,因此这方面有一些坑,之后的讲摄像头的文章中会一一讲述。音频通过麦克风进行采集,不同手机的麦克风对音频采样率的支持不同,而且有时候为了支持连麦功能需要对音频进行回声消除。
视频采集技术要点:
- 检测摄像头是否可以使用;
- 摄像头采集到的图像是横向的,需要对采集到的图像进行一定的旋转后再进行显示;
- 摄像头采集时有一系列的图像大小可以选择,当采集的图像大小和手机屏幕大小比例不一致时,需要进行特殊处理;
- Android手机摄像头有一系列的状态,需要在正确的状态下才能对摄像头进行相应的操作;
- Android手机摄像头的很多参数存在兼容性问题,需要较好地处理这些兼容性的问题。
音频采集技术要点:
- 检测麦克风是否可以使用;
- 需要检测手机对某个音频采样率的支持;
- 在一些情况下需要对音频进行回声消除处理;
- 音频采集时设置正确的缓冲区大小。
四、处理
视频处理
美颜现在几乎是一个手机直播软件的标配,经过美颜后主播颜值更高,对粉丝也就更有吸引力,也有一些安卓直播应用可以对主播进行人脸识别,然后添加好玩的动画特效,有些时候我们也需要对视频添加水印。
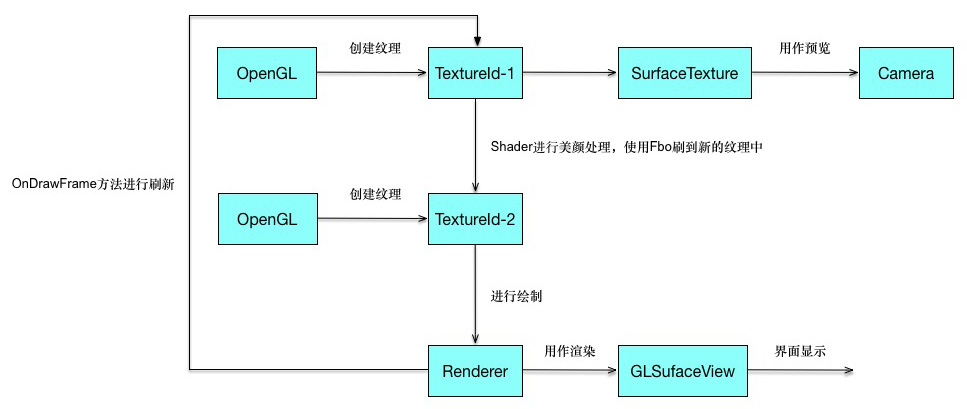
其实对视频进行美颜和添加特效都是通过OpenGL进行处理的。Android中有GLSurfaceView,这个类似于SurfaceView,不过可以利用Renderer对其进行渲染。通过OpenGL可以生成纹理,通过纹理的Id可以生成SurfaceTexture,而SurfaceTexture可以交给Camera,***通过纹理就将摄像头预览画面和OpenGL建立了联系,从而可以通过OpenGL进行一系列的操作。
美颜的整个过程无非是根据Camera预览的纹理通过OpenGL中FBO技术生成一个新的纹理,然后在Renderer中的onDrawFrame()使用新的纹理进行绘制。添加水印也就是先将一张图片转换为纹理,然后利用OpenGL进行绘制。添加动态挂件特效则比较复杂,先要根据当前的预览图片进行算法分析识别人脸部相应部位,然后在各个相应部位上绘制相应的图像,整个过程的实现有一定的难度。
下图是整个美颜过程的流程图:
下面的图片很好地展示了美颜和动画效果。


音频处理
在一些情况下,主播需要添加一些额外的声音以增加直播气氛,比如:鼓掌声等等。一种处理方式是让附加的声音直接播放出来,这样麦克风会采集到然后一起录制,但是这样的处理在主播戴上耳机或者需要对声音进行回声消除处理的情况下就不能起到作用。由于我们项目中也未加入相应功能,暂时未有相关经验进行分享,之后我们可能会加上这个功能,到时候再和大家分享。
五、编码
通过摄像头和麦克风我们可以采集到相应的视音频数据,但是这些是固定格式的原始数据,一般来说摄像头采集到的是一帧一帧画面,而麦克风采集的是PCM音频数据。如果直接将这些数据进行发送,这样往往会数据量很大,造成很大的带宽浪费,因此在发送前往往需要对视音频进行编码。
视频编码
1、预测编码
众所周知,一幅图像由许多个所谓像素的点组成,大量的统计表明,同一幅图像中像素之间具有较强的相关性,两个像素之间的距离越短,则其相关性越强,通俗地讲,即两个像素的值越接近。于是,人们可利用这种像素间的相关性进行压缩编码,这种压缩方式称为帧内预测编码。不仅如此,邻近帧之间的相关性一般比帧内像素间的相关性更强,压缩比也更大。由此可见,利用像素之间(帧内)的相关性和帧间的相关性,即找到相应的参考像素或参考帧作为预测值,可以实现视频压缩编码。
2、变换编码
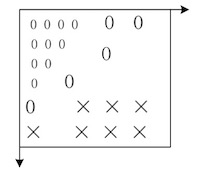
大量统计表明,视频信号中包含着能量上占大部分的直流和低频成分,即图像的平坦部分,也有少量的高频成分,即图像的细节。因此,可以用另一种方法进行视频编码,将图像经过某种数学变换后,得到变换域中的图像(如图所示),其中 u,v 分别是空间频率坐标。
3、基于波形的编码
基于波形的编码采用了把预测编码和变换编码组合起来的基于块的混合编码方法。为了减少编码的复杂性,使视频编码操作易于执行,采用混合编码方法时,首先把一幅图像分成固定大小的块,例如块 8×8(即每块 8 行,每行 8 个像素)、块 16×16(每块 16 行,每行 16 个像素)等等,然后对块进行压缩编码处理。
自 1989 年 ITU-T 发布***个数字视频编码标准——H.261 以来,已陆续发布了 H.263 等视频编码标准及 H.320、H.323 等多媒体终端标准。ISO 下属的运动图像专家组(MPEG)定义了 MPEG-1、MPEG-2、MPEG-4 等娱乐和数字电视压缩编码国际标准。
2003 年 3 月份,ITU-T 颁布了 H.264 视频编码标准。它不仅使视频压缩比较以往标准有明显提高,而且具有良好的网络亲和性,特别是对 IP 互联网、无线移动网等易误码、易阻塞、QoS 不易保证的网络视频传输性能有明显的改善。 所有这些视频编码都采用了基于块的混合编码法,都属于基于波形的编码。
4、基于内容的编码
还有一种基于内容的编码技术,这时先把视频帧分成对应于不同物体的区域,然后对其编码。具体说来,即对不同物体的形状、运动和纹理进行编码。在最简单情况下,利用二维轮廓描述物体的形状,利用运动矢量描述其运动状态,而纹理则用颜色的波形进行描述。
当视频序列中的物体种类已知时,可采用基于知识或基于模型的编码。例如,对人的脸部,已开发了一些预定义的线框对脸的特征进行编码,这时编码效率很高,只需少数比特就能描述其特征。对于人脸的表情(如生气、高兴等),可能的行为可用语义编码,由于物体可能的行为数目非常小,可获得非常高的编码效率。
MPEG-4 采用的编码方法就既基于块的混合编码,又有基于内容的编码方法。
5、软编与硬编
在Android平台上实现视频的编码有两种实现方式,一种是软编,一种是硬编。软编的话,往往是依托于cpu,利用cpu的计算能力去进行编码。比如我们可以下载x264编码库,写好相关的jni接口,然后传入相应的图像数据。经过x264库的处理以后就将原始的图像转换成为h264格式的视频。
硬编则是采用Android自身提供的MediaCodec,使用MediaCodec需要传入相应的数据,这些数据可以是yuv的图像信息,也可以是一个Surface,一般推荐使用Surface,这样的话效率更高。Surface直接使用本地视频数据缓存,而没有映射或复制它们到ByteBuffers;因此,这种方式会更加高效。在使用Surface的时候,通常不能直接访问原始视频数据,但是可以使用ImageReader类来访问不可靠的解码后(或原始)的视频帧。这可能仍然比使用ByteBuffers更加高效,因为一些本地缓存可以被映射到 direct ByteBuffers。当使用ByteBuffer模式,可以利用Image类和getInput/OutputImage(int)方法来访问到原始视频数据帧。
音频编码
Android中利用AudioRecord可以录制声音,录制出来的声音是PCM声音。想要将声音用计算机语言表述,则必须将声音进行数字化。将声音数字化,最常见的方式是透过脉冲编码调制PCM(Pulse Code Modulation) 。声音经过麦克风,转换成一连串电压变化的信号。要将这样的信号转为 PCM 格式的方法,是使用三个参数来表示声音,它们是:声道数、采样位数和采样频率。
1、采样频率
即取样频率,指每秒钟取得声音样本的次数。采样频率越高,声音的质量也就越好,声音的还原也就越真实,但同时它占的资源比较多。由于人耳的分辨率很有限,太高的频率并不能分辨出来。在16位声卡中有22KHz、44KHz等几级,其中,22KHz相当于普通FM广播的音质,44KHz已相当于CD音质了,目前的常用采样频率都不超过48KHz。
2、采样位数
即采样值或取样值(就是将采样样本幅度量化)。它是用来衡量声音波动变化的一个参数,也可以说是声卡的分辨率。它的数值越大,分辨率也就越高,所发出声音的能力越强。
在计算机中采样位数一般有8位和16位之分,但有一点请大家注意,8位不是说把纵坐标分成8份,而是分成2的8次方即256份; 同理16位是把纵坐标分成2的16次方65536份。
3、声道数
很好理解,有单声道和立体声之分,单声道的声音只能使用一个喇叭发声(有的也处理成两个喇叭输出同一个声道的声音),立体声的pcm可以使两个喇叭都发声(一般左右声道有分工) ,更能感受到空间效果。
那么,现在我们就可以得到pcm文件所占容量的公式:
- 存储量=(采样频率 采样位数 声道 时间)? 8 (单位:字节数)
如果音频全部用PCM的格式进行传输,则占用带宽比较大,因此在传输之前需要对音频进行编码。
现在已经有一些广泛使用的声音格式,如:wav、MIDI、MP3、WMA、AAC、Ogg等等。相比于pcm格式而言,这些格式对声音数据进行了压缩处理,可以降低传输带宽。
对音频进行编码也可以分为软编和硬编两种。软编则下载相应的编码库,写好相应的jni,然后传入数据进行编码。硬编则是使用Android自身提供的MediaCodec。
六、打包
视音频在传输过程中需要定义相应的格式,这样传输到对端的时候才能正确地被解析出来。
1、HTTP-FLV
Web 2.0时代,要说什么类型网站最火,自然是以国外的Youtube,国内的优酷、土豆网站了。这类网站提供的视频内容可谓各有千秋,但它们无一例外的都使用了Flash作为视频播放载体,支撑这些视频网站的技术基础就是——Flash 视频(FLV) 。FLV 是一种全新的流媒体视频格式,它利用了网页上广泛使用的Flash Player 平台,将视频整合到Flash动画中。也就是说,网站的访问者只要能看Flash动画,自然也能看FLV格式视频,而无需再额外安装其它视频插件,FLV视频的使用给视频传播带来了极大便利。
HTTP-FLV即将音视频数据封装成FLV,然后通过HTTP协议传输给客户端。而作为上传端只需要将FLV格式的视音频传输到服务器端即可。
一般来说FLV格式的视音频,里面视频一般使用h264格式,而音频一般使用AAC-LC格式。
FLV格式是先传输FLV头信息,然后传输带有视音频参数的元数据(Metadata),然后传输视音频的参数信息,然后传输视音频数据。
2、RTMP
RTMP是Real Time Messaging Protocol(实时消息传输协议)的首字母缩写。该协议基于TCP,是一个协议簇,包括RTMP基本协议及RTMPT/RTMPS/RTMPE等多种变种。RTMP是一种设计用来进行实时数据通信的网络协议,主要用来在Flash/AIR平台和支持RTMP协议的流媒体/交互服务器之间进行音视频和数据通信。
RTMP协议是Adobe公司推出的实时传输协议,主要用于基于flv格式的音视频流的实时传输。得到编码后的视音频数据后,先要进行FLV包装,然后封包成rtmp格式,然后进行传输。
使用RTMP格式进行传输,需要先连接服务器,然后创建流,然后发布流,然后传输相应的视音频数据。整个发送是用消息来定义的,rtmp定义了各种形式的消息,而为了消息能够很好地发送,又对消息进行了分块处理,整个协议较为复杂。
还有其他几种形式的协议,比如RTP等等,大致原理差不多,也就不一一进行说明讲述了。
七、差网络处理
好的网络下视音频能够得到及时的发送,不会造成视音频数据在本地的堆积,直播效果流畅,延时较小。而在坏的网络环境下,视音频数据发送不出去,则需要我们对视音频数据进行处理。差网络环境下对视音频数据一般有四种处理方式:缓存区设计、网络检测、丢帧处理、降码率处理。
1、缓冲区设计
视音频数据传入缓冲区,发送者从缓冲区获取数据进行发送,这样就形成了一个异步的生产者消费者模式。生产者只需要将采集、编码后的视音频数据推送到缓冲区,而消费者则负责从这个缓冲区里面取出数据发送。
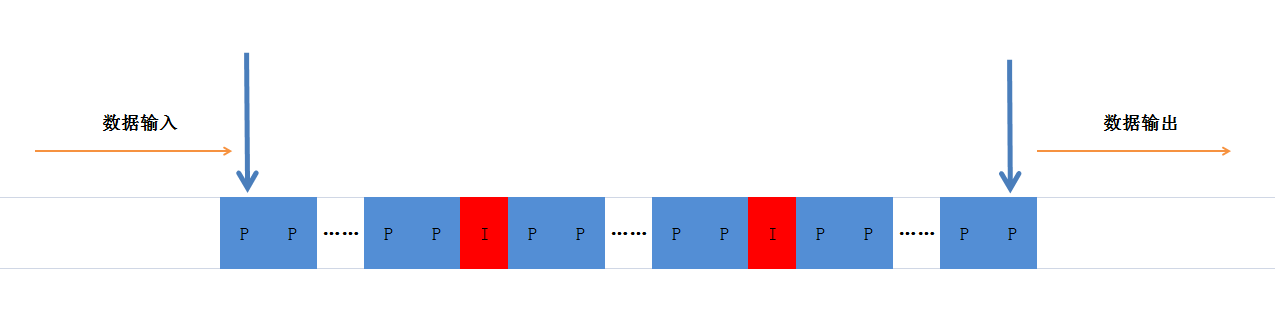
上图中只显示了视频帧,显然里面也有相应的音频帧。要构建异步的生产者消费者模式,java已经提供了很好的类,由于之后还需要进行丢帧、插入、取出等处理,显然LinkedBlockingQueue是个很不错的选择。
2、网络检测
差网络处理过程中一个重要的过程是网络检测,当网络变差的时候能够快速地检测出来,然后进行相应的处理,这样对网络反应就比较灵敏,效果就会好很多。
我们这边通过实时计算每秒输入缓冲区的数据和发送出去数据,如果发送出去的数据小于输入缓冲区的数据,那么说明网络带宽不行,这时候缓冲区的数据会持续增多,这时候就要启动相应的机制。
3、丢帧处理
当检测到网络变差的时候,丢帧是一个很好的应对机制。视频经过编码后有关键帧和非关键帧,关键帧也就是一副完整的图片,而非关键帧描述图像的相对变化。
丢帧策略多钟多样,可以自行定义,一个需要注意的地方是:如果要丢弃P帧(非关键帧),那么需要丢弃两个关键帧之间的所有非关键帧,不然的话会出现马赛克。对于丢帧策略的设计因需求而异,可以自行进行设计。
4、降码率
在Android中,如果使用了硬编进行编码,在差网络环境下,我们可以实时改变硬编的码率,从而使直播更为流畅。当检测到网络环境较差的时候,在丢帧的同时,我们也可以降低视音频的码率。在Android sdk版本大于等于19的时候,可以通过传递参数给MediaCodec,从而改变硬编编码器出来数据的码率。
Bundle bitrate = new Bundle();bitrate.putInt(MediaCodec.PARAMETER_KEY_VIDEO_BITRATE, bps * 1024);
mMediaCodec.setParameters(bitrate);
- 1.
- 2.
八、发送
经过各种处理,***需要将数据发送出去,这一步较为简单。无论是HTTP-FLV,还是RTMP,我们这边都是使用TCP建立连接的。直播开始之前需要通过Socket连接服务器,验证是否能连接服务器,连接之后便使用这个Socket向服务器发送数据,数据发送完毕后关闭Socket。