为什么要使用分布式缓存
高并发环境下,例如典型的淘宝双11秒杀,几分钟内上亿的用户涌入淘宝,这个时候如果访问不加拦截,让大量的读写请求涌向数据库,由于磁盘的处理速度与内存显然不在一个量级,服务器马上就要宕机。从减轻数据库的压力和提高系统响应速度两个角度来考虑,都会在数据库之前加一层缓存,访问压力越大的,在缓存之前就开始CDN拦截图片等访问请求。
并且由于最早的单台机器的内存资源以及承载能力有限,如果大量使用本地缓存,也会使相同的数据被不同的节点存储多份,对内存资源造成较大的浪费,因此,才催生出了分布式缓存。
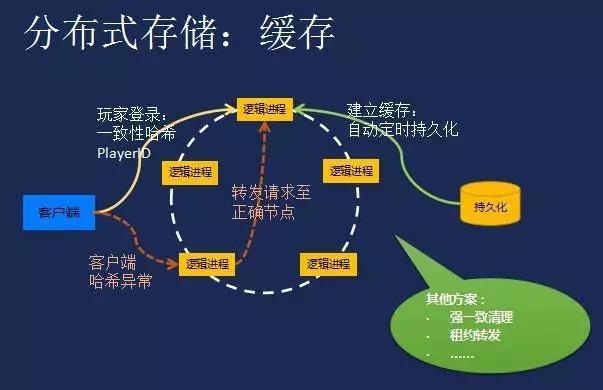
分布式缓存应用场景
- 页面缓存.用来缓存Web 页面的内容片段,包括HTML、CSS 和图片等;
- 应用对象缓存.缓存系统作为ORM 框架的二级缓存对外提供服务,目的是减轻数据库的负载压力,加速应用访问;
- 解决分布式Web部署的session同步问题,状态缓存.缓存包括Session 会话状态及应用横向扩展时的状态数据等,这类数据一般是难以恢复的,对可用性要求较高,多应用于高可用集群。
- 并行处理.通常涉及大量中间计算结果需要共享;
- 云计算领域提供分布式缓存服务。
分布式缓存比较:Memcache VS Redis
1、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。而memcache只支持简单数据类型,需要客户端自己处理复杂对象
2、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用(PS:持久化在rdb、aof)。
3、由于Memcache没有持久化机制,因此宕机所有缓存数据失效。Redis配置为持久化,宕机重启后,将自动加载宕机时刻的数据到缓存系统中。具有更好的灾备机制。
4、Memcache可以使用Magent在客户端进行一致性hash做分布式。Redis支持在服务器端做分布式(PS:Twemproxy/Codis/Redis-cluster多种分布式实现方式)
5、Memcached的简单限制就是键(key)和Value的限制。***键长为250个字符。可以接受的储存数据不能超过1MB(可修改配置文件变大),因为这是典型slab 的***值,不适合虚拟机使用。而Redis的Key长度支持到512k。
6、Redis使用的是单线程模型,保证了数据按顺序提交。Memcache需要使用cas保证数据一致性。CAS(Check and Set)是一个确保并发一致性的机制,属于“乐观锁”范畴;原理很简单:拿版本号,操作,对比版本号,如果一致就操作,不一致就放弃任何操作
cpu利用。由于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更 高。而在100k以上的数据中,Memcached性能要高于Redis 。
7、memcache内存管理:使用Slab Allocation。原理相当简单,预先分配一系列大小固定的组,然后根据数据大小选择最合适的块存储。避免了内存碎片。(缺点:不能变长,浪费了一定空间)memcached默认情况下下一个slab的***值为前一个的1.25倍。
8、redis内存管理: Redis通过定义一个数组来记录所有的内存分配情况, Redis采用的是包装的malloc/free,相较于Memcached的内存 管理方法来说,要简单很多。由于malloc 首先以链表的方式搜索已管理的内存中可用的空间分配,导致内存碎片比较多。
分布式缓存选型总结
其实对于企业选型Memcache、Redis而言,更多还是应该看业务使用场景(因为Memcache、Redis两者都具有足够高的性能和稳定性)。假若业务场景需要用到持久化缓存功能、或者支持多种数据结构的缓存功能,那么Redis则是***选择。
(PS:Redis集群解决方式也优于Memcache,Memcache在客户端一致性hash的集群解决方案,Redis采用无中心的服务器端集群解决方案)
综上所述:为了让缓存系统能够支持更多的业务场景,选择Redis会更优。
分布式缓存的常见问题和挑战
1.缓存雪崩
缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
2.缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存***率问题。
3.缓存预热
缓存预热这个应该是一个比较常见的概念,相信很多小伙伴都应该可以很容易的理解,缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
4.缓存更新
除了缓存服务器自带的缓存失效策略之外,我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定时去清理过期的缓存;
(2)当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,***种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
5.缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的***阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。