在处理任何类型的机器学习(ML)问题时,我们有许多不同的算法可供选择。而机器学习领域有一个得到大家共识的观点,大概就是:没有一个ML算法能够***地适用于解决所有问题。不同ML算法的性能在很大程度上取决于数据的大小和结构。因此,如何选择正确的算法往往是一个大难题,除非我们直接通过大量的试验和错误来测试我们的算法。
但是,每个ML算法都有一些优点和缺点,我们可以将它们用作指导。虽然一种算法并不总是比另一种更好,但是我们可以使用每种算法的一些属性作为快速选择正确算法和调优超参数的指南。我们将介绍一些用于回归问题的著名ML算法,并根据它们的优缺点设置使用它们的指导方针。这篇文章将帮助您为回归问题选择***的ML算法!
线性和多项式回归
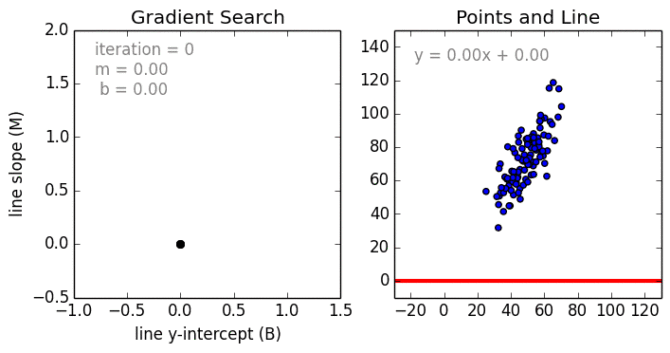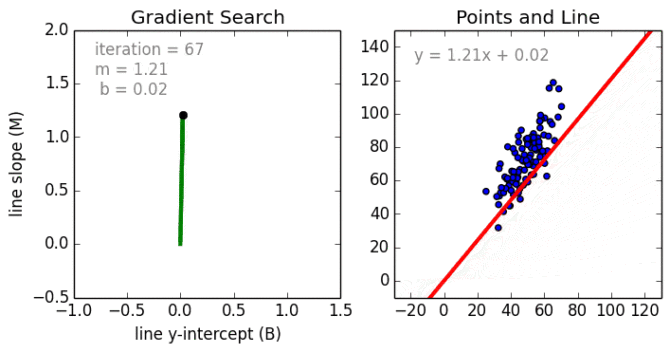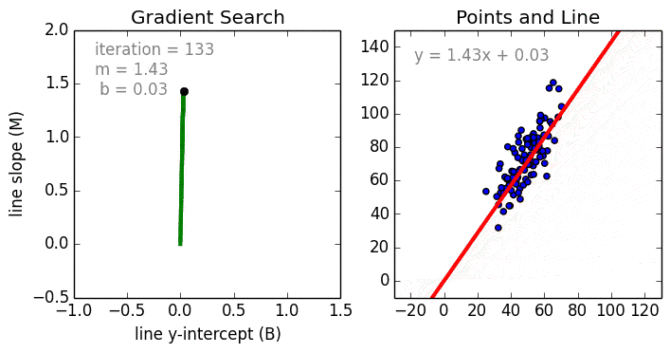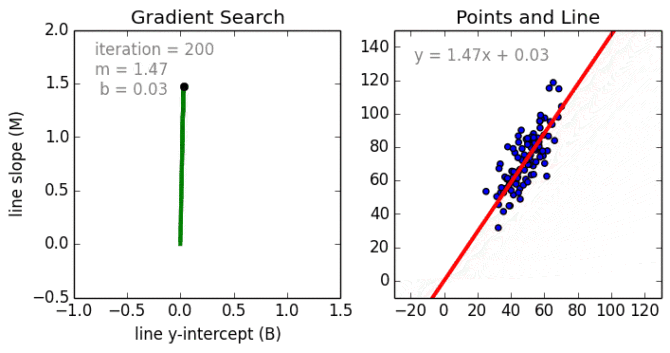
线性回归
从简单的情况开始。单变量线性回归是一种用于使用线性模型例如一条线对单个输入自变量(特征变量)和输出因变量之间的关系进行建模的技术。更普遍的情况是多变量线性累加,其中为多个独立输入变量(特征变量)和输出因变量之间的关系创建了一个模型。模型保持线性,因为输出是输入变量的线性组合。
第三种最普遍的情况叫做多项式回归模型现在变成了特征变量的非线性组合,例如可以是指数变量,和余弦等,但这需要知道数据与输出的关系。回归模型可以使用随机梯度下降(SGD)进行训练。
优点:
- 快速建模,当要建模的关系不是非常复杂,而且你没有很多数据时,这是非常有用的。
- 线性回归很容易理解哪些对业务决策非常有用。
缺点:
- 对于非线性数据,多项式回归的设计是非常具有挑战性的,因为必须有一些关于数据结构和特征变量之间关系的信息。
- 因此,当涉及到高度复杂的数据时,这些模型并不像其他模型那样好。
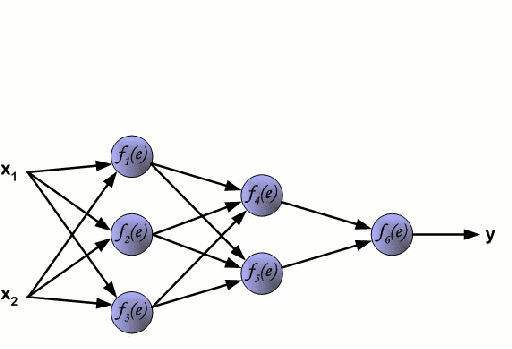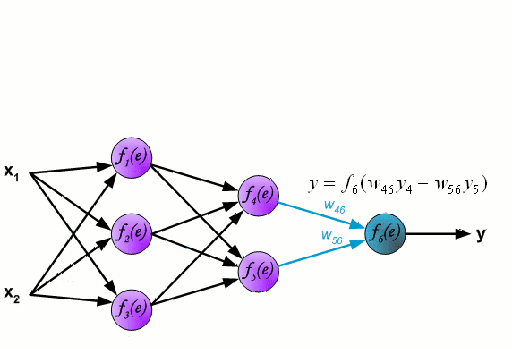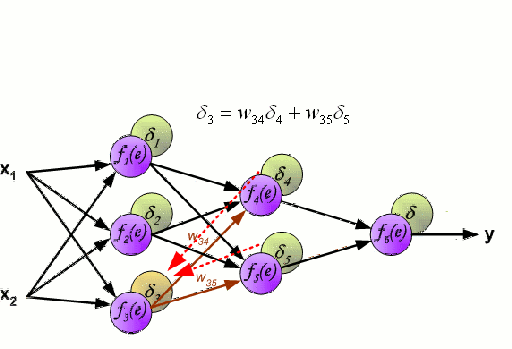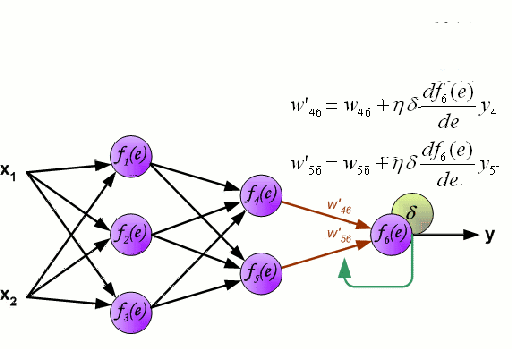
神经网络
神经网络由一组相互连接的被称作神经元的节点组成。数据中的输入特征变量作为多变量线性组合传递给这些神经元,其中每个特征变量乘以的值称为权重。然后将非线性应用于这种线性组合,使神经网络能够建立复杂的非线性关系。神经网络可以有多个层,其中一层的输出以同样的方式传递给下一层。在输出端,通常不应用非线性。神经网络的训练使用随机梯度下降(SGD)和反向传播算法(两者都显示在上面的GIF中)。
优点:
- 由于神经网络可以有许多具有非线性的层(和参数),因此它们在建模高度复杂的非线性关系时非常有效。
- 我们通常不需要担心,神经网络的数据结构在学习任何类型的特征变量关系时都很灵活。
- 研究表明,简单地向网络提供更多的训练数据,无论是全新的,还是增加原始数据集,都有利于网络性能。
缺点:
- 由于这些模型的复杂性,它们并不容易解释和理解。
- 对于训练而言,它们可能具有相当的挑战性和计算密集性,需要仔细进行超参数调整,设定学习进度计划。
- 它们需要大量的数据才能获得高性能,在“小数据”情况下,它们往往会被其他ML算法超越。
回归树和随机森林
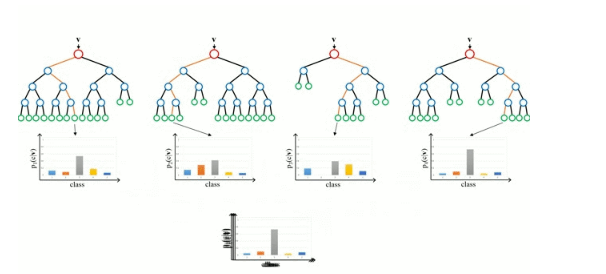
随机森林
从基本情况开始。决策树是一种直观的模型,通过一个遍历树的分支,并根据节点上的决策选择下一个分支。树诱导是将一组训练实例作为输入的任务,决定哪些属性最适合拆分,分割数据集,并在产生的拆分数据集上重复出现,直到所有的训练实例都被分类为止。构建树时,目标是对创建可能的***纯度子节点的属性进行分割,这将使对数据集中的所有实例进行分类时,需要进行的分割数量保持***。纯度是由信息增益的概念来衡量的,这一概念涉及为了对其进行适当的分类,需要对一个以前不可见的实例了解多少。在实践中,通过比较熵,或对当前数据集分区的单个实例进行分类所需的信息量,对单个实例进行分类,如果当前的数据集分区要在给定的属性上进一步分区的话。
随机森林只是一组决策树。输入向量在多个决策树中运行。对于回归,取所有树的输出值的平均值;对于分类,使用投票方案来决定最终的类。
优点:
- 擅长学习复杂的、高度非线性的关系。它们通常可以达到相当高的性能,比多项式回归更好,而且通常与神经网络相当。
- 很容易解释和理解。虽然最终的训练模型可以学习复杂的关系,但是在训练过程中建立的决策边界是很容易理解和实用的。
缺点:
- 由于训练决策树的性质,它们可能倾向于主要的过度拟合。一个完整的决策树模型可能过于复杂,包含不必要的结构。虽然这有时可以通过适当的树木修剪和更大的随机森林组合来缓解。
- 使用更大的随机森林组合来实现更高的性能带来了速度慢和需要更多内存的缺点。
***
希望你喜欢这篇文章,并学到一些新的和有用的东西。