导读: AI(人工智能)技术已经广泛应用于美团的众多业务,从美团App到大众点评App,从外卖到打车出行,从旅游到婚庆亲子,美团数百名最优秀的算法工程师正致力于将AI技术应用于搜索、推荐、广告、风控、智能调度、语音识别、机器人、无人配送等多个领域,帮助美团数亿消费者和数百万商户改善服务和体验,帮大家吃得更好,生活更好。
基于AI技术,美团搭建了世界上规模最大,复杂度最高的多人、多点实时智能配送调度系统;基于AI技术,美团推出了业内第一款大规模落地的企业应用级语音交互产品,为50万骑手配备了智能语音系统;基于AI技术,美团构建了世界上最大的菜品知识库,为200多万商家、3亿多件商品绘制了知识图谱,为数亿用户提供了精准的用户画像,并构建了世界上用户规模最大、复杂度最高的O2O智能推荐平台。
美团这个全球最大生活服务互联网平台的“大脑”是怎么构建的?业界第一部全面讲述互联网机器学习实践的图书《美团机器学习实践》也即将上市,敬请期待,本文选自书中第十五章。
背景
美团每天有百万级的图片产生量,运营人员负责相关图片的内容审核,对涉及法律风险及不符合平台规定的图片进行删除操作。由于图片数量巨大,人工审核耗时耗力且审核能力有限。另外对于不同审核人员来讲,审核标准难以统一且实时变化。所以有必要借助机器实现智能审核。
图像智能审核一般是指利用图像处理与机器学习相关技术识别图像内容,进而甄别图像是否违规。图像智能审核旨在建立图片自动审核服务,由机器自动禁止不符合规定(负例)的图片类型,自动通过符合规定(正例)的图片类型,机器不确定的图片交由人工审核。因此,衡量智能审核系统性能的指标主要是准确率和自动化率。
通常的自动审核思路是穷举不符合规定的图片(例如水印图、涉黄图、暴恐图、明星脸、广告图等)类型,剩下的图片作为正例自动通过。这样带来的问题是对新增的违规内容扩展性不足,另外必须等待所有模型构建完毕才能起到自动化过滤的作用。如果我们能主动挖掘符合规定的图片(例如正常人物图、场景一致图)进行自动通过,将正例过滤和负例过滤相结合,这样才能更快起到节省人工审核的作用。因此,我们的图像智能审核系统分为图片负例过滤模块和图片正例过滤模块,待审图片先进入负例过滤模块判断是否违禁,再进入正例过滤模块进行自动通过,剩余机器不确定的图片交由人工审核。整个技术方案如图1所示。
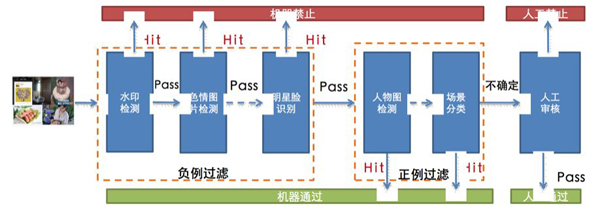
图1 图像智能审核技术方案
负例过滤和正例过滤模块中都会涉及检测、分类和识别等技术,而深度学习则是该领域的首选技术。下面将分别以水印过滤、明星脸识别、色情图片检测和场景分类来介绍深度学习在图像智能审核中的应用。
基于深度学习的水印检测
为了保护版权和支持原创内容,需要自动检测商家或用户上传的图片中是否包括违禁水印(竞对水印、其他产品的Logo)。与其他类刚体目标不同,水印具有以下特点:
- 样式多。线下收集所涉及的主流违禁水印有20多类,每一类水印又存在多种样式。除此之外,线上存在大量未知类型的水印。
- 主体多变。水印在图片中位置不固定且较小,主体存在裁切变形,并且会存在多个主体交叠(多重水印),如图2所示。

图2 主体多变
- 背景复杂。由于主流水印大多采用透明或半透明方式,这使得水印中的文字标识极易受到复杂背景的干扰,如图3所示。

图3 背景复杂
传统的水印检测采用滑动窗口的方法,提取一个固定大小的图像块输入到提前训练好的鉴别模型中,得到该块的一个类别。这样遍历图片中的所有候选位置,可得到一个图片密集的类别得分图。得分高于一定阈值的块被认为是水印候选区域,通过非极大化抑制可以得到最终的结果。
鉴别模型的特征可以采用文字识别领域常用的边缘方向统计特征,也可以通过CNN进行特征学习来提升对裁切、形变、复杂背景的健壮性。为了进一步改善得分的置信度,可以加入类型原型的信息,把输入图像块特征与聚类中心特征的相似度(夹角余弦)作为识别置信度。但上述方法检测效率极低,由于水印位置和大小不固定,需要在所有位置对多个尺度的图像进行判别,由此产生大量的冗余窗口。
一种思路是旨在减少滑动窗口数目的子窗口的方法。首先通过无监督/有监督学习生成一系列的候选区域,再通过一个CNN分类器来判断区域中是否包含目标以及是哪一类目标。这类方法比较有代表的是R-CNN系列。由于该类方法得到的候选框可以映射到原图分辨率,因此定位框精度足够高。
另一种解决思路时采用直接在特征图上回归的方法。我们知道,对于CNN网络的卷积层而言,输入图片大小可以不固定,但从全连接层之后就要求输入大小保持一致。因此当把任意大小的图片输入CNN直到第一个全连接层,只需要一次前向运算就可以得到所有层的特征图。然后回归的对象是待检测目标的位置信息和类别信息,它们可根据目标大小的需要在不同层次的特征图上进行回归,这类方法以Yolo、SSD为代表。该类方法的特点是在保证高检测精度的前提下实时性较好。
图4给出了上述两类框架与DPM(可变形部件模型)最佳传统方法的性能比较:
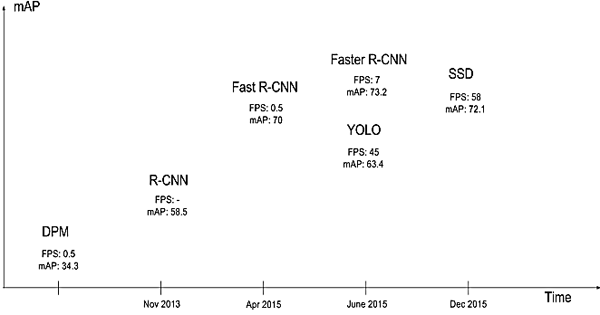
图4 基于深度学习的主流目标检测方法的性能评测
考虑到水印检测任务对定位框的精度要求不高,且需要满足每天百万量级图片的吞吐量,我们借鉴了SSD框架和Resnet网络结构。在训练数据方面,我们通过人工收集了25类共计1.5万张水印图片,并通过主体随机裁切、前背景合成等方式进行了数据增广。
基于训练得到的模型对线上数据进行了相关测试。随机选取3197张线上图片作为测试集,其中2795张图片不包含水印,包含水印的402张图片里有302张包含训练集中出现过的水印,另外的100张包含未出现在训练集中的小众水印。基于该测试集,我们评测了传统方法(人工设计特征+滑窗识别)和基于SSD框架的方法。
从图5可以看到,相比于传统方法,SSD框架无论在召回和精度上都有明显优势。进一步分析发现,深度学习方法召回了38张小众水印图片,可见CNN学习到的特征泛化能力更强。
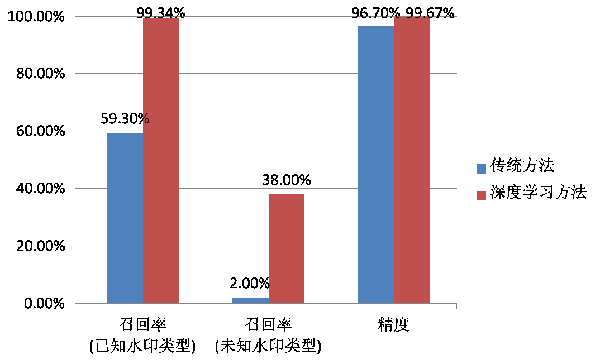
图5 水印检测性能评测
明星脸识别
为了避免侵权明星肖像权,审核场景需要鉴别用户/商家上传的图像中是否包含明星的头像。这是一类典型的人脸识别应用,具体来说是一种1∶(N+1)的人脸比对。整个人脸识别流程包含人脸检测、人脸关键点检测、人脸矫正及归一化、人脸特征提取和特征比对,如图6所示。其中深度卷积模型是待训练的识别模型,用于特征提取。下面我们将分别介绍人脸检测和人脸识别技术方案。
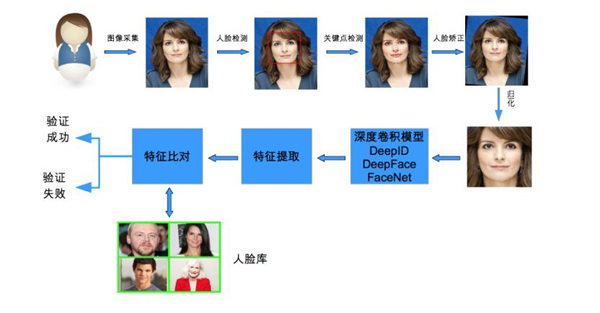
图6 明星脸识别流程
人脸检测
人脸检测方法可分为传统检测器和基于深度学习的检测器两类。
传统检测器主要基于V-J框架,通过设计Boosted的级连结构和人工特征实现检测。特征包括Harr特征、HOG特征和基于像素点比较的特征(Pico、NPD)等。
这类检测器在约束环境下有着不错的检测效果和运行速度,但对于复杂场景(光照、表情、遮挡),人工设计的特征使检测能力会大大下降。为了提升性能,相关研究联合人脸检测和人脸关键点定位这两个任务进行联合优化(JDA),将关键点检测作为人脸检测的一个重要评价标准,但其准确率有待进一步提升。
深度学习的检测器有三种思路。
- 第一类是沿用V-J框架,但以级联CNN网络(Cascaded CNN)替代传统特征。
- 第二类是基于候选区域和边框回归的框架(如Faster R-CNN)。
- 第三类是基于全卷积网络直接回归的框架(如DenseBox)。
我们采用了Faster R-CNN框架并从以下方面进行了改进: 难分负例挖掘(抑制人物雕像、画像和动物头像等负例)、多层特征融合、 多尺度训练和测试、上下文信息融合,从而更好地抵抗复杂背景、类人脸、遮挡等干扰,并有效提升了对小脸、侧脸的检出率。
人脸识别
人脸识别主要有两种思路。一种是直接转换为图像分类任务,每一类对应一个人的多张照片,比较有代表性的方法有DeepFace、DeepID等。另一种则将识别转换为度量学习问题,通过特征学习使得来自同一个人的不同照片距离比较近、不同的人的照片距离比较远,比较有代表性的方法有DeepID2、FaceNet等。
由于任务中待识别ID是半封闭集合,我们可以融合图像分类和度量学习的思路进行模型训练。考虑到三元组损失(Triplet Loss)对负例挖掘算法的要求很高,在实际训练中收敛很慢,因此我们采用了Center Loss来最小化类内方差,同时联合Softmax Loss来最大化类间方差。为了平衡这两个损失函数,需要通过试验来选择超参数。我们采用的网络结构是Inception-v3,在实际训练中分为两个阶段:
- 第一阶段采用Softmax Loss+C×CenterLoss,并利用公开数据集CASIA-WebFace(共包含10 575个ID和49万人脸图片)来进行网络参数的初始化和超参数C的优选,根据试验得到的C=0.01;
- 第二阶段采用Softmax Loss+0.01×Center Loss,并在业务数据(5200个明星脸ID和100万人脸图片)上进行网络参数的微调。
为了进一步提升性能,借鉴了百度采用的多模型集成策略,如图7所示。具体来说,根据人脸关键点的位置把人脸区域分割为多个区域,针对每一个区域分别训练特征模型。目前把人脸区域分割为9个区域,加上人脸整体区域,共需训练10个模型。
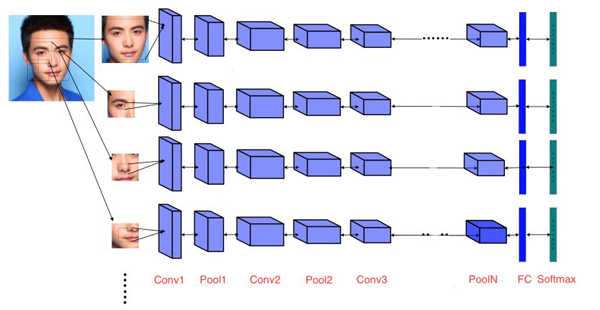
图7 基于集成学习的人脸识别
在测试阶段,对于待验证的人脸区域和候选人脸区域,分别基于图7所示的10个区域提取特征。然后对于每个区域,计算两个特征向量间的相似度(余弦距离)。最终通过相似度加权的方法判断两张人脸是否属于同一个人。表1给出了主流方法在LFW数据集上的评测结果。可以看出,美团模型在相对有限数据下获得了较高的准确率。

表1 公开数据集评测结果
色情图片检测
色情图片检测是图像智能审核中重要环节。传统检测方法通过肤色、姿态等维度对图片的合规性进行鉴别。随着深度学习的进展,现有技术雅虎NSFW(Not Suitable for Work)模型直接把色情图片检测定义二分类(色情、正常)问题,通过卷积神经网络在海量数据上进行端到端训练。
对于已训练模型,不同层次学习到的特征不同,有些层次学到了肤色特征,另外一些层次学习到了部位轮廓特征,还有的层次学到了姿态特征。但由于人类对色情的定义非常广泛,露点、性暗示、艺术等都可能被归为色情类,而且在不同的场景下或者面对不同的人群,色情定义标准无法统一。因此,初始学习到的模型泛化能力有限。为了提升机器的预测准确率,需要不断加入错分样本,让机器通过增量学习到更多特征以纠正错误。除此之外,我们在以下方面进行了优化。
- 模型细化。我们的分类模型精细化了图片的色情程度:色情、性感、正常人物图、其他类。其中色情、性感、正常人物图互为难分类别,其他类为非人物的正常图片。将性感类别和正常人物图类别从色情类别中分离出来有助于增强模型对色情的判别能力。从表2中可见,相对于雅虎的NSFW模型,我们的模型在召回率方面具有明显优势。

表2 色情图片检测准确率
- 机器审核结合人工复审。在实际业务中由于涉黄检测采用预警机制,机器审核环节需要尽可能召回所有疑似图片,再结合适量的人工审核来提升准确率。因此,上层业务逻辑会根据模型预测类别和置信度将图片划分为“确定黄图”“确定非黄图”和“疑似”三部分。“疑似”部分,根据置信度由高到底进行排序,并转交人工复审。在线上业务中,“确定黄图”和“确定非黄图”部分的精度可达到99%以上,而“疑似”部分只占总图片量的3%左右,这样在保证高精度过滤的条件下可大幅节省人力。
- 支持视频内容审核。对于短视频内容的审核,我们通过提取关键帧的方式转化为对单张图片的审核,然后融合多帧的识别结果给出结论。
场景分类
作为一个贯穿吃喝玩乐各环节的互联网平台,美团的业务涉及多种垂直领域,如表3所示。有必要对运营或用户上传图片的品类进行识别,以保持与该商家的经营范围一致。此外,为了进一步改善展示效果,需要对商家相册内的图片进行归类整理,如图8所示。
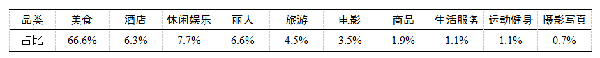
表3 美团一级品类及图片占比
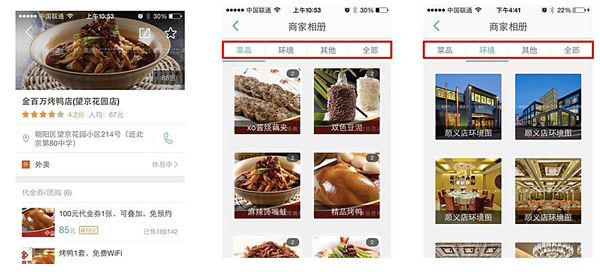
图8 商家相册图片分类
深度卷积神经网络在图像分类的相关任务上(比如ILSVRC)上已经超越人眼的识别率,但作为一种典型的监督学习方法,它对特定领域的标记样本的数量和质量的需求是突出的。我们的场景分类任务,如果完全依靠审核人员进行图片的筛选和清洗,代价较大。因此需要基于迁移学习来对模型进行微调。
迁移学习致力于通过保持和利用从一个或多个相似的任务、领域或概率分布中学习到的知识,来快速并有效地为提升目标任务的性能。模型迁移是迁移学习领域中一类常用的迁移方式,它通过学习原始域(Source Domain)模型和目标域(Target Domain)模型的共享参数来实现迁移。由于深度神经网络具有层次结构,且其隐藏层能表示抽象和不变性的特征,因此它非常适合模型迁移。
至于原始域训练的深度卷积神经网络,需要关注哪些层次的参数可以迁移以及如何迁移。不同层次的可迁移度不同,目标域与原始域中相似度较高的层次被迁移的可能性更大。具体而言,较浅的卷积层学习到的特征更通用(比如图像的色彩、边缘、基本纹理),因而也更适合迁移,较深的卷积层学习的特征更具有任务依赖性(比如图像细节),因而不适合迁移,如图9所示。
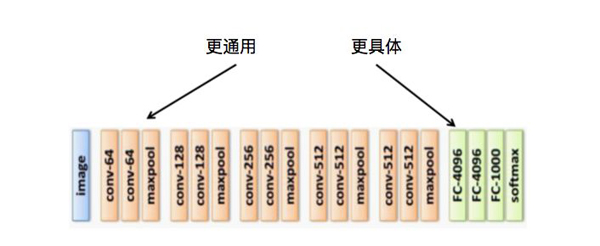
图9 深度卷积神经网络的层次结构与特征描述
模型迁移通过固定网络特定层次的参数,用目标域的数据来训练其他层次。对于我们的场景分类任务而言,首先根据分类的类别数修改网络输出层,接着固定较浅的卷积层而基于业务标注数据训练网络倒数若干层参数。如有更多的训练数据可用,还可以进一步微调整个网络的参数以获得额外的性能提升,如图10所示。
相比于直接提取图像的高层语义特征来进行监督学习,采用分阶段的参数迁移对原始域与目标域间的差异性更健壮。
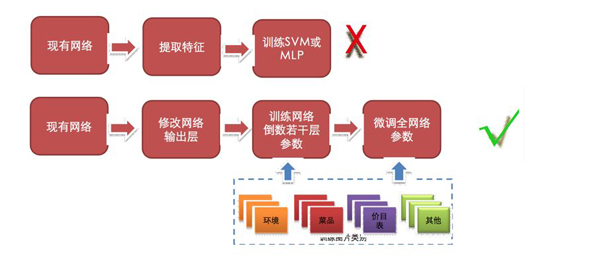
图10 基于深度卷积神经网络的模型迁移
基于上述迁移学习策略,我们在美食场景图和酒店房型图分类中进行了相关实验,基于有限(万级别图片)的标注样本实现了较高的识别准确率,测试集上的性能如表4所示。

表4 美食场景分类
如前所述,基于深度学习的图像分类与检测方法在图片智能审核中替代了传统机器学习方法,在公开模型与迁移学习的基础上,通过从海量数据中的持续学习,实现了业务场景落地。
参考文献
[1]H. Chen, S. S. Tsai, G. Schroth, D. M. Chen, R. Grzeszczuk, and B. Girod. “Robust text detection in natural images with edge-enhanced maximally stable extremal regions.” ICIP 2011.
[2]Z Zhong,LJin,SZhang,ZFeng.“DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images”. Architecture Science 2015.
[3]Minghui Liao, Baoguang Shi, Xiang Bai, Xinggang Wang, Wenyu Liu. “TextBoxes: A Fast Text Detector with a Single Deep Neural Network”. AAAI 2017.
[4]S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn.“Towards real-time object detection with region proposal networks.” NIPS 2015.
[5]Graves, A.; Fernandez, S.; Gomez, F.; and Schmidhuber, J. “Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks.” ICML 2006.
[6]R Girshick,JDonahue,TDarrell,JMalik. “Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation.” CVPR 2014.
[7]J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. “You only look once: Unified, real-time object detection”. CVPR 2016.
[8]W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. Reed. “SSD: Single shot multibox detector”. ECCV 2016.
[9] “Object detection with discriminatively trained part-based models”. TPAMI 2010.
[10]Robust Real-time Object Detection. Paul Viola, Michael Jones. IJCV 2004.
[11]N. Markus, M. Frljak, I. S. Pandzic, J. Ahlberg and R. Forchheimer. “Object Detection with Pixel Intensity Comparisons Organized in Decision Trees”. CoRR 2014.
[12]Shengcai Liao, Anil K. Jain, and Stan Z. Li. “A Fast and Accurate Unconstrained Face Detector,” TPAMI 2015.
[13]Dong Chen, ShaoQingRen, Jian Sun. “Joint Cascade Face Detection and Alignment”, ECCV 2014.
[14]Haoxiang Li, Zhe Lin, XiaohuiShen, Jonathan Brandt, Gang Hua. “A convolutional neural network cascade for face detection”, CVPR.2015.
[15]Lichao Huang, Yi Yang, Yafeng Deng, Yinan Yu.“DenseBox: Unifying Landmark Localization with End to End Object Detection” CVPR 2015.
[16]Taigman Y, Yang M, Ranzato M A, et al. Deepface: Closing the gap to human-level performance in face verification.CVPR 2014.
[17]Sun Y, Wang X, Tang X. Deep learning face representation from predicting 10,000 classes.CVPR 2014.
[18]Sun Y, Chen Y, Wang X, et al. Deep learning face representation by joint identification-verification.NIPS. 2014.
[19]FaceNet: A Unified Embedding for Face Recognition and Clustering. CVPR 2015.
[20]A Discriminative Feature Learning Approach for Deep Face Recognition. ECCV 2016.
[21]Rethinking the Inception Architecture for Computer Vision. CVPR 2016.
[22]Alex Krizhevsky, IlyaSutskever, Geoffrey E. Hinton. “ImageNet Classification with Deep Convolutional Neural Networks”. 2014.
[23]Murray, N., Marchesotti, L., Perronnin, F. “Ava: A large-scale database for aesthetic visual analysis”. CVPR 2012.