众所周知,Yarn是大数据核心调度组件,其使用覆盖率非常高。在“Hadoop是否已失宠”的选题调研中,不少专家都对Yarn这一核心组件的生命力表达了自己的看法。
阿里云技术专家封神认为,Yarn在离线与在线数据混合方面表现欠佳,但这也是其背景使然,支持Yarn的几家公司主要做离线系统,对在线系统部署问题关注不够。当然,目前市场已经存在具备一定竞争关系的产品,比如Mesos,但这两大调度系统的设计目标并不完全相同,并且Yarn也在朝着Mesos的领域进军。
百分点集团技术副总裁兼首席架构师刘译璟认为,Yarn与Hadoop平台的绑定过于密切,而实际上,我们有很多资源调度管理方法可供选择,比如Kubernetes等,对各种应用的支持某种程度上比Yarn更完善,无论是外部类型应用,大数据应用还是机器学习应用均可处理。
虽然在大数据应用层面不尽完美,但Yarn在支持长期运行服务方面具有很大优势,这是Yarn社区耗时一年一直在努力做的事情,本文主要介绍该服务的特点和具体使用方法。
Apache Hadoop 3.1功能——Yarn服务框架!
所谓长期运行服务支持,主要针对长期占用较多资源的应用,我们将该功能称之为Yarn服务框架。2017年11月,这一功能被整合到工具箱,总共经历了108个提交,代码更改了33539行。该功能主要包括以下内容:
1、在Yarn上运行的核心框架(ApplicationMaster),作为容器协调工具,负责管理所有服务的生命周期。
2、RESTful API服务,供用户使用简单的JSON规范在Yarn上部署和管理服务。
3、由Yarn服务注册表支持的Yarn DNS服务器,可通过其标准DNS在Yarn上查找服务。
4、高级容器设置计划,例如每个应用程序的容器大小调整和节点标签。
5、集装箱升级和整体服务。
6、Yarn服务框架与一些其他功能:
- 对Docker的支持;
- 基于HBase的本地Yarn时间线服务,用于记录生命周期事件和指标,并为用户提供丰富的分析API以获取、查询应用程序详细信息;
- Yarn UI2中的Services UI。
Yarn上管理服务的大部分复杂性都是对用户隐藏的。用户仅处理JSON规范,并通过CLI或REST API部署和管理在Yarn上运行的服务。以下是在Yarn上部署httpd容器的JSON规范示例。用户只需通过REST API或使用CLI发布此JSON规范,系统将自动处理其余内容——启动和监视容器或进行应用程序运行所需的所有操作,如容器自动重启(如果失败)。例如:
1、启动服务,请使用提供的JSON运行以下命令

2、获取应用程序状态
yarn app -status my-httpd
- 1.
3、将容器数量设置为3:
yarn app -flex my-httpd -component httpd 3
- 1.
4、停止服务:
yarn app -stop my-httpd
- 1.
5、重启已经停止的服务:
yarn app -start my-httpd
- 1.
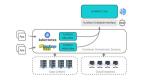
下图展示了Yarn集群在支持长期运行服务时涉及的主要组件:
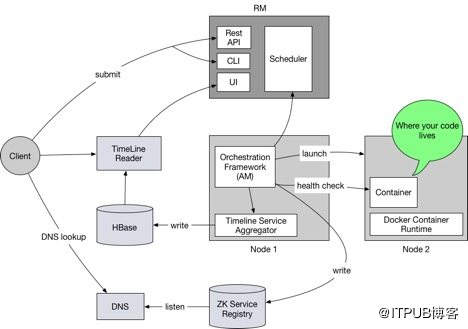
由图可见,典型的工作流程是:
- User向Yarn Service REST API发布描述服务规范的JSON请求,例如容器内存大小、CPU核心数、Docker镜像ID等。同样,用户也可以使用Yarn CLI提交服务并创建请求;
- RM在接受请求后,启动ApplicationMaster(即容器编排框架);
- 业务流程框架从RM请求资源(一定要遵守用户的资源需求),然后分配容器,在NodeManager上启动容器;
- NodeManager依次启动容器进程(用户代码所在的位置)或使用Docker容器运行时启动Docker容器;
- 业务流程框架监视容器的健康状况和准备情况,并对容器的故障或错误采取行动。它将服务的生命周期事件和指标写入Yarn时间线服务(由HBase支持),将附加服务元信息(例如容器IP和主机)写入由ZooKeeper支持的Yarn服务注册表中;
- Registry DNS服务器侦听ZooKeeper中的znode创建或删除,并创建各种DNS记录,例如A record和Service Record,以提供DNS查询;
根据JSON规范和YARN配置中提供的信息,为每个Docker容器提供用户友好的主机名。然后,客户端可以使用标准DNS通过容器主机名查找容器IP。
Yarn已被证明可以很好地支持MapReduce和Spark等批量处理工作负载,此功能还可以将现有的基于容器的服务引入Yarn。用户可以使用单个集群来运行批处理作业和支持长时间运行服务,这还可以实现批处理作业和服务之间的资源共享,服务通常在白天运行,而批处理作业通常在夜间运行,这样的资源共享极大地提高了整体集群的利用率;支持kerberos安全性,可以与标准的kerberized Hadoop集群很好地配合;除了docker容器化应用程序外,它还支持标准的tar打包应用程序。
在Hadoop生态系统中存在超过十年,Yarn已经成长为一个较成熟的项目,并在很多企业内部大规模应用。此外,Yarn Container Orchestration Framework利用了Hadoop生态中所有的稳定功能,这让Yarn成为Hadoop使用者的首要选择。正如开篇两位技术专家所言,Yarn并不是最完善的资源调度工具,但它与Hadoop生态绑定甚紧并与其中的组件完美整合,这就是Yarn最大的优势之一。