












排序一直是计算机科学中最为基础的算法之一,从简单的冒泡排序到高效的桶排序,我们已经开发了非常多的优秀方法。但随着机器学习的兴起与大数据的应用,简单的排序方法要求在大规模场景中有更高的稳定性与效率。中国科技大学和兰州大学等研究者提出了一种基于机器学习的排序算法,它能实现 O(N) 的时间复杂度,且可以在 GPU 和 TPU 上高效地实现并行计算。这篇论文在 Reddit 上也有所争议,我们也希望机器学习能在更多的基础算法上展现出更优秀的性能。
排序,作为数据上的基础运算,从计算伊始就有着极大的吸引力。虽然当前已有大量的卓越算法,但基于比较的排序算法对Ω(N log N) 比较有着根本的需求,也就是 O(N log N) 时间复杂度。近年来,随着大数据的兴起(甚至万亿字节的数据),效率对数据处理而言愈为重要,研究者们也做了许多努力来提高排序算法的效率。
大部分***的排序算法采用并行计算来处理大数据集,也取得了卓越的成果。例如,2015 年阿里巴巴开发的 FuxiSort,就是在 Apsara 上的分布式排序实现。FuxiSort 能够在随机非偏态(non-skewed)数据集上用 377 秒完成 100TB 的 Daytona GraySort 基准,在偏态数据集上的耗时是 510 秒,而在 Indy GraySort 基准上的耗时是 329 秒。到了 2016 年,在 Indy GraySort 基准上,Tencent Sort 排序 100TB 数据时达到了 60.7TB/min 的速度,使用的是为超大数据中心优化过的包含 512 个 OpenPOWER 服务器集群。然而,这些算法仍旧受下边界复杂度和网络耗时的限制。
另一方面,机器学习在近年来发展迅速,已经在多个领域中得到广泛应用。在 2012 年,使用深度卷积神经网络实现 ImageNet 图像的接近误差减半的分类是一项重大突破,并使深度学习迅速被计算机视觉社区所接受。在 2016 年 3 月,AlphaGo 使用神经网络在人工智能的重大挑战即围棋中打败了世界冠军李世石。机器学习的巨大成功表明计算机 AI 可以在复杂任务中超越人类知识,即使是从零开始。在这之后,机器学习算法被广泛应用到了多种领域例如人类视觉、自然语言理解、医学图像处理等,并取得了很高的成就。
由人类大脑结构启发而来的神经网络方法拥有输入层、输出层和隐藏层。隐藏层由多个链接人工神经元构成。这些神经元连接强度根据输入和输出数据进行调整,以精确地反映数据之间的关联。神经网络的本质是从输入数据到输出数据的映射。一旦训练阶段完成,我们可以应用该神经网络来对未知数据进行预测。这就是所谓的推理阶段。推理阶段的精度和效率启发研究者应用机器学习技术到排序问题上。在某种程度上,可以将排序问题看成是从数据到其在数据集位置的映射。
在本文中,研究者提出了一个复杂度为 O(N·M)的使用机器学习的排序算法,其在大数据上表现得尤其好。这里 M 是表示神经网络隐藏层中的神经元数量的较小常数。我们首先使用一个 3 层神经网络在一个小规模训练数据集上训练来逼近大规模数据集的分布。然后使用该网络来评估每个位置数据在未来排序序列中的位置。在推理阶段,我们不需要对两个数据之间进行比较运算,因为我们已经有了近似分布。在推理阶段完成之后,我们得到了几乎排序好的序列。因此,我们仅需要应用 O(N) 时间复杂度的运算来得到完全排序的数据序列。此外,该算法还可以应用到稀疏哈希表上。
算法
若假定我们有一个实数序列 S,它的长度为 N、上边界和下边界分别为 x_max 和 x_min。对于一个有效的排序算法,我们需要交换 x_i 的位置来确保新的序列 S' 是经过排序的。假设一个实数 x_i 在序列 S' 中的位置为 r_i,那么我们可以将排序问题视为一个双映射函数 G(x_i)=r_i。如果我们可以预先求得这个函数,那么排序算法的复杂度就为 O(N)。实际上,如果序列 S 中所有的实数都来自同一分布 f(x),且当 N 足够大时,那么 x_i 在新序列 S' 中的排位 r_i 将近似等于:
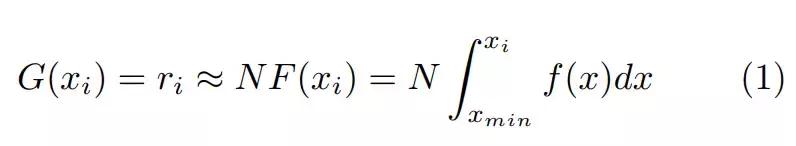
其中 F 为数据的概率分布函数,且当 N 趋向于无穷大时,表达式左右两边取等号。
这样形式化排序问题的困难时函数 G(x) 通常是很难推导的,概率密度函数 f(x) 同样也如此。然而当我们处理大数据序列时,N 会足够大以令序列保持一些统计属性。因此如果我们能推出概率密度函数 f(x),那么就有机会根据上面所示的方程 1 降低排序算法的复杂度到 O(N)。
在这一篇论文中,作者们应用了广义支持向量机(General Vector Machine,GVM)来逼近概率密度函数 f(x)。这种 GVM 是带有一个隐藏层的三层神经网络,且它的结构展示在以下图 1 中。GVM 的学习过程基于蒙特卡洛算法而不是反向传播,作者们也发现 GVM 非常适合拟合函数。
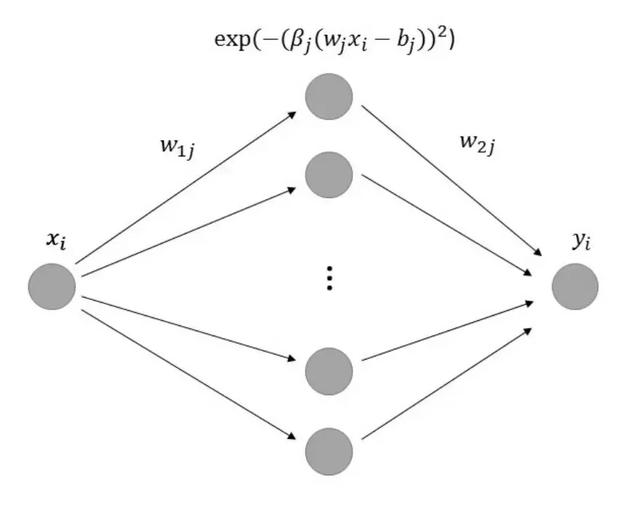
图 1:GVM 的简单图示。研究者在每个实验中固定 M 为 100 个隐藏层神经元。
在该神经网络中,输入层仅有一个神经元且输入是用于拟合函数的 x_i,输出层也只有一个神经元,输出为 y_i。研究者修改了隐藏层的神经元数量为 M=100。实际在某种程度上,隐藏层的神经元越多拟合的精度就越大,但同时也伴随着过拟合问题,以及计算效率降低的问题。
N 个实数的排序估计过程仅需要 O(N·M) 的时间。M 与 N 是互相独立的,且在理论分析上 M 是没有下界的。例如如果数据序列服从高斯分布且我们只使用一个隐藏神经元,那么计算复杂度就为 log(N)。特别地,我们也可以用多个神经元拟合高斯分布,神经元的数量依赖于机器学习方法。
在预测过程中,这种算法不需要比较和交换运算,并且每个数据的排序估计都是互相独立的,这使得并行计算变得高效且网络负载小。除了高效并行计算之外,由于机器学习需要矩阵运算,它还适用于在 GPU 或 TPU 上工作以实现加速 [19]。
实验
如图 2 所示,我们选择两种分布进行实验:均匀分布和截尾正态分布。
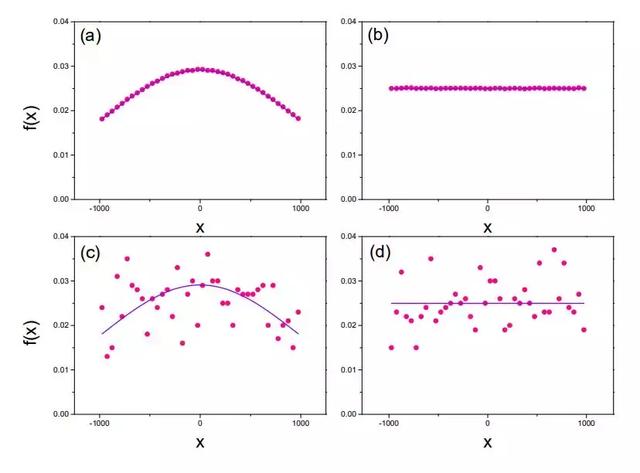
图 2:数据分布。(a)截尾正态分布和(b)均匀分布的 107 个数据点。(c)截尾正态分布和(d)均匀分布的训练序列分布的 103 个数据点。紫色实线是解析分布,粉色点线是实验数据。
图 3 对比了 Tim Sorting 和 Machine Learning Sorting 的运行时间。
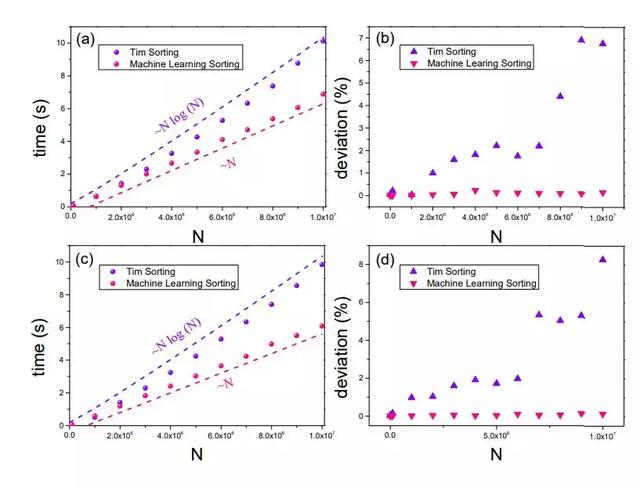
图 3:(a)截尾正态分布的数据数量和时间复杂度的关系。(b)截尾正态分布的数据数量和时间复杂度离均差的关系。(c)均匀分布的数据数量和时间复杂度的关系。(d)均匀分布的数据数量和时间复杂度离均差的关系,研究者使用了 102 次实现的总体均值来获得结果。
论文:An O(N) Sorting Algorithm: Machine Learning Sorting

论文地址:https://arxiv.org/pdf/1805.04272.pdf
我们提出了一种基于机器学习方法的 O(N) 排序算法,其在大数据排序应用上有巨大的潜力。该排序算法可以应用到并行排序,且适用于 GPU 或 TPU 加速。此外,我们还将该算法应用到了稀疏哈希表上。



















