从容器革命开始就有两件事情变得清晰起来:首先,技术堆栈中各层的脱钩产生了清晰的,原则性的分层概念,具有明确的约定,所有权和责任。其次,引入这些层使开发人员能够专注于对他们至关重要的事情--应用程序。
公平地说,这已经发生过,***代平台即服务(PaaS)正式旨在使开发人员能够采用“无服务器计算”体系结构。问题在于,就像在许多***波产品中一样,太多重叠的概念被混合到一个单一的整体产品中。就大多数***代PaaS而言,开发人员经验,无服务器计算和定价模式(基于请求的)都是以不可分割的整体形式混合在一起的。因此,可能想要采用无服务器计算但可能满足开发人员要求(例如特定编程语言),或想要大型应用程序的更具成本效益的定价模型的用户不得不放弃无服务器计算。
容器的开发改变了所有这些,从无服务器计算运行时中解耦开发人员的要求。然而,过去一年已经看到无服务器计算容器基础设施的发展并不令人意外。去年七月,Azure发布了Azure容器实例,这是***个在主要公有云中无服务器计算容器产品。看到重要的用户对无服务器计算基础设施的兴趣,其他公有云遵循Azure的领先地位,Fargate在六个月后在RE:Invent 2017上宣布,我认为在所有公有云中无服务器计算容器基础架构都可用之前只是一个时间问题。
随着我们前进,至少对我来说变得越来越清晰,未来将被容器化,而这些容器将在无服务器计算的基础设施上运行。
那么在这种情况下,一个显而易见的问题就是:“在这个无服务器计算的未来,协调工作会变成什么样子?”
Kubernetes是一种开发用于提供无服务器计算需求的运行容器的技术。但事实是,在低层次上,Kubernetes架构本身支持单个机器,并且从调度器到控制器管理器的组件假定Kubernetes中的容器运行在其可见的机器上。
像Azure容器实例这样的无服务器容器基础架构是原始基础架构。虽然它是轻松运行一些容器的好方法,但构建复杂的系统需要开发一个编排器来引入更高层次的概念,如服务,部署,秘密等。
对于这些无服务器计算平台,开发一个全新的协调器可能是很有吸引力的,但事实是世界正在围绕Kubernetes编排API进行整合,并且与现有Kubernetes工具的无缝集成非常有吸引力。此外,在可预见的将来,我预计大多数人的Kubernetes集群将是专用机器和无服务器计算容器基础设施之间的混合体。专用机器将用于相对静态使用的稳态服务或专用硬件,如FPGA或GPU,而无服务器容器将用于突发或瞬时工作负载。
虚拟Kubelet与Kubernetes和无服务器容器相结合
Kubernetes社区面临的一个有趣问题是如何将无服务器计算容器基础架构与更高级别的Kubernetes概念相结合。最近,开源虚拟kubelet项目的开发在Kubernetes节点和调度特殊利益集团(SIG)内推进了这一讨论。
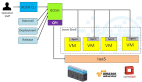
其核心虚拟kubelet项目旨在弥合无服务器计算容器和Kubernetes API之间的差距。正如从名字中可以看出的那样,虚拟kubelet是Kubernetes kubelet守护进程的替代实现,它将虚拟节点投影到Kubernetes集群中。这个虚拟节点表示无服务器的容器基础设施,使Kubernetes调度程序知道它可以将容器调度到无服务器容器API的事实。
当虚拟kubelet启动时,它将自己注册到Kubernetes API服务器,并立即启动Kubernetes API服务器的心跳协议,以便它添加到Kubernetes的虚拟节点看起来健康。你可以在下面的屏幕截图中看到这个过程。最初有一个标准的Kubernetes集群,其中有三个实际节点存在于集群中。然后,我们开始在此群集中运行虚拟kubelet作为容器,并将第四个节点添加到群集中。这第四个节点是虚拟节点,代表无服务器计算容器基础结构。当然,这个节点实际上是一个相当特殊的节点,因为它代表了在Azure容器实例等无服务器基础设施上运行容器的***容量。
鉴于在无服务器计算基础架构上运行的容器与在Kubernetes计算机上运行的容器之间的定价和特性的差异,虚拟kubelet要求用户必须显式选择在新虚拟节点上运行容器。为了达到这个目的,虚拟kubelet使用Kubernetes的概念和容忍度。添加时,虚拟节点将标记为Kubernetes污点,防止将任意Pod传送到虚拟节点。只有当一个pod表明它愿意容忍这个无服务器的污点时,它才会考虑调度到虚拟节点上。
一旦将pod安排到无服务器计算虚拟节点上,虚拟kubelet会注意到这一点,并着手在无服务器基础架构中实际创建容器。在无服务器计算基础架构中成功创建Pod之后,虚拟Kubelet还负责将健康和状态信息报告给Kubernetes API服务器,以使所有API和工具按预期工作。
Kubernetes和无服务器计算容器基础架构的这种联合在批处理或突发性工作负载方面有各种实际用例。例如,正在进行图像处理的客户可以快速启动大量容器,以处理最近一次将图像上传到共享存储区,在几秒钟内就可以从无基础架构转移到数百个处理图像的容器,并且在此处理完成后,他们立即回去为容量付钱。这与在虚拟机之上运行的Kubernetes群集形成了鲜明的对比,无论这些机器是否在使用,运行机器的成本都是不变的。同时,这种图像处理的实际编排可以使用标准的Kubernetes概念来实现,例如可以调度所有这些图像处理容器的Job对象。
使Kubernetes与无服务器容器兼容
看到虚拟kubelet项目在云计算行业的发展和增长势头真是令人兴奋,从创业公司到公有云的众多不同合作伙伴加入并贡献了将无服务器容器与Kubernetes结合在一起的愿景。
当然,这并非一帆风顺。就像我们一样
Kubernetes和无服务器计算的未来
Kubernetes的建立是为了给开发人员一个干净的,面向应用的API,使他们忘记了机器和机器管理的细节。但事实是,在这个API表面下,机器还在那里。无服务器计算容器基础架构的发展使人们可以开始完全忘记这些机器,但是为大规模应用程序成功使用无服务器计算容器需要开发一个协调器。因此,Kubernetes编排层和无服务器容器基础架构的集成对Kubernetes和无服务器基础架构的未来成功至关重要。
随着我们迈向未来,我完全相信未来的Kubernetes集群将包含运行在专用机器上的容器组合以及突破无服务器计算基础设施。但是,尽管未来的目的地在我心中是清楚的,但我们如何到达那里的路径和细节仍有待确定。我非常高兴能与Kubernetes社区进行公开讨论。如果你有兴趣参与,请加入我们的虚拟kubelet github项目,或者参加SIG-Node和SIG-Scheduling的邮件列表或会议。我非常高兴能够共同构建这一新一代的容器编排。这就是我们的容器化,无服务器的未来!
作者介绍:
Brendan Burns,Kubernetes的联合创始人,目前任微软分布式工程师。领导微软Azure云容器开发,Azure容器实例化,Azure云shell及资源管理,居住在华盛顿州西雅图市。