












在这个数据为王的时代,如何存储及分析海量数据,是个不那么容易的事情。近年来,图数据库逐渐映入我们眼帘,已成为NoSQL中关注度***,发展趋势最明显的数据库之一。图数据库,他是谁?从哪儿来?牛在哪儿?怎样助力研发工作?且听京东攻城狮怎么说。
他是谁
图数据库并不是存储图片的数据库,参照维基百科的定义,他是“以图数据结构来实现语义查询,并以节点(node)、边(edge)、属性(properties)来表示并存储数据”。是不是听完感到一脸懵?
用大白话来讲,图数据库就是以“图数据结构”来存储并查询数据。
如果你连什么是“图数据结构”都不知道,那你的数据结构一定是体育老师教的,请回去自行复习《数据结构与算法》这本经典教材。
让我们再回到图数据上,看看他的一些关键核心概念,图数据库源于图理论,具有如下几个特征:
- 节点(node):通常表示实体,例如人员、账户、事件等,相当于RDBMS中的一行记录。
- 边(edge):又被称为关系(relationships),具有名字和方向,从一个节点指向另一个节点,边是图数据库中最显著的一个特征,在RDBMS中没有对应实现。
- 属性(properties):类似KV数据库中的键值对,节点和边都可以有属性。
图数据库将数据以属性方式存储在节点或边中,以边来表示节点之间的关系,并用特定查询语言,进行数据检索。
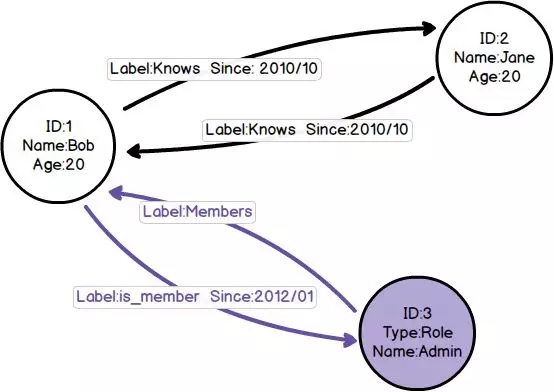
节点、边、属性示意图
他从哪儿来
从图数据库的原型出现至今,已经发展超过了半个世纪。图数据库的前身,可以追溯至上世纪60年代的Navigational databases,IBM开发了类似树形结构的数据存储模型。到1969年的网络数据库语言(Network database language),支持图数据结构的展现。
又经过漫长的30年,其间出现过可标记的图形数据库Logic Data Model,直至21世纪初,人们研发出具有ACID特性的里程碑式图数据库产品,例如:Neo4j、Oracle Spatial and Graph。
到2010年后,可支持水平扩展的分布式图数据库开始兴起,例如OrientDB,ArangoDB,MarkLogic。至今,各式各样的图数据库越来越受到重视,在Google、LinkedIn、Facebook这些***大公司中,已经有了广泛应用,迎来了他***的时代。
他牛在哪儿
在传统关系型数据库RDBMS中,并没有明确的关系概念,或许叫表格数据库更贴切,而图数据库,恰恰是表现实体之间关系的利器。
在表现实体间关系时,RDBMS会将另一个实体的唯一标识,存储到表中的某一列,来与其他实体进行关联,例如典型的主键、外键。当遇到多对多关系时,典型做法会引入中间表,来存储两个实体ID间的关系,例如我们最熟悉的用户角色多对多关系。在查询时,需要多个表进行join连接,依次查询所需信息。
而图数据库,会直接存储两个实体之间的关系。仍以用户角色多对多关系举例,用户实体会有一个指针直接指向对应的角色记录,而这个指针,就是上文所述的“边(edge或relationships)”。而这样存储的好处是,当查询用户和角色时,只查询用户就可顺着“关系”直接取到角色信息,消除了RDBMS表关联所花费的性能开销。
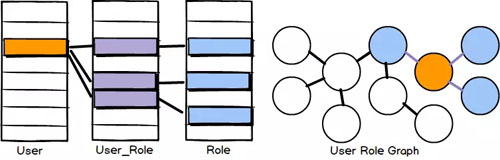
用户角色关系不同存储方式示意图
当然,上述图数据库和RDBMS的对比只是举了一个非常简单的例子。
图数据库真正的价值,是灵活存储复杂关联关系,在深度超过1层以上关系中查找遍历,或是基于复杂算法的实时数据关系挖掘。
在电商推荐引擎中,通常需要整合商品、客户、供应商、物流等关键信息,挖掘用户可能感兴趣的商品。而图数据库可以快速记录这些大量复杂关系,实时为用户提供可能所需产品。
在社交网络图谱场景中,可记录用户社交关系,查找直接或间接认识的人,查找交际网中***影响力的人物,这些操作对于图数据库都是易如反掌。
在搜索引擎场景中,利用图数据库形成知识网络,当用户输入关键词检索时,和关键词义衍生的其他条目也可展现出来,在大量数据下,可轻松维护这些知识的相互联系。
在路径规划场景中,存储各站点之间的关联,并实时计算出***路径…
图数据库还有其他诸多应用场景,当遇到大数据量的复杂实体关系存储、查询及可视化,都可以考虑使用图数据库。
当然人无完人,他在解决复杂关系存储及查询时有着诸多便利,但当记录大量结构化的数据时,就比不上传统大数据存储工具了,例如ES、HBase等。所以我们建议在实际生产环境中,混合使用传统RDBMS和图数据库。
谁能站在图数据库的C位
图数据库有如此多的优势,我们团队也尝试在实际项目中落地,调研了若干开源图数据库引擎,下面是简单的横向对比,供各位参考。
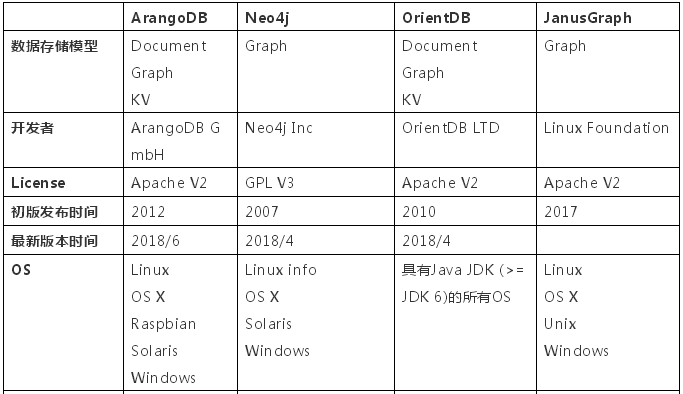
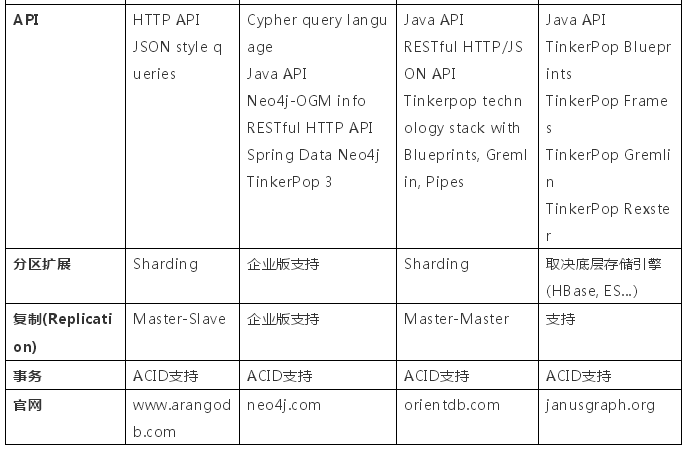
通过以上对比可以得知:
- Neo4j是最早起家做Graph DBMS,产品非常成熟,但是cluster和replication均需要企业收费版支持,且是GPL V3授权,假如将其用于商业目的,也需要缴纳版权费用。
- JanusGraph是基于Titan图数据库延续下来的开源项目,由Linux Foundation进行维护。它并不是原生的图数据库引擎,而是底层使用ES、HBase等传统结构存储,并在上面封装图查询API。
- ArangoDB和OrientDB均支持Document、Graph及KV存储,分区扩展及备份完善,具有ACID事务支持。
在技术选型时,有几个特性我们需要着重考虑:
- 授权,是否商业付费;
- 底层存储,有一些图数据库底层仍使用传统RDBMS存储,仅在上层封装图查询API,所以在大数据量关系查询时,也许性能不如人意;
- 分布式支持,为了应对大数据量,在生产环境应能够水平拆分及复制备份。
结合以上几点考虑,我们团队目前选择了OrientDB进行下一步落地开发。
他怎样助力逆向处置团队
目前,逆向处置团队一些有想法的小伙伴们已经搭上图数据库这趟列车,推动技术创新在实际业务中的应用,进行一些特定场景的数据开发工作。如存储客户关系资料、咨询事件、订单、服务单等信息。在知识库项目中也有尝试,用于开发知识图谱特性,建立知识的深层次联系。
对于互联网公司来说,核心竞争力源于技术,同时对技术的不断创新,或是对创新技术的应用,亦是推动公司和团队发展和进步的重要手段之一。
上述内容为我们团队在近期研发中做出的大胆探索并取得的一些心得,在此与大家分享。如果这篇文章也激发了你对图数据库的兴趣,欢迎与我们一同学习,共同探讨。




















