项目简介
有人说,这个时代,只要站在了风口,猪都能飞起来,尤其互联网行业,千变万化,日异月殊,一不小心就错过了风口,如果没记错的话,前几年火的是App开发,后来是大数据,再接着是人工智能,现在则是区块链,有人甚至用币圈一日互联网十年来形容虚拟币和区块链的火爆,如果单从热点看,大数据貌似有点out了,那究竟如何呢?今天就对拉勾网上的数据分析职位的相关信息来一个探索性分析。
数据集
之所以采用拉勾网(201712)的数据,是由于在互联网垂直招聘领域,拉勾网坐***把交椅,无论是职位数量还是职位有效性,都优于其它渠道。
本次采用的数据集主要有以下变量:薪酬下限、薪酬上限、工作地点、经验要求、学历要求、工作时间、公司、所处行业、公司融资情况、投资机构、岗位要求等。
目的
通过实际数据来看看数据分析一职的现况如何,薪资是否还有吸引力等,具体来说,探索以下几个问题:
- 数据分析职位在各城市的需求对比;
- 数据分析师的待遇情况;
- 工作经验要求;
- 互联网热点城市的待遇情况;
- 工作经验对待遇的影响;
- 学历对待遇的影响;
- 需要掌握的技能;
- 哪些技能更吃香;
- 不同的经验要求是否意味着不同的技能要求。
分析工具
在Jupyter Notebook中以Python3及其pandas、matplotlib、seaborn 和 wordcloud包为主进行分析。下面开始正式分析。
数据整理
前期准备工作,由于matplotlib包使用的默认字体不支持中文,所以得修改配置,用文本编辑器打开下面命令得到的路径中的 matplotlibrc文件,将以 font.family和 font.sans-serif开头的两行前的注释符(#)删掉,并在“font.sans-serif:”后加上SimHei,更改后结果如 font.sans-serif : SimHei, msyh, DejaVu Sans, ......;再将附带的字体文件放入matplotlib同级目录下的\fonts\ttf目录中。
- import matplotlib
- print(matplotlib.matplotlib_fname())
接着删除下面命令得到的用户目录中.matplotlib下的所有带cache的文件及文件夹后重启 Jupyter Notebook。
- print (matplotlib.get_configdir())
准备工作完成,下面正式读取数据并整理。
- # python3
- # _*_ coding:utf-8 _*_
- # 导入所需的包
- import numpy as np
- import pandas as pd
- import seaborn as sns
- import matplotlib.pyplot as plt
- from wordcloud import WordCloud
- % matplotlib inline
- matplotlib.rcParams['font.sans-serif'] = ['SimHei']
- # 读取数据
- df = pd.read_excel('la_gou.xlsx')
- # 删除不需要的变量
- df_clean1 = df.drop(['Index', 'home_page', 'address', 'url', 'date_time'],axis=1)
- # 删除冗余行
- df_clean = df_clean1.drop_duplicates(['company', 'title', 'description'])
- df_clean=df_clean.reset_index(drop=True)
- df_clean.info()

经过处理后的数据有16个变量,1766个观测值,其中投资机构(investor)缺失值太多,不过它不是这次分析的重点,影响不大。
探索数据
一、职位在地域方面的区别:
- city_series = df_clean['city'].value_counts()
- y_cor = list(city_series.values)
- x_cor = list(np.arange(len(y_cor)))
- city_series.plot(kind='bar', figsize=(18,10), fontsize=15, rot=40);
- for x,y in zip(x_cor,y_cor):
- plt.text(x, y+1, '%s' % y, ha='center', va= 'bottom',fontsize=14);
- plt.title(u'各城市职位数量', size = 18);
- plt.show();
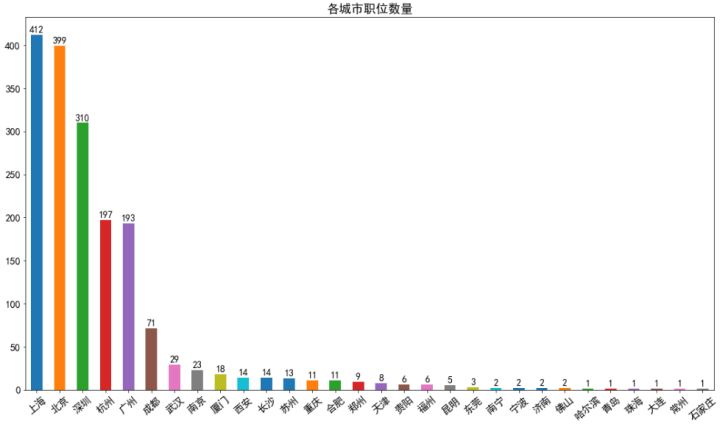
分析结果显示,与以往媒体报道的北京互联网发展***不同,上海至少在数据分析职位方面的需求超过了北京,但也只是略超,同时,深圳与上海和北京相比,需求数量差距也不是非常大,其次杭州和广州的需求比较大,且两者几乎无差距,再者就是成都有一定需求,其它城市的需求非常少。总体来说与人们对互联网强城市的印象相符。
二、薪资概况:
- # 由于招聘给出的薪资是一个区间,故采用其上限和下限间的中值进行分析
- df_clean['salary_median'].hist(figsize=(10,6), bins=30, edgecolor='k', grid=False);
- plt.xlabel(u'薪资(千/月)', size=15);
- plt.ylabel(u'频数', size=15);
- plt.title(u'薪资分布', size=18);
- plt.xticks(range(0,90,5), size=15);
- plt.yticks(size=15);
- plt.grid(axis='y', alpha=0.2);
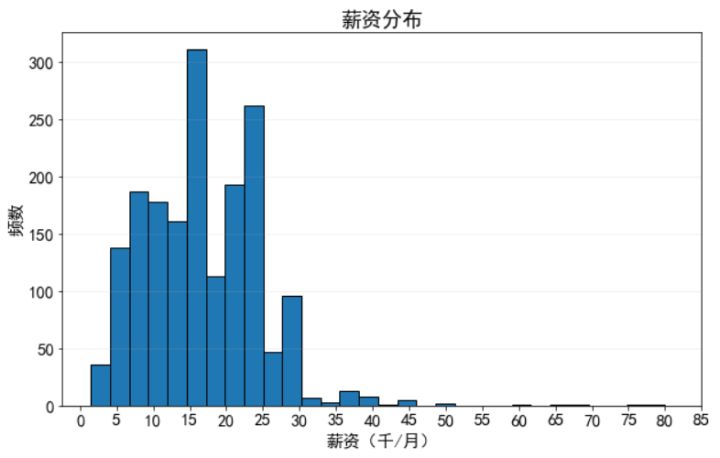
从分布看,薪资差异较大,有大量五千到两万五之间的职位,超过三万的***,***有达到七万多的,与人们印象不同,并不是每个数据分析师都能"月薪过万",低于一万的也有一定比例,但最多的还是一万五到一万七的,总的来说,待遇非常吸引人。
三、工作经验要求:
- # 应届毕业生和10年以上人数很少,将应届毕业生归类到一年以下,将10年以上归类到5-10年,并去掉空格
- for i in df_clean.index:
- df_clean.loc[i,'experience'] = df_clean.loc[i,'experience'].strip()
- if df_clean.loc[i,'experience'] == u'应届毕业生':
- df_clean.loc[i,'experience'] = u'1年以下'
- if df_clean.loc[i,'experience'] == u'10年以上':
- df_clean.loc[i,'experience'] = u'5-10年'
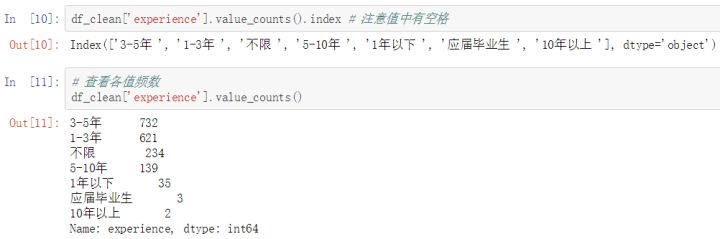
- experience_freq = df_clean['experience'].value_counts()

- experience_sort = pd.Series([38, 621, 732, 141, 234], index=[u'1年以下',u'1-3年',u'3-5年',u'5-10年',u'不限'])
- experience_sort.plot(kind='bar',figsize=(8,5), fontsize=15, rot=0);
- plt.grid(color='#95a5a6', linewidth=1,axis='y',alpha=0.2)
- plt.xticks(range(5), experience_sort.index, size=15)
- plt.ylabel(u'频数', size=15);
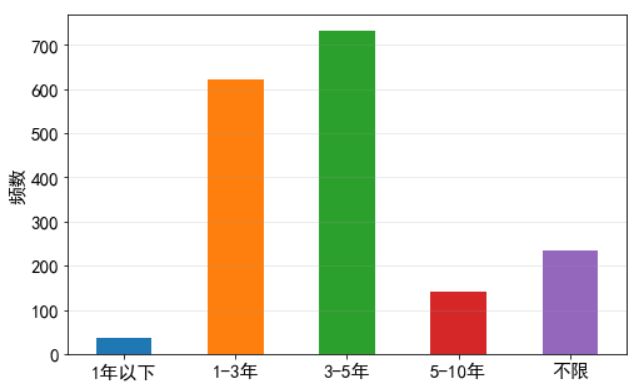
绝大部分岗位都要求有工作经验,3-5年的最多,其次是1-3年的,5-10年的专家级也有一定需求,还有一些不限经验的,可能是忘记填写或实习之类的。
四、互联网热点城市薪资概况:
- salary_groupby_city = df_clean.groupby('city')['salary_median']
- large_city = city_series[0:6].index
- salary_of_city = []
- for city in large_city:
- salary_value = salary_groupby_city.get_group(city).values #得到各城市对应的薪水的数组
- salary_of_city.append(salary_value)
- plt.style.use('seaborn-darkgrid')
- matplotlib.rcParams['font.sans-serif'] = ['SimHei']# 对于有些seaborn的style,必须同时运行此命令,否则还是不显示中文
- plt.figure(figsize=(10,5));
- plt.boxplot(salary_of_city, boxprops = {'color':'blue'},
- flierprops = {'markerfacecolor':'red','color':'black','markersize':4});
- plt.title(u'互联网热点城市薪资分布', size=18);
- plt.ylabel(u'薪资(千/月)',size=15);
- plt.xticks(np.arange(6)+1,large_city, size=15);
- plt.yticks(size=15);
- plt.grid(color='#95a5a6', linewidth=1,axis='x',alpha=0.2);
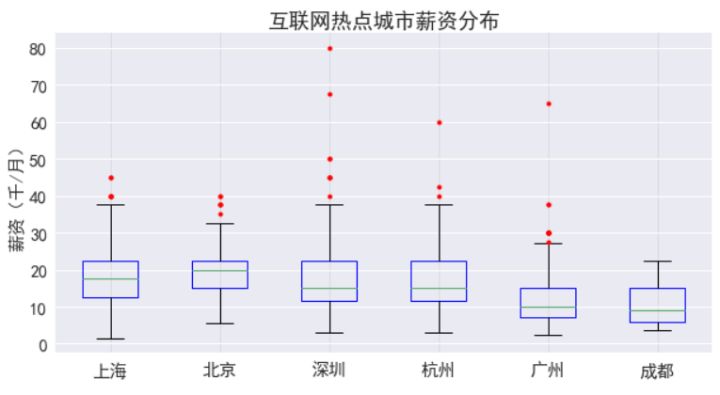
从结果看,北京的月薪中位数***,在2万元,其次是上海,在1.75万左右,深杭在1.5万左右,广州成都只有1万,但薪资***的职位在深圳。
五、工作经验对薪资的影响:
- salary_groupby_experience = df_clean.groupby('experience')['salary_median']
- salary_of_experience = []
- for experience in experience_sort.index:
- salary_value = salary_groupby_experience.get_group(experience).values
- salary_of_experience.append(salary_value)
- plt.figure(figsize=(10,5));
- plt.boxplot(salary_of_experience, boxprops = {'color':'blue'},
- flierprops = {'markerfacecolor':'red','color':'black','markersize':4});
- plt.title(u'不同工作经验的薪资待遇', size=18);
- plt.ylabel(u'薪资(千/月)',size=15);
- plt.xticks(np.arange(5)+1,experience_sort.index, size=15);
- plt.yticks(size=15);
- plt.style.use('seaborn-darkgrid');
- matplotlib.rcParams['font.sans-serif'] = ['SimHei'];
- plt.grid(color='#95a5a6', linewidth=1,axis='x',alpha=0.2);
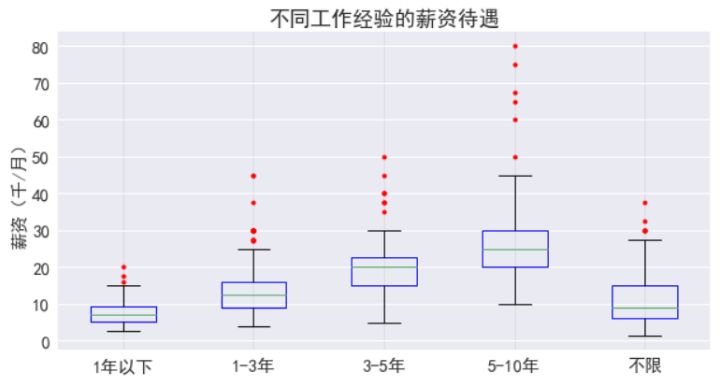
可见经验越久,待遇越高,有5年经验的薪资中位数***也有2万,远比传统行业高。
六、学历对薪资的影响:
- edu_sort = pd.Series([52,170,1465,78,1], index=[u'不限',u'大专',u'本科',u'硕士',u'博士'])
- salary_groupby_edu = df_clean.groupby('education')['salary_median']
- salary_of_edu = []
- for education in edu_sort.index:
- salary_value = salary_groupby_edu.get_group(education).values
- salary_of_edu.append(salary_value)
- plt.figure(figsize=(10,6));
- plt.boxplot(salary_of_edu, boxprops = {'color':'blue'});
- plt.title(u'不同学历的薪资待遇', size=18);
- plt.ylabel(u'薪资(千/月)',size=15);
- plt.xticks(np.arange(5)+1,edu_sort.index, size=15);
- plt.yticks(size=15);
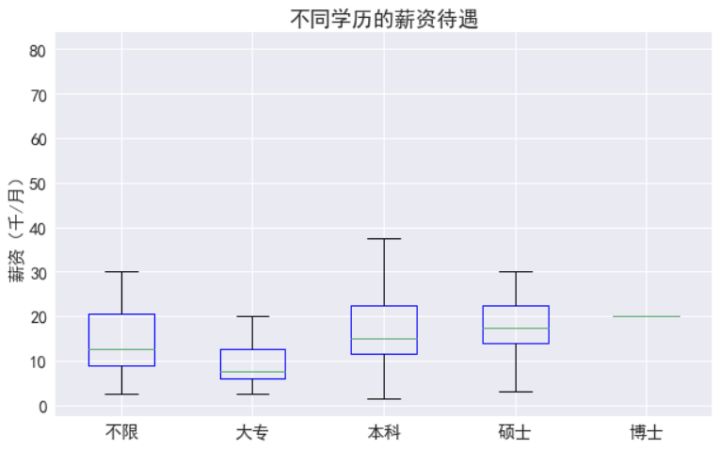
其中不限学历的可能由于招聘者忘记选择,也可能由于其是新兴领域,更看重实际能力而非学历,对于有明确要求的,大专明显低于本科和硕士,本科和硕士的差距倒不是特别大,只是硕士的起薪要高。
七、工作技能要求:
- # 添加技能列
- import re
- def get_skill(text):
- skill_list = re.findall('([a-zA-Z][0-9a-zA-Z]+|C\#|\.Net|R\d?|A\/B|算法)', text)
- for skill in skill_list:
- if skill.upper() == 'EXCEL' or skill.upper() == 'PPT':
- skill_list[skill_list.index(skill)] = 'office'
- return ','.join(skill_list).upper()
- df_clean['skill'] = df_clean['description'].apply(get_skill)
- # 生成技能字典
- import nltk
- skill_list = []
- for i in df_clean.index:
- if len(df_clean.loc[i, 'skill']) > 0:
- skill_list.extend(df_clean.loc[i, 'skill'].split(','))
- skill_freq = dict(nltk.FreqDist(skill_list))
- # 删除主要的提取错的键值
- del skill_freq['AND']
- del skill_freq['TO']
- del skill_freq['IN']
- del skill_freq['DATA']
- del skill_freq['THE']
- del skill_freq['OF']
- del skill_freq['KPI']
- del skill_freq['APP']
- del skill_freq['WITH']
- del skill_freq['SERVER']
- wc = WordCloud(width=800, height=400, background_color='white').generate_from_frequencies(skill_freq)
- plt.figure(figsize=(8,4));
- plt.imshow(wc);
- plt.axis('off');
- plt.show();

可见,SQL,Office(主要是Excel和PPT)是需求***的,是绝大多数要求必须掌握的;其次,Python,算法和R的需求也很大,另外SAS,SPSS,Hadoop,Hive的需求也不小。
八、查看主流技能的薪酬平均中值:
- # 选取需求最多的20个技能
- skill_sort = sorted(skill_freq.items(), key=lambda item:item[1], reverse=True) #对技能频数字典按值从大到小排序
- hot_skill_list = skill_sort[0:20]
- hot_skill_salary_mean = {} # 存放技能中值的均值的字典
- for i in hot_skill_list: # i 为技能和其频次的列表的元素
- for j in df_clean.index:
- if i[0] in df_clean.loc[j, 'skill']: # 如果技能在数据框的技能列中
- if i[0] in hot_skill_salary_mean: # 如果技能在技能中值的均值的字典中
- # 技能键的值为原值加上新值
- hot_skill_salary_mean[i[0]] = hot_skill_salary_mean[i[0]] + df_clean.loc[j, 'salary_median']
- else:
- hot_skill_salary_mean[i[0]] = df_clean.loc[j, 'salary_median']
- hot_skill_salary_mean[i[0]] = hot_skill_salary_mean[i[0]] / i[1] # 技能中值的均值为之前计算的和除以技能频数
- hot_skill_salary_mean = sorted(hot_skill_salary_mean.items(), key=lambda item:item[1]) #排序
- hot_skill_salary_mean #排序后返回由含字典元素的元组构成的列表
- hot_skill_freq = [] #把前20个技能的需求频数提取出来
- for i in hot_skill_salary_mean:
- hot_skill_freq.append(skill_freq[i[0]])
- hot_skill_freq # 排序会按其薪酬均值从小到大
- hot_skill_salary_key = [] # 热门技能名称列表
- hot_skill_salary_values = [] #热门技能的中值的均值列表
- for i,j in dict(hot_skill_salary_mean).items():
- hot_skill_salary_key.append(i)
- hot_skill_salary_values.append(j)
- plt.figure(figsize=(10,6));
- plt.scatter(x = np.arange(len(hot_skill_salary_values)), y=hot_skill_salary_values, s=hot_skill_freq);
- plt.xticks(np.arange(len(hot_skill_salary_values)), hot_skill_salary_key, size=15, rotation=40);
- plt.yticks(size=15);
- plt.title('不同技能可以拿到的薪资中位数的均值', size=18);
- plt.ylabel('千/月', size=15);
- plt.ylim((5,26));
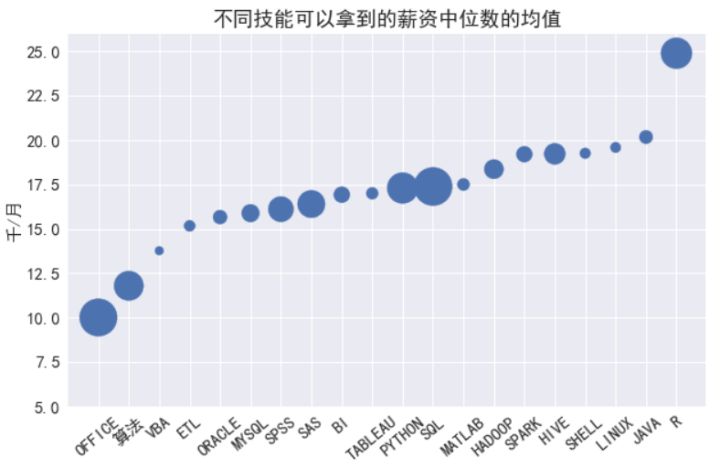
泡泡大小代表了需求量,从结果看,会R的薪资***,但这只是高薪的必要条件,而非充分条件,另外算法太低,可能是由于大多数岗位需求里都提到了算法,进而拉低了其均值,如果进一步分析,应该能得出比较贴合实际的数据,或者也可直接将此项剔除,分析其它岗位如深度学习机器学习的薪资来得到算法的薪资均值。Java是走向高级开发必不可少的路,Hadoop,Spark,Hive仍然是数据分析类职位的高薪必备技能。
九、看看主要工作经验对主流技能的要求是否有差别:
- # 生成字典,来存放两种经验对应的主流技能需求数
- skill_by_exp13 = {}
- skill_by_exp35 = {}
- df_skill_13 = df_clean[df_clean['experience']=='1-3年'][['experience', 'skill']]
- df_skill_35 = df_clean[df_clean['experience']=='3-5年'][['experience', 'skill']]
- for i in hot_skill_salary_key:
- for j in df_skill_13.index:
- if i in df_skill_13.loc[j, 'skill']:
- if i in skill_by_exp13:
- skill_by_exp13[i] = skill_by_exp13[i] + 1
- else:
- skill_by_exp13[i] = 1
- for i in hot_skill_salary_key:
- for j in df_skill_35.index:
- if i in df_skill_35.loc[j, 'skill']:
- if i in skill_by_exp35:
- skill_by_exp35[i] = skill_by_exp35[i] + 1
- else:
- skill_by_exp35[i] = 1
- ind = np.arange(len(skill_by_exp13))
- width = 0.35
- sns.set(context='notebook', style='darkgrid', palette='muted', font='simhei')
- plt.figure(figsize=(12,6));
- plt.grid(color='white', linewidth=1,alpha=0.3);
- plt.bar(ind, pd.Series(skill_by_exp13).values, width, label='1-3年');
- plt.bar(ind + width, pd.Series(skill_by_exp35).values, width, label='3-5年');
- plt.title('不同工作经验对主流技能的需求对比', size=18);
- plt.xticks(ind+width/2, pd.Series(skill_by_exp13).index, size=15, rotation=40);
- plt.yticks(size=15)
- plt.legend();
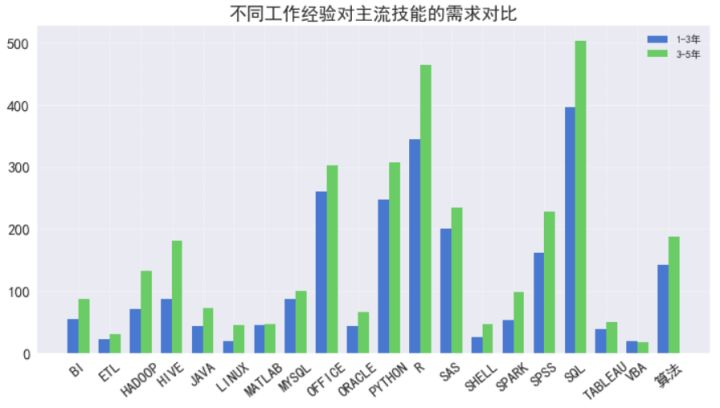
几乎所有主流技能,3-5年工作经验的需求量都比1-3年的多,但这很大可能是因为3-5年的招聘数本身就比1-3年的多100个左右,但我注意到,对Matlab、MySQL、VBA及Tableau的需求两者相差无几,VBA方面3-5年的甚至低于1-3年的,这说明3-5年经验要求的对这四种技能的需求不如1-3年的多。
结论汇总
- 对数据分析一职的需求主要集中在北上广深杭,其中北京和上海***,深圳需求紧随其后,广州和杭州相比上海和北京需求减半,但比起其它城市依然不少。
- 大多数职位提供的薪资中值在5千到2万5之间,很少有给出3万的,但也有极少数岗位,给出了五六万的高薪。
- 大多数岗位要求有工作经验,要求有3-5年经验的最多,其次是1-3年的,不要求或只要求不到一年的很少。
- 互联网发展热门城市中,北京给出的薪资的中值***,达到了2万元,上海紧随其后,比北京低一两千,杭州和深圳基本持平,基本在1万5左右,这有点出人意料,考虑到置业成本,去杭州貌似比深圳更好,广州和成都的中值在1万左右,可见,至少在数据方面,杭州的发展已经超过广州这个一线城市了。
- 工作经验与薪资密切相关,1-3年经验的薪资中值大部分超过了1万,3-5年的都在1万5以上,而5年以上的,薪资中值都在2万以上。
- 学历方面,硕士对本科的优势不是很明显,但下限是肯定高于本科的,大专相比本科劣势就比较明显了,薪资低不少,而博士相对硕士也有很大优势,但需求少。
- 技能方面,office(主要是excel其次少部分PPT)和SQL需求最多,Python、R、算法紧随其后,Hadoop、SPSS、Hive、SAS、和Spark的需求也不少。
- 对于拿到高薪的必要条件,R优势***,其次是Java,Linux等,当然这些条件并非单一满足,一般要同时会其它高级技能才能拿到高薪,显然这已经不是基础的数据分析需要的技能了,可能侧重于数据挖掘和建模等。
- 要求3-5年经验的和要求1-3年经验的在技能需求上没有太大差别,对于这条结论不是很有把握,不是太符合逻辑,等日后再详细分析。
思考·总结
通过这次分析,深切的感受到了思路的重要性,如果你对探索数据没有好奇心,没有一点自己的想法,那真可谓无处下手,不知道该分析什么,正所谓思路为“道”,工具为“术”,分析之前,得先给自己提出几个想探索的问题,或想验证的假设,当然这点不是非得一步到位,也可以循序渐进,随着分析的不断进行再开展新的探索。
“术”方面的工具技能也很重要,有时候你不知道那个函数的用法,不知道那个参数的设置,可能找很久都找不到,比如对柱状图添加文字说明,起初我按照搜索到的方法添加,可就是不出效果,搜了好几种方法都不行,无奈之下我只得把别人的代码截图一行一行敲下来运行验证,***发现是因为没放在一个cell里这个低级原因,当然,这个过程中我又学到了别的知识。术方面还有一点需要说的是,早期seaborn包会对matplotlib的图自动美化,但新版改了,不会自动美化,得自己设置,这方面花了大量时间搜索,主要是不知道对应的术语叫什么,只能按文字描述搜索,***发现,图像的灰底不是颜色,是style,可以用两种方式设置,但两种都不好用,因为只要对一个图设置后,那做其它图时都会默认采用你设置的这个style,而我希望只针对单个图起作用。
项目之外的,我感到主动学习非常重要,对于自己不会的,不要畏惧,也不要偷懒,要相信自己碰到的问题别人也绝对碰到过,搜一搜,看看别人是怎么解决的,比如对于技能的提取及词云的绘制,起初用了结巴分词提取,但提取有疏漏,不过没有大的问题,但绘制词云时,出来的都是中文词,基本没有技能名,我只好去找别的方法,看能不能过滤掉结巴提取后的中文词,***发现何不采用正则重新提取呢,于是进行了重新提取,但绘制词云时又碰到重复显示的问题,同样的词以不同大小和颜色显示好几次,但词并没有问题。***用自定义词典解决了。
另外就是英语非常重要,有些函数的参数太多,以至于官网文档都没有详细说,它可能是作为一些共用的参数放在了其它函数中介绍。***,对于岗位描述的探索还能进一步采用语义分析,得出更明确的要求,因为有些要求是必须满足的,有些是加分项,但水平所限,还不能语义分析,还有就是投资公司,如果数据较全也能探索下金融方面这些机构的投资偏好及相互间的裙带关系,毕竟,中国的互联网,谁都绕不开阿里腾讯及其背后的资本。