暑期是学生放假的时候,也是院线神仙打架的时候,各色电影亮相大荧屏,高潮迭起,好不精彩。
今年的暑期《我不是药神》一骑绝尘,而姜文的《邪不压正》却褒贬不一,虽然上映当天豆瓣评分便由8.2跌到7.1,但单日票房却依旧过亿。
作为掌握技术Pythoner,我们除了关注彭于晏的屁股,还应该关注许晴的臀部,啊不是,应该透过现象去看清本质。
那么咱们来通过爬取豆瓣影评获取数据进行分析。
数据的获取
对于数据的获取,本文采用的是Python爬虫的方式获取的数据。用到的主要是requests包与正则包re。(注意:该程序并未对验证码进行处理。爬取内容少不会遇到验证码,但上万评论可能会跳出验证码)
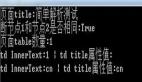
爬取的内容主要是:用户名,是否看过,评论的星星点数,评论时间,认为有用的人数,评论内容。参看下图(用户名已隐藏):

以下是Python爬虫的代码:
- import requests
- import re
- import pandas as pd
- url_first='https://movie.douban.com/subject/26366496/comments?start=0'
- head={'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/59.0.3071.109 Chrome/59.0.3071.109 Safari/537.36'}
- cookies={'cookie':'你自己的cookie'} #也就是找到你的账号对应的cookie
- html=requests.get(url_first,headers=head,cookies=cookies) reg=re.compile(r'<a href="(.*?)&.*?class="next">') #下一页
- ren=re.compile(r'<span>(.*?)</span>.*?comment">(.*?)</a>.*?</span>.*?<span.*?class="">(.*?)</a>.*?<span>(.*?)</span>.*?title="(.*?)"></span>.*?title="(.*?)">.*?class=""> (.*?) ',re.S) #评论等内容
- while html.status_code==200: url_next='https://movie.douban.com/subject/26366496/comments'+re.findall(reg,html.text)[0]
- zhanlang=re.findall(ren,html.text)
- data=pd.DataFrame(zhanlang)
- data.to_csv('/home/wajuejiprince/文档/zhanlang/zhanlangpinglun.csv', header=False,index=False,mode='a+') #写入csv文件,'a+'是追加模式 data=[] zhanlang=[] html=requests.get(url_next,cookies=cookies,headers=head)
△注意设置你自己的User-Agent,Cookie,CSV保存路径等
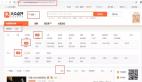
爬取的内容保存成CSV格式的文件,如下所示:

数据的处理
虽然在爬取的时候已经非常注意爬取内容的结构了,但是还是不可避免的有一些值不是我们想要的,比如有的评论内容会出现在评论者这一项中。比如评论重复,所以还是首先有必要进行一下数据的清洗。
接下来就可以进行数据浅析,比如通过星星数判定评论质量:
- plot_ly(my_dt[,.(.N),by=.(五星数)],type = 'bar',x=~五星数,y=~N)

对评论结果的云图展示:
♦首先我们应该先进行评论的分词
- wk <- worker()
- sw<-function(x){wk<=x}
- segwords<-lapply(my_dt[,评论内容],sw)
- my_segwords<-unlist(segwords) #不要列表
- #去除停止词
- st<-readLines(file.choose())
- #读取停止词stopwords<-c(NULL)
- for(i in 1:length(st))
- { stopwords[i]<-st[i]}
- seg_Words<-filter_segment(my_segwords,stopwords) #去除中文停止词
♦总体评论云图展示
- words<-table(seg_Words)%>%data.table()setnames(words,"N","pinshu")
- words[pinshu>1000] #去除较低频数的词汇(小于1000的)wordcloud2(words[pinshu>1000], size = 2, fontFamily = "黑体",color = "random-light", backgroundColor = "grey")
由于数据太多,防止卡顿,所以在制作云图的时候去掉了频数低于1000的词汇。
云图结果如下:

可以看出,排名靠前的热词分别是姜文、不错、好看、彭于晏、剧情、看不懂等,评论确实是五花八门,当然这也是姜文电影的特点吧。
最后送大家一张希腊雕塑般美好的肉体福利