随着AI技术的发展,人类社会正处于火热的智能化革命之中,而谁能在技术革命浪潮中快速的武装自己,谁就能掌握未来的机遇。AI Studio正属于那一类帮助中小企业,开发者实现AI能力的武器库之一。
如今,AI能力已经渗透到各行各业,在语音、图像以及NLP领域,已获得了突破性的进展和效果,这进一步增强了我们对AI技术的信心,将其推广到更多的传统行业来助力各行业的发展。AI技术可以让我们释放更多的脑力和体力,在更需要人类创造力的地方发挥作用,其他的一切交给AI,相信我,它们做的比我们更好。
对于大型互联网企业,形成AI能力只要投钱投人就行了,但是对于中小企业单独构建AI能力将耗费巨大的精力:招兵买马,设备采购,模型开发,系统维护,于是大量的云计算及建模平台如雨后春笋般发展起来,包括AWS(收费),Azure(收费),阿里云(还是收费)等。而百度在确立All in AI后做了很多基础而扎实的工作,包括最新推出的百度AI Studio一站式开发平台:一个囊括了AI教程、代码环境、算法算力、数据集,并提供免费的在线云计算的一体化编程环境,在这里,用户就不必纠结于复杂的环境配置和繁琐的扩展包搜寻,只要有电脑、网络以及一颗走进深度学习的心,打开浏览器输入aistudio.baidu.com,就可以在AI Studio开展深度学习项之旅。下面,本文将从功能简介,实战建模及AI能力应用等角度聊聊AI Studio。
俗话说,授人以鱼不如授人以渔。百度All in AI的战略里,鱼就是诸如基于语音技术、图像技术、视频技术、知识图谱及NLP技术等形成的人工智能产品服务;而渔就是AI Studio一类的能够帮助个人开发者和中小企业去开发属于自己的产品服务,运用AI Studio开发者可以实现自定义的AI建模能力而无需考虑硬件成本、运维成本、人力成本。相比在谷歌云,AWS等云平台上花钱买计算资源和存储空间跑模型来说,AI Studio提供全套免费服务(计算资源免费,空间资源免费,项目托管免费,视频教程也免费)。可以说AI Studio从教学、应用、工程上全面推进了AI民主化的进程,极大的降低了AI技术跨入门槛。
1.功能简介
第一次进入主页,首先的感觉这是个类似Kaggle的数据竞赛平台,但是仔细看来,AI Studio强化了工程项目的概念,一大亮点就是AI学习项目这个版块,里面包括大量真实场景的工程项目(图像识别,情感分析,个性化推荐等);另一个重要组成就是比赛了,众所周知构建良性循环的产、学、研社区是行业发展的重要组成部分,不过目前AI Studio组织的比赛还刚起步,希望后续比赛多多,大家在这里都能学到知识,交到朋友,最重要的是,可以在学习的同时给自己赚点零用钱花花(笑~)。
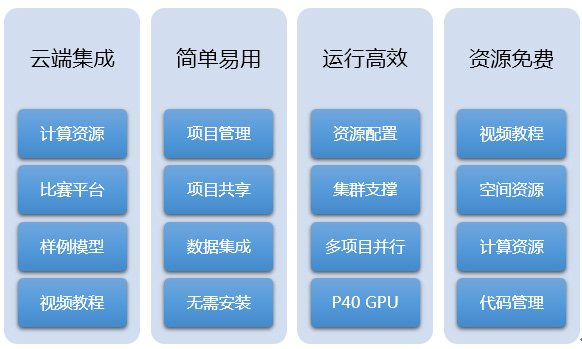
Figure 1 AI Studio特性
AI Studio主要功能有项目类的项目大厅,创建项目,样例项目,共享项目等四大部分,有数据科学比赛,有各种经典数据集和自定义数据集,有详尽的机器学习和深度学习的教程及视频公开课等。下面就简单的来介绍一下:
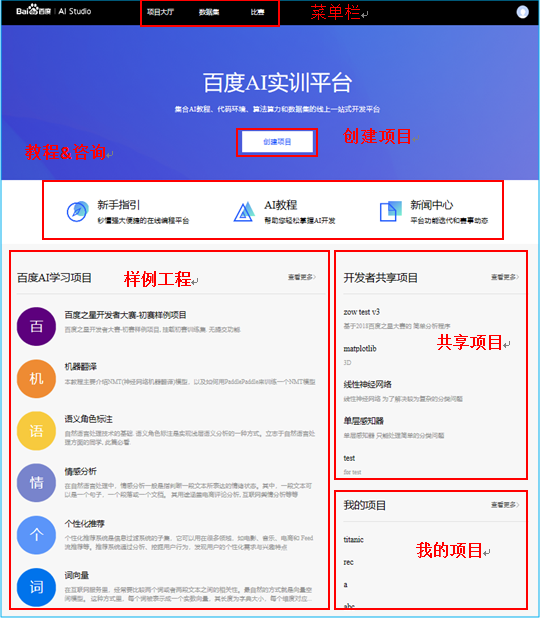
Figure 2 AI Studio主要功能
1.1. 菜单栏
1.1.1. 项目大厅
作为AI Studio的主页,集成百度积累的经典AI学习项目,自我的项目管理及共享项目列表。整个平台都是以项目为核心的,也凸显了AI Studio的定位,就是以技术及资源输出帮助个人开发者,中小企业快速拥有AI能力以更好的服务自身业务。
1.1.2. 数据集
数据集包括一些经典的公开数据集,像MNIST,IMDB,CIFAR10,Penn Treebank,MovieLens等;也包括一些开放的百度数据(中文短文本语料,信息抽取数据)。不过相比Kaggle近万份数据集来说,仍然有很大的发展空间,但是个人感觉AI Studio的数据集还是要比Tianchi的数据集规整很多的。当然,用户也可以上传自定义数据进行模型开发。
1.1.3. 比赛
这个模块应该是所有玩数据的人最感兴趣的了吧。我之前在Kaggle参加过一些项目,总的来说,Kaggle在比赛这块做的真的很好,赛制清晰,社区完善,每次参加比赛都能有很大的提高。相较Kaggle,AI Studio的比赛数量还不多,不过以上提到的功能都有,另外就是AI Studio提供云端训练平台,这样大家的武器库相对平衡,能够更公平的进行竞赛。

Figure 3 AI Studio 比赛页面
1.2. 创建项目
AI Studio以项目为单元进行开发。创建项目,添加数据集,运行开发环境(notebook kernel),就可以开始构建自己的模型进行开发生产了。目前,环境仅支持Python2.7(期待更多的环境,Python3,R等),算法框架包括paddlepaddle和sklearn等。

Figure 4 AI Studio创建项目页面
1.3. 教程&资讯
关于教程,paddlepaddle关于机器学习的教程应该是中文里最好的,不仅有机器学习、深度学习的视频公开课和教程文档(获取),而且包含了大量的各个方向的深度学习实例,比如图像分类,词向量,个性化推荐,情感分析,语义角色标注以及机器翻译等,不仅从原理层面进行深入浅出的讲解,更提供模型代码逐行进行实操,可以说为Everyone can AI提供了强大的后盾。
1.3.1. 样例工程
样例工程即是提供的机器学习经典应用场景及历届比赛的notebook,我们可以把各个项目fork到自己的项目下进行开发学习。对于急于构建AI能力的中小企业,这个模块是最大福音了,很久之前看过Tensorflow的文档,只有几个典型问题的教程及代码,而这里包括了大量的基于不同场景的AI模型可供拿来即用。

1.3.2. 共享项目
顾名思义,AI Studio也提供项目共享功能供大家互相学习。在开源的时代,能够培育成熟活跃的社区是平台发展的必要因素,这也是Tensorflow能够在深度学习领域中快速推广的重要原因。
1.3.3. 我的项目
这里是开发者自己的项目列表,不再赘述。
2.实战建模
AI Studio以项目为核心,创建项目的同时可以自定义上传数据,也可以选取平台已有数据集;目前,环境仅支持Python2.7,算法库包括sklearn和PaddlePaddle。不需要费心在开发环境上,能够安心构造模型,将建模工程云服务化应该是未来趋势(能够方便中小企业快速构建AI能力)。在AI Studio各项目之间是独立分配资源的,可以同时调试多个项目模型,这点还是非常赞的。
我这里创建了两个共享项目,查看代码直接fork项目开箱即用(需百度账号登录:Titanic项目,个性化推荐项目),代码详见附录及共享项目。第一个项目是最最基础的数据科学的入门问题titanic预测是否生还(自主上传数据,调用sklearn随机森林模型);第二,利用已有数据(MovieLens)及PaddlePaddle构建个性化推荐模型。一个小问题就是创建项目后进入项目页面,进入运行状态还需要点击运行项目,这里感觉有点冗余;运行的项目就是一个简洁的notebook开发环境,该有的功能都有,个人感觉速度比Kaggle要好很多(不知是不是我的网速渣)。
Figure 5 AI Studio项目界面
开发环境主体是由notebook形式组成,熟悉jupyter的同学可以无缝衔接,比notebook好的一点就是项目的数据集都会形成列表,简单一键获取数据路径。菜单栏更简洁,基本功能都有,可以保存notebook,有个有意思的地方是在创建项目的时候环境只能选Python2.7,但这里kernel选择会出现Python3。
Figure 6 AI Studio开发页面
3.群雄逐鹿
作为一站式AI建模开发平台AI Studio,如何在强手如云的AI开发平台市场杀出一条血路呢?最重要的途径就是完善比赛社区的理念,通过PaddlePaddle+AI Studio的方式抢占数据科学竞赛这个领域,这里就简要比较一下几家数据竞赛平台(AI Studio、Kaggle、天池、DataCastle等)。以下将从对开发者的能力提升,平台比赛的公平性和比赛收获等三个方面阐述。
3.1. 能力提升
可以说参加数据建模比赛是最好的提升自身能力的方式了,在比赛中,不但能够了解各行各业的业务形式,数据结构,也能真实的验证我们对特征和算法的不同理解,而良好的社区环境和代码共享机制为自身能力的提升提供了温床。在这方面,Kaggle因为成立最早有很强的人才和代码沉淀,投靠Google后,更是愈发的体现了其中的优势。天池和DataCastle在社区建设上也投入了大量的精力,但是与Kaggle还是有较大的差距,不过在中文社区中应该算是佼佼者。AI Studio显然有后来者的劣势,不过看过他们的样例项目,还是很佩服他们在教程和文档方面的思考,可以说在AI中文教程里AI Studio大踏步的跨入了第一梯队。
3.2. 比赛的公平性
这里的公平性体现在两个方面,第一是赛题的数据量要有一定的规模以防止数据量过小导致的模型稳定性问题;第二则是计算资源的公平性,举个栗子,假如阿里组队以P100 GPU集群的算力来参赛的话,恐怕其他人的胜算只能寄托于奇迹了,而对于ImageNet那样量级的数据,我们只有PC机的话恐怕连一次迭代也完成不了,更不要说模型调优了。
在这方面,AI Studio具有极大的优势,平台不仅免费对参赛选手给予计算资源上的支持,更是提供最新版本的PaddlePaddle供选手调用。而天池在初赛阶段是没有集群算力支持的,只有进入复赛的选手才会有机会使用数加平台。Kaggle和DataCastle更是没有平台的支持。相比来说在比赛资源的公平性上AI Studio的优势巨大。
3.3. 比赛收获
这里的收获是只除了能力以外的物质方面的获得,比如现金奖励和简历背书。这两点对于初入职场的新人还是非常重要的。客观来讲,国际影响力的话Kaggle绝对是No.1,致力于进入Google、facebook的同学最好还是在Kaggle上挑选优质的比赛;针对国内的话,AI Studio、天池和DataCastle在奖金方面相差不大,由于AI Studi推出最晚,所以奖金相对来说高一些。
综合来看,AI Studio作为数据科学竞赛中的新人,背靠百度资源,凭借更加公平的平台资源输出,奖励制度和完善的教程文档体系将会在未来大规模的抢占数据竞赛市场。对开发者来说,免费使用GPU资源,更简单的开发流程已经是很大的诱惑了。
4.百度AI战略
身处AI圈,对各家的AI产品战略比较感兴趣,最近有意思的事情就是Baidu Create 2018了,会上,李彦宏的AI梦完成了从All In AI到Everyone Can AI的升华。发布的AI产品从自动驾驶巴士“阿波龙”到百度自主研发的云端AI 芯片“昆仑”,再到两大AI生态平台DuerOS3.0、Apollo3.0,可以说百度在AI的布局已经从稚嫩走向成熟,以多兵种合成集团军的面貌展示在世界人工智能的舞台。
百度的AI战略重在开放,强调技术赋能。
根据百度的说法, 目前已经形成了以行业应用为牵引,AI技术产品服务为动力,AI基础平台服务为核心的生态闭环(AI开放平台)。从百度公开的资料上看, ,百度已经将AI服务应用于智慧零售,金融科技,商业地产,企业服务,智能硬件,教育培训等各行各业。比如说智慧零售, 百度提供基础能力, 合作伙伴进行集成和落地, 将人脸识别,人体分析,图像识别,大数据分析研判等服务赋能给线下门店,商场超市,各大品牌商等零售业态,有效提升了商业效率及利润率。在技术服务上,百度提供全面的AI能力,包括语音技术图像技术,人脸识别,视频技术,等等等等, 据说已经超过110项能力 在平台服务上,百度不仅有Apollo自动驾驶开放平台和DuerOS对话式开放平台,也包括像AI Studio囊括AI教程、开发环境、算法算力的一站式AI开发平台,EasyDL图像自定义模型构建平台以及基础的深度学习框架PaddlePaddle。
可见,百度在这场智能化革命中=不但酝酿已久,而且已经结出了不少果实。
5.总结
AI Studio是一个基于PaddlePaddle的集成了大量数据集、经典样例项目及比赛项目的云计算建模平台,也是一个机器学习、深度学习的交流社区。AI Studio最大限度的解放了数据科学家需要环境配置的烦恼,在云端集成计算资源,项目管理,代码管理,比赛等多种功能,形成一站式兼顾学习和工作的建模平台。而且AI Studio提供计算资源,空间资源,视频公开课都是免费的!免费的!免费的!(所谓重要的事情说三遍)。最后,期待一下的更多比赛的推出。
参考文献
- http://aistudio.baidu.com
- http://ai.baidu.com/
- http://www.paddlepaddle.org/
- http://ai.baidu.com/paddlepaddle
附录
- # 查看当前挂载的数据集目录
- !ls /home/aistudio/data/
- # 查看个人持久化工作区文件
- !ls /home/aistudio/work/
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- # titanic problem
- # 数据集是经典的机器学习问题,titanic的原始数据,以下是在AI Studio平台上Python2.7环境,完整的从数据清洗,数据处理,特征工程,到运用
- # 随机森林构建模型
- # 最简单的模型开发流程如下
- # - 数据读入
- # - 特征工程
- # - 数据分割
- # - 模型训练
- # - 模型评估
- # - 交叉检验
- ## 数据读入
- # 创建项目的时候读入数据,通过ls /home/aistudio/data/查看数据集目录,添加数据。
- data_train = pd.read_csv('/home/aistudio/data/data188/train.csv')
- data_test = pd.read_csv('/home/aistudio/data/data188/test.csv')
- data_train.sample(3)
- ## 特征工程
- ### 数据清洗及特征处理
- # 对特征进行如下处理:
- # - 对特征Age进行分箱离散化处理(simplify_ages)
- # - 提取特征Cabin进行类别化处理(simplify_cabins)
- # - 对特征Fare进行分箱离散化处理(simplify_fares)
- # - 对特征名字进行处理(format_name)
- # - 删掉意义不大的特征(drop_features)
- def simplify_ages(df):
- df.Age = df.Age.fillna(-0.5)
- bins = (-1, 0, 5, 12, 18, 25, 35, 60, 120)
- group_names = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Senior']
- categories = pd.cut(df.Age, bins, labels=group_names)
- df.Age = categories
- return df
- def simplify_cabins(df):
- df.Cabin = df.Cabin.fillna('N')
- df.Cabin = df.Cabin.apply(lambda x: x[0])
- return df
- def simplify_fares(df):
- df.Fare = df.Fare.fillna(-0.5)
- bins = (-1, 0, 8, 15, 31, 1000)
- group_names = ['Unknown', '1_quartile', '2_quartile', '3_quartile', '4_quartile']
- categories = pd.cut(df.Fare, bins, labels=group_names)
- df.Fare = categories
- return df
- def format_name(df):
- df['Lname'] = df.Name.apply(lambda x: x.split(' ')[0])
- df['NamePrefix'] = df.Name.apply(lambda x: x.split(' ')[1])
- return df
- def drop_features(df):
- return df.drop(['Ticket', 'Name', 'Embarked'], axis=1)
- def transform_features(df):
- df = simplify_ages(df)
- df = simplify_cabins(df)
- df = simplify_fares(df)
- df = format_name(df)
- df = drop_features(df)
- return df
- data_train = transform_features(data_train)
- data_test = transform_features(data_test)
- data_train.head()
- ### 特征处理
- # - 筛选可用的特征
- # - 对类别特征做数值化处理
- from sklearn import preprocessing
- def encode_features(df_train, df_test):
- features = ['Fare', 'Cabin', 'Age', 'Sex', 'Lname', 'NamePrefix']
- df_combined = pd.concat([df_train[features], df_test[features]])
- for feature in features:
- le = preprocessing.LabelEncoder()
- le = le.fit(df_combined[feature])
- df_train[feature] = le.transform(df_train[feature])
- df_test[feature] = le.transform(df_test[feature])
- return df_train, df_test
- data_train, data_test = encode_features(data_train, data_test)
- data_train.head()
- ## 数据分割
- # 对数据集进行训练集和测试集的分割
- from sklearn.model_selection import train_test_split
- X_all = data_train.drop(['Survived', 'PassengerId'], axis=1)
- y_all = data_train['Survived']
- num_test = 0.20
- X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size=num_test, random_state=23)
- ## 模型训练
- # 选取随机森林模型,利用网格搜索进行参数调优。
- from sklearn.ensemble import RandomForestClassifier
- from sklearn.metrics import make_scorer, accuracy_score
- from sklearn.model_selection import GridSearchCV
- # Choose the type of classifier.
- clf = RandomForestClassifier()
- # Choose some parameter combinations to try
- parameters = {'n_estimators': [4, 6, 9],
- 'max_features': ['log2', 'sqrt','auto'],
- 'criterion': ['entropy', 'gini'],
- 'max_depth': [2, 3, 5, 10],
- 'min_samples_split': [2, 3, 5],
- 'min_samples_leaf': [1,5,8]
- }
- # Type of scoring used to compare parameter combinations
- acc_scorer = make_scorer(accuracy_score)
- # Run the grid search
- grid_obj = GridSearchCV(clf, parameters, scoring=acc_scorer)
- grid_obj = grid_obj.fit(X_train, y_train)
- # Set the clf to the best combination of parameters
- clf = grid_obj.best_estimator_
- # Fit the best algorithm to the data.
- clf.fit(X_train, y_train)
- ## 模型评估
- # 用准确率评估模型效果
- predictions = clf.predict(X_test)
- print(accuracy_score(y_test, predictions))
- ## 交叉检验
- # KFold
- from sklearn.cross_validation import KFold
- def run_kfold(clf):
- kf = KFold(891, n_folds=10)
- outcomes = []
- fold = 0
- for train_index, test_index in kf:
- fold += 1
- X_train, X_test = X_all.values[train_index], X_all.values[test_index]
- y_train, y_test = y_all.values[train_index], y_all.values[test_index]
- clf.fit(X_train, y_train)
- predictions = clf.predict(X_test)
- accuracy = accuracy_score(y_test, predictions)
- outcomes.append(accuracy)
- print("Fold {0} accuracy: {1}".format(fold, accuracy))
- mean_outcome = np.mean(outcomes)
- print("Mean Accuracy: {0}".format(mean_outcome))
- run_kfold(clf)
- ids = data_test['PassengerId']
- predictions = clf.predict(data_test.drop('PassengerId', axis=1))
- output = pd.DataFrame({ 'PassengerId' : ids, 'Survived': predictions })
- # output.to_csv('titanic-predictions.csv', index = False)
- output