












特征工程技能是为机器学习优化的数据特征,它与数据科学本身一样历史悠久。但我注意到,这一技能正变得越来越被忽视。对机器学习的高需求产生了大量的数据科学家,他们在工具和算法方面拥有专业知识,但缺乏特性工程所需的经验和特定行业的领域知识。他们试图用更好的工具和算法来弥补这一点。然而,算法现在是一种商品,不产生企业知识产权。
像Amazon ML和谷歌AutoML这样的通用数据正在变得商品化,基于云计算的机器学习服务(MLaaS),如Amazon ML和Google AutoML,现在可以让毫无经验的团队在几分钟内运行数据模型并获得预测。因此,主导权正在转向那些在收集或制造专有数据方面发展组织能力的公司,通过特征工程实现。简单的数据采集和模型构建已不再适用。
企业团队可以从建模竞赛的获奖者那里学到很多东西,例如KDD杯和遗产提供者网络健康奖,他们认为特色工程是他们成功的关键因素。
一、特征工程技术
为了支持特征工程,数据科学家开发了一系列技术。它们可以被广泛地视为:
1、语境转换
一组方法涉及将各个特征从原始集转换为针对每个特定模型的更多上下文有意义的信息。
例如,在处理分类特征时,“未知”可能会在特定情况的上下文中传达特殊信息。但是,在模型中,它看起来只是另一个类别值。在这种情况下,团队可能希望引入“has_value”的新二进制功能,以将“未知”与所有其他选项分开。例如,“颜色”功能允许输入“has_color”用于未知颜色的内容。
另一种方法是使用单热编码将分类特征转换为一组变量。在上面的示例中,将“颜色”类别转换为三个特征(“红色”,“绿色”和“蓝色”各一个)可以根据模型的目标实现更好的学习过程。
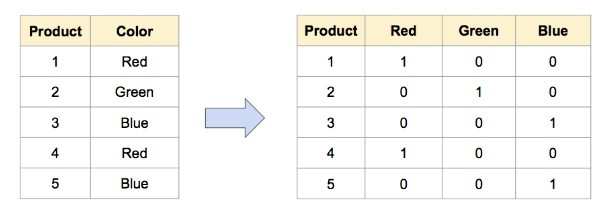
机器学习团队还经常使用分级作为将单个特征转换为多个特征的方法,以获得更好的洞察力。例如,将'age'特征分为'young'为<40,'middle_age'为40-60,'old'为> 60。
其他一些转换的例子是:
将变量的最小值 - 最大值(例如年龄)之间的值缩放到[0,1]的范围内
将每种类型的餐厅的访问次数除以美食的“兴趣”指标
2、多特征算术
特征工程的另一种方法是将算术公式应用于一组现有数据点。公式可以基于特征,比率和其他关系之间的相互作用来创建衍生物。
这种类型的特征工程可以提供高价值,但需要对模型的主题和目标有充分的了解。
示例包括使用公式:
从“学校评级”和“犯罪率”的组合计算“邻里质量”
通过比较访客的“实际支出”和“预期支出”来确定“赌场运气因素”
通过将信用卡“余额”除以“限制”来产生“利用率”
从特定时间范围内的“最近交易”,“交易频率”和“花费的金额”的组合中获取RFM分数(新近度,频率,货币)以对客户进行分段。
3、先进的技术
团队还可以选择更高级的算法方法来分析现有数据,以寻找创建新功能的机会。
主成分分析(PCA)和独立成分分析(ICA)将现有数据映射到另一个特征空间
深度特征合成(DFS)允许从神经网络中的中间层转移中间学习
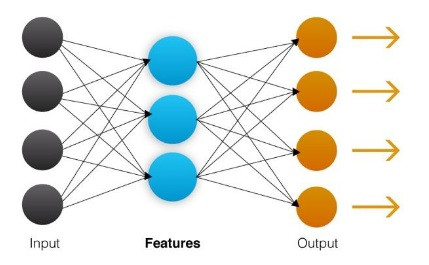
二、设置成功的框架
团队必须不断寻找更有效的功能和模型。但是,为了取得成功,这项工作必须在有条不紊和可重复的框架内完成。以下是任何功能工程工作的六个关键步骤:
1.明确模型用法。首先澄清模型的主要目标和用例。整个团队必须保持同步并以单一目的工作。否则,你会减少努力并浪费资源。
2.设置标准。构建高性能模型的过程需要仔细探索和分析可用数据。但是工作计划也需要适应现实世界的障碍。在特征化过程中考虑诸如成本,可访问性,计算限制,存储约束和其他要求等因素。团队必须尽早调整这些偏好或限制。
3.构思新功能。广泛思考如何创建新数据以更好地描述和解决问题。此时,领域知识和主题专家的参与将确保您的特征工程的结果增加价值。
4.构造要素作为输入。一旦确定了新的特征概念,请从可用数据中选择最有效的技术来构建它们。选择正确的技术是确保新功能有用性的关键。
5.研究影响。评估新功能对模型性能的影响。关于新特征增加值的结论直接取决于如何测量模型的功效。
模型性能度量必须与业务度量相关才能有意义。如今,团队拥有大量的测量选项,远远超出准确性,例如精度,召回率,F1分数和接收器操作特性(ROC)曲线。
6.优化功能。特征工程是一个涉及测试,调整和改进新特征的迭代过程。此过程中的优化循环有时会导致删除低性能特征或使用紧密变体替换,直到识别出最高影响特征。
总结
特征工程是我们现代世界的新炼金术,成功的团队将通用数据转化为其组织的增值知识产权。
几项重要原则有助于推动这项工作取得成功:
- 包括主题专业知识,以确保计划从明确了解业务目标和模型有效性的相关措施开始
- 通过迭代和系统的过程
- 考虑可用的许多可能的特征选项
- 了解并监控功能选择如何影响模型性能
- 将数据转换为驱动有意义模型的专有功能的这种能力可以创造重要价值并确保组织的竞争优势。



















