知乎在 2016 年已经完成了全量业务的容器化,并在自研容器平台上以原生镜像的方式部署和运行。
后续我们陆续实施了 CI、Cron、Kafka、HAProxy、HBase、Twemproxy 等系列核心服务和基础组件的容器化。
知乎既是容器技术的重度依赖者,也是容器技术的深度实践者,本篇文章分享知乎在镜像仓库这个容器技术核心组件的生产实践。
基础背景
容器的核心理念在于通过镜像将运行环境打包,实现“一次构建,处处运行”,从而避免了运行环境不一致导致的各种异常。
在容器镜像的发布流程中,镜像仓库扮演了镜像的存储和分发角色,并且通过 tag 支持镜像的版本管理,类似于 Git 仓库在代码开发过程中所扮演的角色,是整个容器环境中不可缺少的组成部分。
镜像仓库实现方式按使用范围可以分为两类:
- Docker Hub,在公网环境下面向所有容器使用者开放的镜像服务
- Docker Registry,供开发者或公司在内部环境下搭建镜像仓库服务。
基于公网下载镜像的网络带宽、延迟限制以及可控性的角度考虑,在私有云环境下通常需要采用 Docker Registry 来搭建自己的镜像仓库服务。
Docker Registry 本身开源,当前接口版本为 V2 (以下描述均针对该版本),支持多种存储后端,如:
- InMemory:A temporary storage driver using a local in memory map. This exists solely for reference and testing。
- FileSystem:A local storage driver configured to use a directory tree in the local file system。
- S3:A driver storing objects in an Amazon Simple Storage Service (S3) bucket。
- Azure:A driver storing objects in Microsoft Azure Blob Storage。
- Swift:A driver storing objects in Openstack Swift。
- OSS:A driver storing objects in Aliyun OSS。
- GCS:A driver storing objects in a Google Cloud Storage bucket。
默认使用本地磁盘作为 Docker Registry 的存储,用下面的配置即可本地启动一个镜像仓库服务:
- $ docker run -d \
- -p 5000:5000 \
- --restart=always \
- --name registry \
- -v /mnt/registry:/var/lib/registry \
- registry:2
生产环境挑战
很显然,以上面的方式启动的镜像仓库是无法在生产环境中使用的,问题如下:
- 性能问题:基于磁盘文件系统的 Docker Registry 进程读取延迟大,无法满足高并发高吞吐镜像请求需要。
且受限于单机磁盘,CPU,网络资源限制,无法满足上百台机器同时拉取镜像的负载压力。
- 容量问题:单机磁盘容量有限,存储容量存在瓶颈。知乎生产环境中现有的不同版本镜像大概有上万个,单备份的容量在 15T 左右,加上备份这个容量还要增加不少。
- 权限控制:在生产环境中,需要对镜像仓库配置相应的权限认证。缺少权限认证的镜像仓库就如同没有认证的 Git 仓库一样,很容易造成信息泄露或者代码污染。
知乎的生产环境中,有几百个业务以及几万个容器运行在容器平台上,繁忙时每日创建容器数近十万,每个镜像的平均大小在 1G 左右。
部署高峰期对镜像仓库的压力是非常大的,上述性能和容量问题也表现的尤为明显。

知乎解决方案
为了解决上述的性能和容量等问题,需要将 Docker Registry 构造为一个分布式服务,实现服务能力和存储容量的水平扩展。
这其中最重要的一点是为 Docker Registry 选择一个共享的分布式存储后端,例如 S3,Azure,OSS,GCS 等云存储。
这样 Docker Registry 本身就可以成为无状态服务从而水平扩展。
实现架构如下:
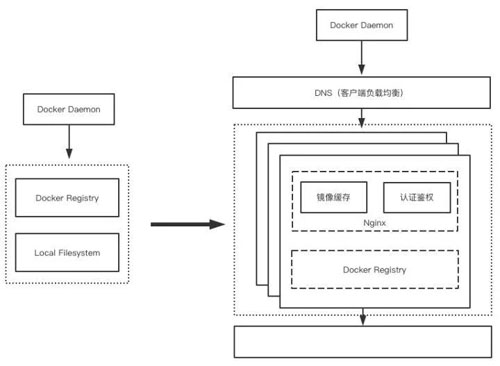
该方案主要有以下几个特点:
客户端流量负载均衡
为了实现对多个 Docker Registry 的流量负载均衡,需要引入 Load Balance 模块。
常见的 Load Balance 组件,如 LVS,HAProxy,Nginx 等代理方案都存在单机性能瓶颈,无法满足上百台机器同时拉取镜像的带宽压力。
因此我们采用客户端负载均衡方案,DNS 负载均衡:在 Docker daemon 解析 Registry 域名时,通过 DNS 解析到某个 Docker Registry 实例 IP 上,这样不同机器从不同的 Docker Registry 拉取镜像,实现负载均衡。
而且由于 Docker daemon 每次拉取镜像时只需解析一次 Registry 域名,对于 DNS 负载压力本身也很小。
从上图可以看出,我们每一个 Docker Registry 实例对应一个 Nginx,部署在同一台主机上。
对 Registry 的访问必须通过 Nginx,Nginx 这里并没有起到负载均衡的作用,其具体的作用将在下文描述。
这种基于 DNS 的客户端负载均衡存在的主要问题是无法自动摘掉挂掉的后端。
当某台 Nginx 挂掉时,镜像仓库的可用性就会受到比较严重的影响。因此需要有一个第三方的健康检查服务来对 Docker Registry 的节点进行检查,健康检查失败时,将对应的 A 记录摘掉,健康检查恢复,再将 A 记录加回来。
Nginx 权限控制
由于是完全的私有云,加上维护成本的考虑,我们的 Docker Registry 之前并没有做任何权限相关的配置。
后来随着公司的发展,安全问题也变的越来越重要,Docker Registry 的权限控制也提上了日程。
对于 Docker Registry 的权限管理,官方主要提供了两种方式,一种是简单的 basic auth,一种是比较复杂的 token auth。
我们对 Docker Registry 权限控制的主要需求是提供基本的认证和鉴权,并且对现有系统的改动尽量最小。
basic auth 的方式只提供了基本的认证功能,不包含鉴权。而 token auth 的方式又过于复杂,需要维护单独的 token 服务。
除非你需要相当全面精细的 ACL 控制并且想跟现有的认证鉴权系统相整合,否则官方并不推荐使用 token auth 的方式。这两种方式对我们而言都不是很适合。
我们***采用了 basic auth + Nginx 的权限控制方式。basic auth 用来提供基本的认证,OpenRestry + lua 只需要少量的代码,就可以灵活配置不同 URL 的路由鉴权策略。
我们目前实现的鉴权策略主要有以下几种:
基于仓库目录的权限管理:针对不同的仓库目录,提供不同的权限控制。
例如 /v2/path1 作为公有仓库目录,可以直接进行访问,而 /v2/path2 作为私有仓库目录,必须经过认证才能访问。
基于机器的权限管理:只允许某些特定的机器有 pull/push 镜像的权限。
Nginx 镜像缓存
Docker Registry 本身基于文件系统,响应延迟大,并发能力差。为了减少延迟提升并发,同时减轻对后端存储的负载压力,需要给 Docker Registry 增加缓存。
Docker Registry 目前只支持将镜像层级 meta 信息缓存到内存或者 Redis 中,但是对于镜像数据本身无法缓存。
我们同样利用 Nginx 来实现 URL 接口数据的 cache。为了避免 cache 过大,可以配置缓存失效时间,只缓存最近读取的镜像数据。
主要的配置如下所示:
- proxy_cache_path /dev/shm/registry-cache levels=1:2 keys_zone=registry-cache:10m max_size=124G;
加了缓存之后,Docker Registry 性能跟之前相比有了明显的提升。
经过测试,100 台机器并行拉取一个 1.2G 的 image layer,不加缓存平均需要 1m50s,花费最长时间为 2m30s。
添加缓存配置之后,平均的下载时间为 40s 左右,花费最长时间为 58s,可见对镜像并发下载性能的提升还是相当明显的。
HDFS 存储后端
Docker Registry 的后端分布式存储,我们选择使用 HDFS,因为在私有云场景下访问诸如 S3 等公有云存储网络带宽和时延都无法接受。
HDFS 本身也是一个稳定的分布式存储系统,广泛应用在大数据存储领域,其可靠性满足生产环境的要求。
但 Registry 的官方版本里并没有提供 HDFS 的 Storage Driver,所以我们根据官方的接口要求及示例,实现了 Docker Registry 的 HDFS Storage Driver。
出于性能考虑,我们选用了一个 Golang 实现的原生 HDFS Client (colinmarc/hdfs)。
Storage Driver 的实现比较简单,只需要实现 Storage Driver 以及 FileWriter 这两个 interface 就可以了。
具体的接口如下:
- type StorageDriver interface {
- // Name returns the human-readable "name" of the driver。
- Name() string
- // GetContent retrieves the content stored at "path" as a []byte.
- GetContent(ctx context.Context, path string) ([]byte, error)
- // PutContent stores the []byte content at a location designated by "path".
- PutContent(ctx context.Context, path string, content []byte) error
- // Reader retrieves an io.ReadCloser for the content stored at "path"
- // with a given byte offset.
- Reader(ctx context.Context, path string, offset int64) (io.ReadCloser, error)
- // Writer returns a FileWriter which will store the content written to it
- // at the location designated by "path" after the call to Commit.
- Writer(ctx context.Context, path string, append bool) (FileWriter, error)
- // Stat retrieves the FileInfo for the given path, including the current
- // size in bytes and the creation time.
- Stat(ctx context.Context, path string) (FileInfo, error)
- // List returns a list of the objects that are direct descendants of the
- //given path.
- List(ctx context.Context, path string) ([]string, error)
- // Move moves an object stored at sourcePath to destPath, removing the
- // original object.
- Move(ctx context.Context, sourcePath string, destPath string) error
- // Delete recursively deletes all objects stored at "path" and its subpaths.
- Delete(ctx context.Context, path string) error
- URLFor(ctx context.Context, path string, options map[string]interface{}) (string, error)
- }
- type FileWriter interface {
- io.WriteCloser
- // Size returns the number of bytes written to this FileWriter.
- Size() int64
- // Cancel removes any written content from this FileWriter.
- Cancel() error
- // Commit flushes all content written to this FileWriter and makes it
- // available for future calls to StorageDriver.GetContent and
- // StorageDriver.Reader.
- Commit() error
- }
其中需要注意的是 Storage Driver 的 Writer 方法里的 append 参数,这就要求存储后端及其客户端必须提供相应的 append 方法。
colinmarc/hdfs 这个 HDFS 客户端中没有实现 append 方法,我们补充实现了这个方法。
镜像清理
持续集成系统中,每次生产环境代码发布都对应有容器镜像的构建和发布,会导致镜像仓库存储空间的持续上涨,需要及时清理不用的镜像释放存储空间。
但 Docker Registry 本身并没有配置镜像 TTL 的机制,需要自己开发定时清理脚本。
Docker Registry 删除镜像有两种方式,一种是删除镜像:
- DELETE /v2/<name>/manifests/<reference>
另一种是直接删除镜像层 blob 数据:
- DELETE /v2/<name>/blobs/<digest>
由于容器镜像层级间存在依赖引用关系,所以推荐使用***种方式清理过期镜像的引用,然后由 Docker Registry 自身判断镜像层数据没有被引用后再执行物理删除。
未来展望
通过适当的开发和改造,我们实现了一套分布式的镜像仓库服务,可以通过水平扩容来解决单机性能瓶颈和存储容量问题,很好的满足了我们现有生产环境需求。
但是在生产环境大规模分发镜像时,服务端(存储、带宽等)依然有较大的负载压力。
因此在大规模镜像分发场景下,采用 P2P 的模式分发传输镜像更加合适,例如阿里开源的 Dragonfly 和腾讯开发的 FID 项目。
知乎当前几乎所有的业务都运行在容器上,随着业务的快速增长,该分布式镜像仓库方案也会越来越接近性能瓶颈。
因此我们在后续也会尝试引入 P2P 的镜像分发方案,以满足知乎快速增长的业务需求。