万众期待的《邪不压正》已上映有一周时间。
但上映当日早上开画8.2,上映不到一天闪崩到7.1的评分好像已经给这部片子本该大展拳脚的片子,戴上了一个结结实实的囚具。

首日票房虽然过亿,却依旧不敌多日日票房冠军《我不是药神》;难道姜文又搞砸了?不管如何,姜文的电影总能掀起影评人高涨的评论热情;
今天就跟着我们看看网友对这部姜文电影的感受到底怎么样。
接下来,我们将会跟你一起用猫眼上万条评论数据来分析,网友对这部电影的反响究竟如何?整体思路,将会从数据获取、数据处理、数据可视化三部曲来进行:
一、数据获取
关于如何获取网页的数据,我们一直也是推荐三步走:下载数据、解析数据、保存数据。在下载数据之前,我们看看猫眼官网的网页结构,看看网友的评论数据接口究竟在哪?
然而,打开猫眼网页只有寥寥几个评论,那它的数据会不会是通过json格式保存到服务器中呢?无奈只能通过抓包猫眼APP来找其数据接口
猫眼网页:http://maoyan.com/films/248566

最后,发现其数据接口为:
http://m.maoyan.com/mmdb/comments/movie/248566.json?_v_=yes&offset=1
其中258566属于电影的专属id,offset代表页数。
最后检验,这个接口只给展示1000页数据,如下:

接口找到后,开始写爬取数据代码,详情代码如下:
- import requests
- import json
- import time
- import random
- #下载第一页数据
- def get_one_page(url):
- headers = {
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
- }
- response = requests.get(url,headersheaders=headers)
- if response.status_code == 200:
- return response.text
- return None
- #解析第一页数据
- def parse_one_page(html):
- data = json.loads(html)['cmts']
- for item in data:
- yield{
- 'comment':item['content'],
- 'date':item['time'].split(' ')[0],
- 'rate':item['score'],
- 'city':item['cityName'],
- 'nickname':item['nickName']
- }
- #保存数据到文本文档
- def save_to_txt():
- for i in range(1,1001):
- url = 'http://m.maoyan.com/mmdb/comments/movie/248566.json?_v_=yes&offset=' + str(i)
- html = get_one_page(url)
- print('正在保存第%d页。'% i)
- for item in parse_one_page(html):
- with open('xie_zheng.txt','a',encoding='utf-8') as f:
- f.write(item['date'] + ',' + item['nickname'] + ',' + item['city'] + ',' +str(item['rate'])+','+item['comment']+'\n')
- time.sleep(5 + float(random.randint(1, 100)) / 20)
- if __name__ == '__main__':
- save_to_txt()
二、数据处理
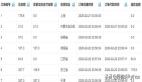
获取数据后发现,会有一些数据重复,如下图:
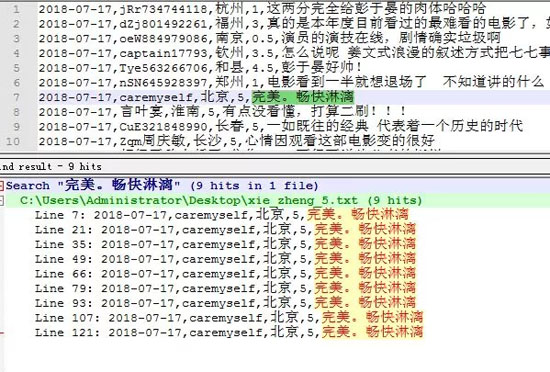
因此需要脚本批量对数据进行去重处理,详情代码如下:
- def xie_zheng(infile,outfile):
- infopen = open(infile,'r',encoding='utf-8')
- outopen = open(outfile,'w',encoding='utf-8')
- lines = infopen.readlines()
- list_l = []
- for line in lines:
- if line not in list_l:
- list_l.append(line)
- outopen.write(line)
- infopen.close()
- outopen.close()
- if __name__ == '__main__':
- xie_zheng('文本原路径','目标路径')
每天可以不定时(每隔四五小时获取一次数据,基本每次可获取900多条数据),最终我们获取到7/15-7/18之间上万条来作为数据集分析。
三、数据可视化
今天我们就用pyecharts将清理过后的万条评论数据来实现可视化。pyecharts 是一个用于生成 Echarts 图表的类库。Echarts 是百度开源的一个数据可视化 JS 库。用 Echarts 生成的图可视化效果非常棒,pyecharts 是为了与 Python 进行对接,方便在 Python 中直接使用数据生成图。
详情请看:http://pyecharts.org/
1. 粉丝北上广及沿海一带居多
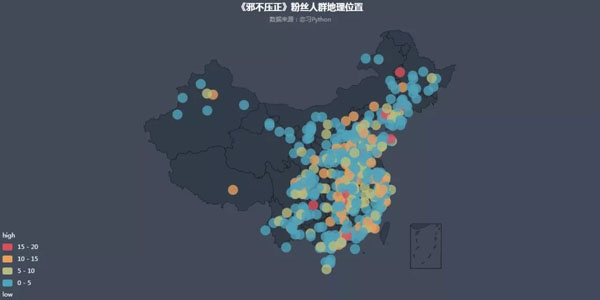
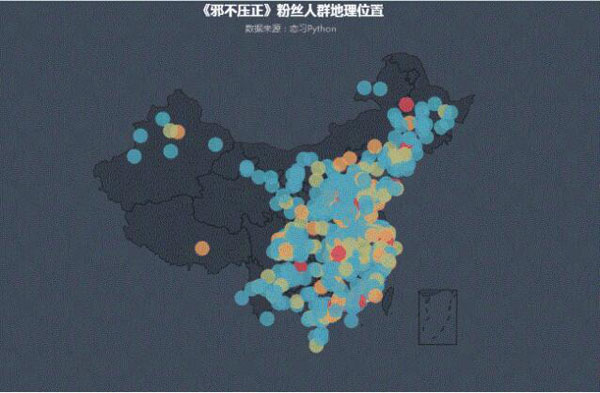
由上图,可以看出北上广一带的用户相对较多,这些地方的互联网用户基数本来就大,同时沿海一代的三四线城市也成为票房贡献者的一部分
详情代码如下:
- from pyecharts import Style
- from pyecharts import Geo
- #读取城市数据
- city = []
- with open('xie_zheng.txt',mode='r',encoding='utf-8') as f:
- rows = f.readlines()
- for row in rows:
- if len(row.split(',')) == 5:
- city.append(row.split(',')[2].replace('\n',''))
- def all_list(arr):
- result = {}
- for i in set(arr):
- result[i] = arr.count(i)
- return result
- data = []
- for item in all_list(city):
- data.append((item,all_list(city)[item]))
- style = Style(
- title_color = "#fff",
- title_pos = "center",
- width = 1200,
- height = 600,
- background_color = "#404a59"
- )
- geo = Geo("《邪不压正》粉丝人群地理位置","数据来源:恋习Python",**style.init_style)
- attr,value= geo.cast(data)
- geo.add("",attr,value,visual_range=[0,20],
- visual_text_color="#fff",symbol_size=20,
- is_visualmap=True,is_piecewise=True,
- visual_split_number=4)
- geo.render()
2. 评论两极分化相对严重
获取到近几日的网友上万条评论数据后,我们切换到今天主题,看看网友对这部电影究竟评论如何?
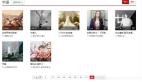
我们将数据集中的评论内容提取出来,将评论分词后制作如下词云图:

可以看出,排名靠前的热词分别是姜文、不错、好看、彭于晏、剧情、看不懂等,可以看出大家对电影的评价还不错,同时估计还有一大部分粉丝是专门看国民老公彭于晏的裸奔与八块腹肌的(哈哈哈)
至于剧情方面,相对于《让子弹飞》,《邪不压正》用了更“姜文”更癫狂的方式来讲了一个相对简单的故事。
从砰砰砰几枪打出片名的那一刻起,影片就在一个极度亢奋的节奏之下不停向前推进着,伴随着应接不暇的戏谑台词,姜文无时无刻不在释放自己的任性,太疯了,甚至有些极端。对于普通观众来说,太难消化了,上一秒还没琢磨明白,下一秒又迎来了一个亢奋且莫名的环境和台词中(也验证评论中一部分网友对剧情看不懂的评价)。
详情代码如下:
- import pickle
- from os import path
- import jieba
- import matplotlib.pyplot as plt
- from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
- comment = []
- with open('quan.txt',mode='r',encoding='utf-8') as f:
- rows = f.readlines()
- for row in rows:
- if len(row.split(',')) == 5:
- comment.append(row.split(',')[4].replace('\n',''))
- comment_after_split = jieba.cut(str(comment),cut_all=False)
- wl_space_split= " ".join(comment_after_split)
- #导入背景图
- backgroud_Image = plt.imread('C:\\Users\\Administrator\\Desktop\\1.jpg')
- stopwords = STOPWORDS.copy()
- #可以加多个屏蔽词
- stopwords.add("电影")
- stopwords.add("一部")
- stopwords.add("一个")
- stopwords.add("没有")
- stopwords.add("什么")
- stopwords.add("有点")
- stopwords.add("这部")
- stopwords.add("这个")
- stopwords.add("不是")
- stopwords.add("真的")
- stopwords.add("感觉")
- stopwords.add("觉得")
- stopwords.add("还是")
- #设置词云参数
- #参数分别是指定字体、背景颜色、最大的词的大小、使用给定图作为背景形状
- wc = WordCloud(width=1024,height=768,background_color='white',
- mask=backgroud_Image,font_path="C:\simhei.ttf",
- stopwordsstopwords=stopwords,max_font_size=400,
- random_state=50)
- wc.generate_from_text(wl_space_split)
- img_colors= ImageColorGenerator(backgroud_Image)
- wc.recolor(color_func=img_colors)
- plt.imshow(wc)
- plt.axis('off')#不显示坐标轴
- plt.show()
- #保存结果到本地
- wc.to_file('保存路径')
(1) 星影评占比高达20%
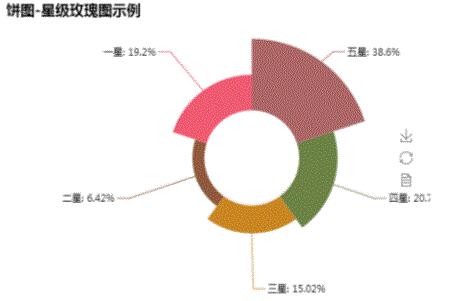
图中可以看出,五星级比例接近40%,而一星级比例与四星级比例几乎差不多,几乎为都为20%。(备注:一星级数量等于1与0.5的总和,以此类推)
很明显,姜文再次掀起了影评人和观众的论战,尽管姜文对影评人并不友好,但影评人还是愿意去袒护姜文。其实,姜文的电影关键在于你期待什么?类型片?姜文拍的从来都不是类型片。艺术片?姜文的电影里的艺术不是一遍就可以看懂的。他的电影就是带着一种“后摇风格”,浓烈、生猛。
姜文和观众都很自我,姜文端着,不肯向市场低头;观众正是因为没端着,所以看姜文的电影过于疲惫。谁都没错,谁都不用救。
详情代码如下:
- from pyecharts import ThemeRiver
- rate = []
- with open('quan.txt',mode='r',encoding='utf-8') as f:
- rows = f.readlines()
- for row in rows:
- if len(row.split(',')) == 5:
- rate.append(row.split(',')[3].replace('\n',''))
- print(rate.count('5')+rate.count('4.5'))
- print(rate.count('4')+rate.count('3.5'))
- print(rate.count('3')+rate.count('2.5'))
- print(rate.count('2')+rate.count('1.5'))
- print(rate.count('1')+rate.count('0.5'))
- #饼状图
- from pyecharts import Pie
- attr = ["五星", "四星", "三星", "二星", "一星"]
- #分别代表各星级评论数
- v1 = [3324,1788,1293,553,1653]
- pie = Pie("饼图-星级玫瑰图示例", title_pos='center', width=900)
- pie.add("7-17", attr, v1, center=[75, 50], is_random=True,
- radius=[30, 75], rosetype='area',
- is_legend_show=False, is_label_show=True)
- pie.render()
关于《邪不压正》网友评论数据就分析到此结束!
你觉得《邪不压正》不好看是对的,因为它太姜文了。你若觉得《邪不压正》好看也是对的,因为它真的太姜文了。成也姜文,败也姜文!但这也许就是他孤傲的世界吧。