随着订单量的日益增长,单个数据库的读写能力开始捉襟见肘。这种情况下,对数据库进行分片变得顺理成章。
分片之后的写,只要根据分片的维度进行取模即可。可是多维度的查询应该如何处理呢?
一片一片的查询,然后在内存里面聚合是一种方式,可是缺点显而易见。
对于那些无数据返回分片的查询,不仅对应用服务器是一种额外的性能消耗,对宝贵的数据库资源也是一种不必要的负担。
至于查询性能,虽然可以通过开线程并发查询进行改善,但是多线程编程以及对数据库返回结果的聚合,增加了编程的复杂性和易错性。可以试想一下分片后的分页查询如何实现,便可有所体会。
所以我们选择对分片后的数据库建立实时索引,把查询收口到一个独立的 Web Service,在保证性能的前提下,提升业务应用查询时的便捷性。那问题就来了,如何建立高效的分片索引呢?
索引技术的选型
实时索引的数据会包含常见查询中所用到的列,例如用户 ID,用户电话,用户地址等,实时复制分发一份到一个独立的存储介质上。
查询时,会先查索引,如果索引中已经包含所需要的列,直接返回数据即可。
如果需要额外的数据,可以根据分片维度进行二次查询。因为已经能确定具体的分片,所以查询也会高效。
为什么没有使用数据库索引
数据库索引是一张表的所选列的数据备份。
由于得益于包含了低级别的磁盘块地址或者直接链接到原始数据的行,查询效率非常高效。
优点是数据库自带的索引机制是比较稳定可靠且高效的;缺陷是随着查询场景的增多,索引的量会随之上升。
订单自身的属性随着业务的发展已经达到上千,高频率查询的维度可多达几十种,组合之后的变形形态可达上百种。
而索引本身并不是没有代价的,每次增删改都会有额外的写操作,同时占用额外的物理存储空间。
索引越多,数据库索引维护的成本越大。所以还有其他选择么?
开源搜索引擎的选择
当时闪现在我们脑中的是开源搜索引擎 Apache Solr 和 Elastic Search。
Solr 是一个建立在 Java 类库 Lucene 之上的开源搜索平台,以一种更友好的方式提供 Lucene 的搜索能力。
它已经存在十年之久,是一款非常成熟的产品,提供分布式索引、复制分发、负载均衡查询,自动故障转移和恢复功能。
Elastic Search 也是一个建立在 Lucene 之上的分布式 RESTful 搜索引擎。
通过 RESTful 接口和 Schema Fee JSON 文档,提供分布式全文搜索引擎。每个索引可以被分成多个分片,每个分片可以有多个备份。
两者对比各有优劣:
- 在安装和配置方面,得益于产品较新,Elastic Search 更轻量级以及易于安装使用。
- 在搜索方面,撇开大家都有的全文搜索功能,Elastic Search 在分析性查询中有更好的性能。
- 在分布式方面,Elastic Search 支持在一个服务器上存在多个分片,并且随着服务器的增加,自动平衡分片到所有的机器。
- 社区与文档方面,Solr 得益于其资历,有更多的积累。
根据 Google Trends 的统计,Elastic Search 比 Solr 有更广泛的关注度。
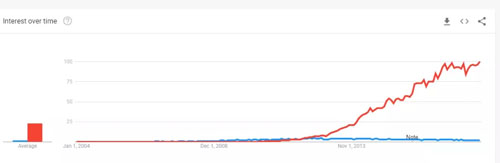
最终我们选择了 Elastic Search,看中的是它的轻量级、易用和对分布式更好的支持,整个安装包也只有几十兆。
复制分发的实现
为了避免重复造轮子,我们尝试寻找现存组件。由于数据库是 SQL Server 的,所以没有找到合适的开源组件。
SQL Server 本身有实时监控增删改的功能,把更新后的数据写到单独的一张表。
但是它并不能自动把数据写到 Elastic Search,也没有提供相关的 API 与指定的应用进行通讯,所以我们开始尝试从应用层面去实现复制分发。
为什么没有使用数据访问层复制分发
首先进入我们视线的是数据访问层,它可能是一个突破口。每当应用对数据库进行增删改时,实时写一条数据到 Elastic Search。
但是考虑到以下情况后,我们决定另辟蹊径:
有几十个应用在访问数据库,有几十个开发都在改动数据访问层的代码。如果要实现数据层的复制分发,必须对现有十几年的代码进行肉眼扫描,然后进行修改。开发的成本和易错性都很高。
每次增删改时都写 Elastic Search,意味着业务处理逻辑与复制分发强耦合。
Elastic Search 或相关其他因素的不稳定,会直接导致业务处理的不稳定。
异步开线程写 Elastic Search?那如何处理应用发布重启的场景?加入大量异常处理和重试的逻辑?然后以 JAR 的形式引用到几十个应用?一个小 Bug 引起所有相关应用的不稳定?
实时扫描数据库
初看这是一种很低效的方案,但是在结合以下实际场景后,它却是一种简单、稳定、高效的方案:
- 零耦合。相关应用无需做任何改动,不会影响业务处理效率和稳定性。
- 批量写 Elastic Search。由于扫描出来的都是成批的数据,可以批量写入 Elastic Search,避免 Elastic Search 由于过多单个请求,频繁刷新缓存。
- 存在大量毫秒级并发的写。扫描数据库时无返回数据意味着额外的数据库性能消耗,我们的场景写的并发和量都非常大,所以这种额外消耗可以接受。
- 不删除数据。扫描数据库无法扫描出删除的记录,但是订单相关的记录都需要保留,所以不存在删除数据的场景。
提高 Elastic Search 写的吞吐量
由于是对数据库的实时复制分发,效率和并发量要求都会较高。以下是我们对 Elastic Search 的写所采用的一些优化方案:
使用 upsert 替代 select + insert/update
类似于 MySQL 的 replace into,避免多次请求,成倍节省多次请求带来的性能消耗。
使用 bulkrequest,把多个请求合并在一个请求里面
Elastic Search 的工作机制对批量请求有较好的性能,例如 translog 的持久化默认是 request 级别的,这样写硬盘的次数就会大大降低,提高写的性能。
至于具体一个批次多少个请求,这个与服务器配置、索引结构、数据量都有关系。可以使用动态配置的方式,在生产上面调试。
对于实时性要求不高的索引
把 index.refresh_interval 设置为 30 秒(默认是 1 秒),这样可以让 Elastic Search 每 30 秒创建一个新的 segment,减轻后面的 flush 和 merge 压力。
提前设置索引的 schema,去除不需要的功能
例如默认对 string 类型的映射会同时建立 keyword 和 text 索引,前者适合于完全匹配的短信息,例如邮寄地址、服务器名称,标签等。
而后者适合于一片文章中的某个部分的查询,例如邮件内容、产品说明等。
根据具体查询的场景,选择其中一个即可,如下图:

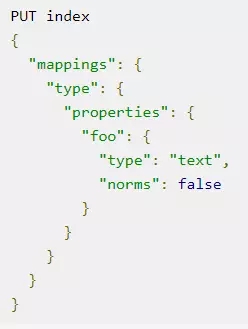
对于不关心查询结果评分的字段,可以设置为 norms:false。
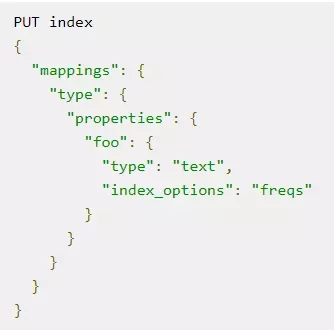
对于不会使用 phrase query 的字段,设置 index_options:freqs。
对于能接受数据丢失的索引或者有灾备服务器的场景
把 index.translog.durability 设置成 async(默认是 request)。把对 lucene 的写持久化到硬盘是一个相对昂贵的操作,所以会有 translog 先持久化到硬盘,然后批量写入 lucene。
异步写 translog 意味着无需每个请求都去写硬盘,能提高写的性能。在数据初始化的时候效果比较明显,后期实时写入使用 bulkrequest 能满足大部分的场景。
提高 Elastic Search 读的性能
为了提高查询的性能,我们做了以下优化:写的时候指定查询场景***的字段为 _routing 的值。
由于 Elastic Search 的分布式分区原则默认是对文档 id 进行哈希和取模决定分片,所以如果把查询场景***的字段设为 _routing 的值就能保证在对该字段查询时,只要查一个分片即可返回结果。
写:
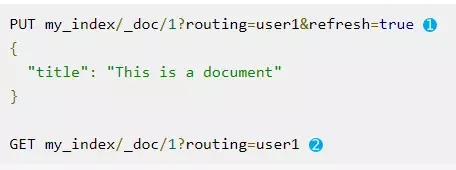
查:

对于日期类型,在业务能够接受的范围内,尽可能降低精确度。能只包含年月日,就不要包含时分秒。
当数据量较大时,这个优化的效果会特别的明显。因为精度越低意味着缓存的***率越高,查询的速度就会越快。
同时内存的重复利用也会提升 Elastic Search 服务器的性能,降低 CPU 的使用率,减少 GC 的次数。
系统监控的实现
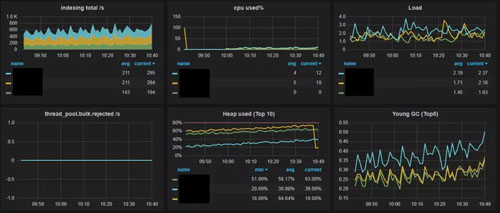
技术中心专门为业务部门开发了一套监控系统。它会周期性的调用所有服务器的 Elastic Search CAT API,把性能数据保存在单独的 Elastic Search 服务器中,同时提供一个网页给应用负责人进行数据的监控。
灾备的实现
Elastic Search 本身是分布式的。在创建索引时,我们根据未来几年的数据总量进行了分片,确保单片数据总量在一个健康的范围内。
为了在写入速度和灾备之间找到一个平衡点,把备份节点设置为 2。
所以数据分布在不同的服务器上,如果集群中的一个服务器宕机,另外一个备份服务器会直接进行服务。
同时为了防止一个机房发生断网或者断电等突发情况,而导致整个集群不能正常工作,我们专门在不同地区的另一个机房部署了一套完全一样的 Elastic Search 集群。
日常数据在复制分发的时候,会同时写一份到灾备机房以防不时之需。
总结
整个项目的开发是一个逐步演进的过程,实现过程中也遇到了大量问题。
项目上线后,应用服务器的 CPU 与内存都有大幅下降,同时查询速度与没有分片之前基本持平。在此分享遇到的问题和解决问题的思路,供大家参考。
参考:
- Elastic Search官方文档;
- https://en.wikipedia.org/wiki/Database_index
- https://baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B4%A2%E5%BC%95
- https://logz.io/blog/solr-vs-elasticsearch/