













背景
Redis混合存储产品是阿里云自主研发的完全兼容Redis协议和特性的混合存储产品。
通过将部分冷数据存储到磁盘,在保证绝大部分访问性能不下降的基础上,大大降低了用户成本并突破了内存对Redis单实例数据量的限制。
其中,对冷热数据的识别和交换是混合存储产品性能的关键因素。
冷热数据定义
在Redis混合存储中,内存和磁盘的比例是用户可以自由选择的:
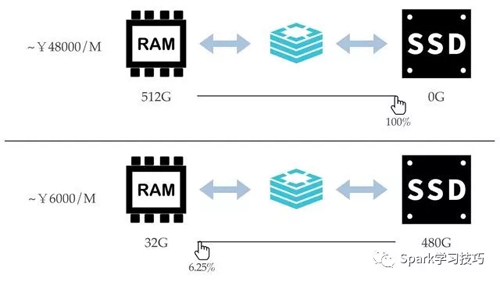
Redis混合存储实例将所有的Key都认为是热数据,以少量的内存为代价保证所有Key的访问请求的性能是高效且一致的。而对于Value部分,在内存不足的情况下,实例本身会根据最近访问时间,访问频度,Value大小等维度选取出部分value作为冷数据后台异步存储到磁盘上直到内存小于制定阈值为止。
在Redis混合存储实例中,我们将所有的Key都认为是热数据保存在内存中是出于以下两点考虑:
- Key的访问频度比Value要高很多。
- 作为KV数据库,通常的访问请求都需要先查找Key确认Key是否存在,而要确认一个key不存在,就需要以某种形式检查所有Key的集合。在内存中保留所有Key,可以保证key的查找速度与纯内存版完全一致。
- Key的大小占比很低。
- 即使是普通字符串类型,通常的业务模型里面Value比Key要大几倍。而对于Set,List,Hash等集合对象,所有成员加起来组成的Value更是比Key大了好几个数量级。
因此,Redis混合存储实例的适用场景主要有以下两种:
- 数据访问不均匀,存在热点数据;
- 内存不足以放下所有数据,且Value较大(相对于Key而言)
冷热数据识别
当内存不足时的情况下,实例会按照最近访问时间,访问频度,value大小等维度计算出value的权重,将权重***的value存储到磁盘上并从内存中删除。
伪代码如下:

理想的情况下,我们当然希望能够准确的计算出当前最冷的value。然而,value的冷热程度根据访问情况动态变化的,每次都重新计算所有value的冷热权重的时间消耗是完全不可接受的。
Redis本身在内存满的情况下会根据用户设置的淘汰策略淘汰数据,而热数据从内存写到磁盘也可以认为是一种“淘汰”的过程。从性能,准确率以及用户理解程度考虑,我们在冷热数据识别时采用和Redis类似的近似计算方法,支持多种策略, 通过随机采样小部分数据来降低CPU和内存消耗,通过eviction pool利用采样历史信息来辅助提高准确率。

上图为不同版本和不同采样样本数目配置下,Redis近似淘汰算法的***率示意图。浅灰色的点为被淘汰数据,灰色的点为未淘汰数据,绿色点为测试过程中新加入的数据。
冷热数据交换
Redis混合存储在冷热数据交换过程在后台IO线程中完成。
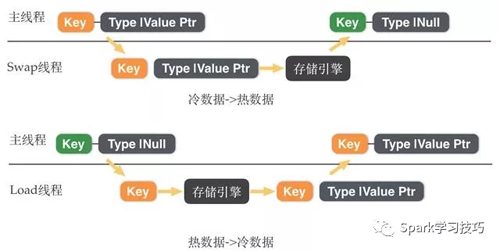
热数据->冷数据
异步方式:
- 主线程在内存接近***值时,生成一系列数据换出任务;
- 后台线程执行这些数据换出任务,执行完毕之后通知主线程;
- 主线程更新释放内存中的value,更新内存中数据字典中的value为一个简单的元信息;
- 同步方式:
如果写入流量过大,异步方式来不及换出数据,导致内存超出***规格内存。主线程将直接执行数据换出任务,达到变相限流的目的。
冷数据->热数据
异步方式:
- 主线程在执行命令前,先判断命令涉及的value是否都在内存中;
- 如果不是,生成数据加载任务,挂起该客户端,主线程继续处理其他客户端请求;
- 后台线程执行数据加载任务,执行完毕后通知主线程;
- 主线程在内存中更新数据字典中的value,唤醒之前挂起的客户端,处理其请求。
- 同步方式:
在Lua脚本,具体命令执行阶段,如果发现有value存储在磁盘上,主线程将直接执行数据加载任务,保证Lua脚本和命令的语义不变。



















