京东为什么要做万台规模的Hadoop?
随着京东的业务增长,原有的Hadoop集群已经无法满足高速增长的存储与计算需求。拆分集群虽然可以分担一部分压力,但带来了另外的一些问题,如拆分集群之后假如某个业务无法避免的需要另外一个集群上的数据,这时便带来了跨集群读数据的问题,严重影响了作业执行效率。另一方面,各个集群总有闲忙时间,在某个集群闲时这些资源是浪费的并没有产生价值。
为了增加生产效率和节约成本,必须要将之前分散在各处的集群资源统一管理起来,组成一个超大集群对外提供服务,并且要让各种并行框架可以利用它的存储和计算资源进行业务处理。
Hadoop 概述
Hadoop 作为大数据的处理平台已经有十几年的发展历史。其设计思想是使用廉价的台式机组成一个大的集群做分布式计算与数据存储,利用冗余备份的方式保证数据的安全性和高可用,通过并行计算的方式完成超大数据集的快速处理。
通过增加节点的方式提升Hadoop集群的计算和存储能力。通常在分布式并行处理数据时,移动计算代码的成本会低于移动数据,所以Hadoop的MapReduce框架计算时会将计算代码分发到每个数据节点上执行,利用数据本地性较少的网络交互提升性能。
过去Hadoop 2.0版本之前,Hadoop在设计上包含两部分,***部分是分布式存储HDFS,另一部分是MapReduce 计算框架。自Hadoop2.0 版本之后,计算框架部分做了优化升级变成了我们现在用的YARN (Yet Another Resource Negotiator) , YARN提供了分布式资源管理和作业调度的功能,同时提供了统一的编程模型,通过这个编程模型很多计算框架可以迁移到YARN上来。

从愿景上,Hadoop 致力于解决复杂数据的处理和运算,处理结构化和非结构化数据存储,提供分布式海量数据并行处理。
回想过去我们使用MPI、OpenMP去实现一个分布式处理程序,那时我们需要自己控制程序的远程启动与停止,同时要自己编写容错代码。现在Hadoop通过优化和抽象将这些繁琐的、能够通用的功能都封装到了框架中,让开发者只需要关注自己的业务逻辑代码而不需要再写一些错误重试和通讯相关的代码,大大增加了开发效率。同时使用那些并不太擅长编写代码的数据工程师也可以轻松使用Hadoop集群去实现自己的分布式处理分析程序。

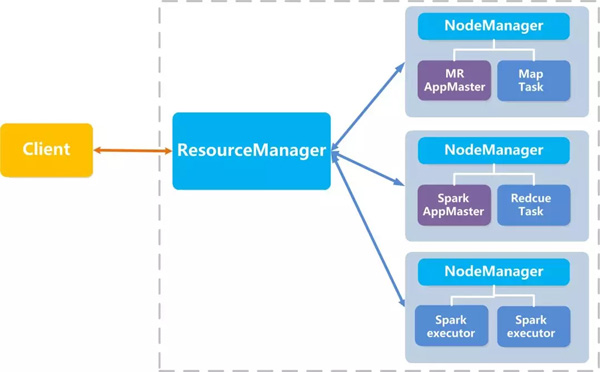
在Hadoop 2.0 YARN 架构下,主要有以下几个组件:
1. ResourceManager:主节点服务,负责维护节点信息和负责资源管理与作业调度, 可以部暑两台并利用Zookeeper 实现高可用
2. NodeManager:计算节点服务,负责提供计算和管理当前节点上的Container进程。可以部署1~N台
3. ApplicationMaster:用户每提交一个应用都会包含一个ApplicationMaster, 负责与RM通讯申请或释放资源与NM通讯启动和停止Task. 监控任务的运行状态
4. Container:Container是YARN中的资源抽象,它封装了多个纬度的资源,如CPU、内存、磁盘等
5. Client:负责提交作业,同时提供一些命令行工具
京东Hadoop分布式资源管理与作业调度介绍
京东从很早之前就开始使用Hadoop,踩了很多坑,从过去摸着石头过河到现在小有所成,无论是业务问题还是Hadoop框架本身的问题,我们都遇到过。
通过解决这些问题我们对Hadoop做了很多功能升级与修改,其中有一些功能回馈到了社区,另外一些沉淀到了我们自己的分支版本中。今天我们的Hadoop大数据平台提供了丰富的功能、完善的工具,为京东大数据业务保驾护航。
目前在京东大数据环境下,为满足不同业务对运行环境需求,我们利用Docker On YARN的模式把运行环境隔离做了隔离,允许每个人定制自己的运行环境安装自己的算法库。使用Linux CGroup的模式支持严格的计算资源隔离,保证每个作业的计算资源不受其他作业影响。另扩展了资源与调度模型,增加了GPU和其他硬件的调度支持。为业务方统一了日志查询工具帮助快速定位错误。
过去大数据平台这边有各种小集群,如:Presto, Alluxio 等,每个小集群都有自己的一批机器,每台机器上可能只部署一个服务,这些服务对机器的利用率并不高,甚至是浪费的,痛定思痛,我们决定利用YARN统一进行资源管理与调度。经过几年的发展,我们将大部分的并行框架都移植到了YARN上运行(如:Presto、Alluxio),利用YARN的优势和调度特点充分的利用这些机器资源,大大提升了集群资源利用率。
同时我们也自研了Tensorflow On YARN 、Caffe On YARN 等一系列的深度学习框架与工具帮助算法工程师直接使用Hadoop集群进行算法处理。大大加快了算法与业务迭代速度。让大数据平台获得了深度学习处理的能力。

后来为了更好的支持异地多活和跨地域扩展能力,我们再次改造升级实现了万台Hadoop集群分布式资源管理与调度系统,解决了之前单集群扩展瓶颈和无法有效支撑跨机房调度与灾备的问题。该系统已经在线上部署,并经过了今年618的大促考验,可以说是稳如磐石。
系统逐步铺开上线之后我们将京东跨地域的几个大数据机房实现了互联,同时我们的HDFS也配套实现了同样的跨机房功能,也在这时京东大数据处理平台系统真正拥有了跨地域的部署与扩展能力。
系统具有非常强的灵活性,可以通过修改调度路由策略和存储数据映射表,轻松的做到跨机房的作业迁移和数据迁移。同机房内不同集群之间可以实现作业跨子集群运行充分利用各集群资源,功能可随时根据子集群负载动态开关,无需用户参与,对用户完全透明。
为了使新的大数据平台系统更友好更易于管理使用,团队开启了界面化项目。我们利用WEB技术实现了面向管理员的大数据平台管理系统,使用这套管理系统之后可以灵活方便的上下线子集群,实时管理和修改调度策略,不再需要像以前一样登陆到对应的物理服务器上执行相关命令。通过标准化系统化,我们将运维命令封装在了代码里,每个命令执行前后都有相关的校验与权限认证,减少人工操作时出现的误操作,如果发生错误系统将自动回滚。

平台提供了基于用户级的权限管理,可以很灵活的管理集群中计算资源的权限,以实现控制每个用户可以使用的计算资源量大小和资源池使用权限认证。
真实生产环境中平台会把资源按照一定的使用规则进行划分,并分配相关的权限给对应的人或部门,从而避免某些用户恶意提交作业到别人的资源池。同时平台也细化了操作权限避免某些用户恶意操作别人的作业(如:停止执行)。

之前大数据平台会存在多个集群,每个集群对应自己的客户端,每个客户端对应自己的配置文件,运维起来麻烦不利于管理。

调度架构修改升级完之后,从逻辑上可以理解为增加了一层调度抽象(Router),由原来的两级调度变成了三级调度。也就是子集群的策略选择。现在的作业提交流程是:
1. 客户端先将作业提交请求发送给Router
2. Router根据配置的调度信息将作业请求转发给对应的子集群
3. 子集群收到作业请求之后安排作业的运行
在这种方式下,每个客户端使用同样的一套配置文件,保证了客户端轻量级,不再像之前一样需要区分集群信息。所有的调度策略与逻辑都封装在Router组件中。(所有的调度策略和控制信息我们保存在DBMS中)
增加了作业的动态跨子集群借用资源功能,可以随时控制某个队列中的相关作业是否需要跨子群执行。方便单个子集群在资源紧张时动态去借用另一个空闲集群的资源。
增加了逻辑队列名的概念,对于用户来说他们只需要关心自己的逻辑队列名,而真正运行作业是在哪个物理队列则不需要他们关心,通过这个功能平台端可以随时控制逻辑队列真正运行在哪个子集群的哪个物理队列。达到快速迁移或容灾的目的。
为了避免Router意外丢失或挂掉,在Router组件方面,我们单独开发了高可用和负载均衡功能,整个集群会部署多台Router节点,每个机房都会有一个或多个Router, 客户端的请求会根据负载和距离从分散的多个Router服务器上选择一个最合适的。同时我们支持任何时间点Router挂掉(如果Router的连接状态不可用客户端会自动切换到另外一个Actvie的Router)

下面是这个架构的逻辑框图,包含了整个架构中所有组件。其中新增是Router和State&Policy Store 两个组件,前者直接对接Client 屏蔽后端RM子集群相关信息提供提交与作业信息查询的功能,可以同时部署多台对外提供服务。后者负责保存当前所有子集群的状态信息、Active RM 的地址信息和调度策略信息。(每隔一段时间子集群会以心跳的方式汇报自己当前的服务状态并存储到StateStore中)目前我们支持多种调度策略可以满足多种场景下的调度需求。
具体提交流程如下:
1. Client 提交作业到Router上
2. Router 获取逻辑队列调度策略信息
3. 将作业提交请求转提到对应的ResourceManager上,并保存Application相关信息到StateStore中
4. ResourceManager接收到请求后启动AppMaster, AppMaster启动之后向AMRMProxy发起资源请求
5. AMRMProxy 接收到这个请求之后,从State&Store Policy中读取策略信息,判断这个作业是否需要跨子集群运行
6. 向对应的子集群发送资源请求,AppMaster负责启动请求到的Container

超大规模Hadoop集群优化策略&优化思路
原生的调度器,存在很多问题。其中最主要的是性能问题,为此我们自研了一个基于队列镜像的多路分配策略,大大提升了ResourceManager调度器的性能,让我们单个YARN子集群拥有了超过万台规模资源管理与调度能力。
另一方面丰富了调度器分配资源的算法逻辑,增加多个维度的排序筛选规则,多个规则之间可以组合使用,如:基于内存、基于负载 、基于使用率等等。
还有其他一些ResourceManager性能相关的代码优化,如:简化资源计算流程,拆分锁等等。
在MapReduce方面优化了服务性能和框架功能。主要与Shuffle 服务相关。
优化&分析&测试工具
Benchmark
- HiBench https://github.com/intel-hadoop/HiBench
- Hadoop 自带 Benchmark
JVM分析工具
- http://gceasy.io/
- http://fastthread.io
Linux 性能分析
- Perf
- NMON
- Google Tools
未来展望与期待
京东大数据平台的实践提供了一种可供参考的技术架构与实施方式。未来,京东大数据平台依然会在电商级分布式架构与技术方案演进方向继续前进。对此我们也有一些新的功能即将上线。
一、如何利用集团内的资源节省成本
过去每年的大促都需要根据往年的流量进行机器的采购,大促结束之后这些机器利用率很低浪费了大量成本,为了解决这个问题,目前的大数据平台已经与集团内的专有云-阿基米德完成了对接,平台可以通过自动伸缩的方式弹性使用云资源,未来的大促中将利用这个功能去承接一部分计算任务。
二、大数据平台产品化
京东在大数据处理方面积累了丰富的经验,同时沉淀出了一些很优秀的中间件和服务产品,未来我们将陆续把这些产品云化对外提供服务。