引言
为什么写这篇文章?
目前网上大部分的基于zookeeper,和redis的分布式锁的文章都不够全面。要么就是特意避开集群的情况,要么就是考虑不全,读者看着还是一脸迷茫。坦白说,这种老题材,很难写出新创意,博主内心战战兢兢,如履薄冰,文中有什么不严谨之处,欢迎批评。
博主的这篇文章,不上代码,只讲分析。
(1)在redis方面,有开源redisson的jar包供你使用。
(2)在zookeeper方面,有开源的curator的jar包供你使用
因为已经有开源jar包供你使用,没有必要再去自己封装一个,大家出门百度一个api即可,不需要再罗列一堆实现代码。
需要说明的是,Google有一个名为Chubby的粗粒度分布锁的服务,然而,Google Chubby并不是开源的,我们只能通过其论文和其他相关的文档中了解具体的细节。值得庆幸的是,Yahoo!借鉴Chubby的设计思想开发了zookeeper,并将其开源,因此本文不讨论Chubby。至于Tair,是阿里开源的一个分布式K-V存储方案。我们在工作中基本上redis使用的比较多,讨论Tair所实现的分布式锁,不具有代表性。
因此,主要分析的还是redis和zookeeper所实现的分布式锁。
文章结构
本文借鉴了两篇国外大神的文章,redis的作者antirez的《
》以及分布式系统专家Martin的《
》,再加上自己微薄的见解从而形成这篇文章,文章的目录结构如下:
(1)为什么使用分布式锁
(2)单机情形比较
(3)集群情形比较
(4)锁的其他特性比较
正文
先上结论:
zookeeper可靠性比redis强太多,只是效率低了点,如果并发量不是特别大,追求可靠性,***zookeeper。为了效率,则***redis实现。
为什么使用分布式锁?
使用分布式锁的目的,无外乎就是保证同一时间只有一个客户端可以对共享资源进行操作。
但是Martin指出,根据锁的用途还可以细分为以下两类:
(1)允许多个客户端操作共享资源
这种情况下,对共享资源的操作一定是幂等性操作,无论你操作多少次都不会出现不同结果。在这里使用锁,无外乎就是为了避免重复操作共享资源从而提高效率。
(2)只允许一个客户端操作共享资源
这种情况下,对共享资源的操作一般是非幂等性操作。在这种情况下,如果出现多个客户端操作共享资源,就可能意味着数据不一致,数据丢失。
***回合,单机情形比较
(1)redis
先说加锁,根据redis官网文档的描述,使用下面的命令加锁
SET resource_name my_random_value NX PX 30000
- my_random_value是由客户端生成的一个随机字符串,相当于是客户端持有锁的标志
- NX表示只有当resource_name对应的key值不存在的时候才能SET成功,相当于只有***个请求的客户端才能获得锁
- PX 30000表示这个锁有一个30秒的自动过期时间。
至于解锁,为了防止客户端1获得的锁,被客户端2给释放,采用下面的Lua脚本来释放锁
- if redis.call("get",KEYS[1]) == ARGV[1] then
- return redis.call("del",KEYS[1])
- else
- return 0
在执行这段LUA脚本的时候,KEYS[1]的值为resource_name,ARGV[1]的值为my_random_value。原理就是先获取锁对应的value值,保证和客户端穿进去的my_random_value值相等,这样就能避免自己的锁被其他人释放。另外,采取Lua脚本操作保证了原子性.如果不是原子性操作,则有了下述情况出现:
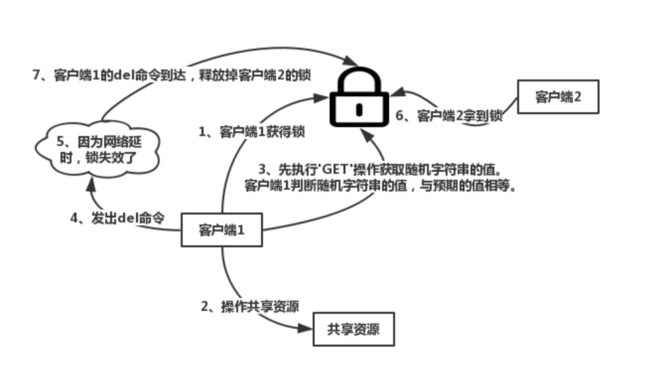
分析:这套redis加解锁机制看起来很***,然而有一个无法避免的硬伤,就是过期时间如何设置。如果客户端在操作共享资源的过程中,因为长期阻塞的原因,导致锁过期,那么接下来访问共享资源就不安全。
可是,有的人会说
那可以在客户端操作完共享资源后,判断锁是否依然归该客户端所有,如果依然归客户端所有,则提交资源,释放锁。若不归客户端所有,则不提交资源啊!
OK,这么做,只能降低多个客户端操作共享资源发生的概率,并不能解决问题。
为了方便读者理解,博主举一个业务场景。
业务场景:我们有一个内容修改页面,为了避免出现多个客户端修改同一个页面的请求,采用分布式锁。只有获得锁的客户端,才能修改页面。那么正常修改一次页面的流程如下图所示:
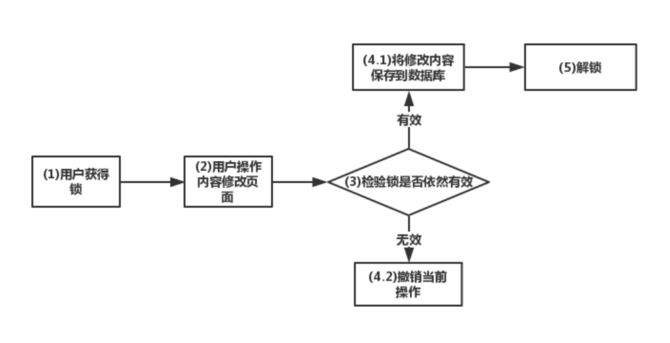
注意看,上面的步骤(3)-->步骤(4.1)并不是原子性操作。也就说,你可能出现在步骤(3)的时候返回的是有效这个标志位,但是在传输过程中,因为延时等原因,在步骤(4.1)的时候,锁已经超时失效了。那么,这个时候锁就会被另一个客户端锁获得。就出现了两个客户端共同操作共享资源的情况。
大家可以思考一下,无论你如何采用任何补偿手段,你都只能降低多个客户端操作共享资源的概率,而无法避免。例如,你在步骤(4.1)的时候也可能发生长时间GC停顿,然后在停顿的时候,锁超时失效,从而锁也有可能被其他客户端获得。这些大家可以自行思考推敲。
(2)zookeeper
先简单说下原理,根据网上文档描述,zookeeper的分布式锁原理是利用了临时节点(EPHEMERAL)的特性。
- 当znode被声明为EPHEMERAL的后,如果创建znode的那个客户端崩溃了,那么相应的znode会被自动删除。这样就避免了设置过期时间的问题。
- 客户端尝试创建一个znode节点,比如/lock。那么***个客户端就创建成功了,相当于拿到了锁;而其它的客户端会创建失败(znode已存在),获取锁失败。
分析:这种情况下,虽然避免了设置了有效时间问题,然而还是有可能出现多个客户端操作共享资源的。
大家应该知道,zookeeper如果长时间检测不到客户端的心跳的时候(Session时间),就会认为Session过期了,那么这个Session所创建的所有的ephemeral类型的znode节点都会被自动删除。
这种时候会有如下情形出现
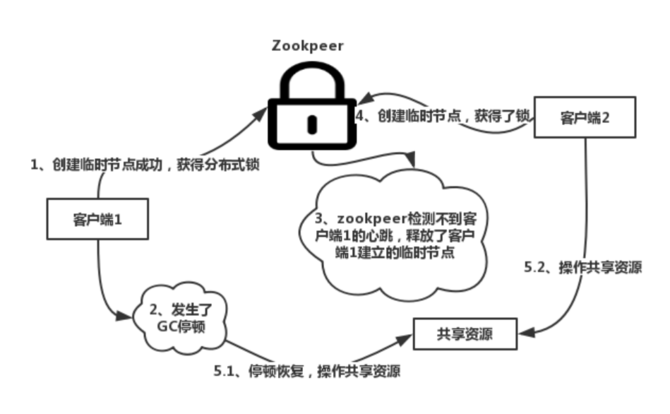
如上图所示,客户端1发生GC停顿的时候,zookeeper检测不到心跳,也是有可能出现多个客户端同时操作共享资源的情形。当然,你可以说,我们可以通过JVM调优,避免GC停顿出现。但是注意了,我们所做的一切,只能尽可能避免多个客户端操作共享资源,无法完全消除。
第二回合,集群情形比较
我们在生产中,一般都是用集群情形,所以***回合讨论的单机情形。算是给大家热热身。
(1)redis
为了redis的高可用,一般都会给redis的节点挂一个slave,然后采用哨兵模式进行主备切换。但由于Redis的主从复制(replication)是异步的,这可能会出现在数据同步过程中,master宕机,slave来不及同步数据就被选为master,从而数据丢失。具体流程如下所示:
(1)客户端1从Master获取了锁。
(2)Master宕机了,存储锁的key还没有来得及同步到Slave上。
(3)Slave升级为Master。
(4)客户端2从新的Master获取到了对应同一个资源的锁。
为了应对这个情形, redis的作者antirez提出了RedLock算法,步骤如下(该流程出自官方文档),假设我们有N个master节点(官方文档里将N设置成5,其实大等于3就行)
(1)获取当前时间(单位是毫秒)。
(2)轮流用相同的key和随机值在N个节点上请求锁,在这一步里,客户端在每个master上请求锁时,会有一个和总的锁释放时间相比小的多的超时时间。比如如果锁自动释放时间是10秒钟,那每个节点锁请求的超时时间可能是5-50毫秒的范围,这个可以防止一个客户端在某个宕掉的master节点上阻塞过长时间,如果一个master节点不可用了,我们应该尽快尝试下一个master节点。
(3)客户端计算第二步中获取锁所花的时间,只有当客户端在大多数master节点上成功获取了锁(在这里是3个),而且总共消耗的时间不超过锁释放时间,这个锁就认为是获取成功了。
(4)如果锁获取成功了,那现在锁自动释放时间就是最初的锁释放时间减去之前获取锁所消耗的时间。
(5)如果锁获取失败了,不管是因为获取成功的锁不超过一半(N/2+1)还是因为总消耗时间超过了锁释放时间,客户端都会到每个master节点上释放锁,即便是那些他认为没有获取成功的锁。
分析:RedLock算法细想一下还存在下面的问题:
节点崩溃重启,会出现多个客户端持有锁
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
(1)客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
(2)节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
(3)节点C重启后,客户端2锁住了C, D, E,获取锁成功。
这样,客户端1和客户端2同时获得了锁(针对同一资源)。
为了应对节点重启引发的锁失效问题,redis的作者antirez提出了延迟重启的概念,即一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,等待的时间大于锁的有效时间。采用这种方式,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。这其实也是通过人为补偿措施,降低不一致发生的概率。
时间跳跃问题
(1)假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
(2)客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
(3)节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
客户端1和客户端2现在都认为自己持有了锁。
为了应对始终跳跃引发的锁失效问题,redis的作者antirez提出了应该禁止人为修改系统时间,使用一个不会进行“跳跃”式调整系统时钟的ntpd程序。这也是通过人为补偿措施,降低不一致发生的概率。
超时导致锁失效问题
RedLock算法并没有解决,操作共享资源超时,导致锁失效的问题。回忆一下RedLock算法的过程,如下图所示:
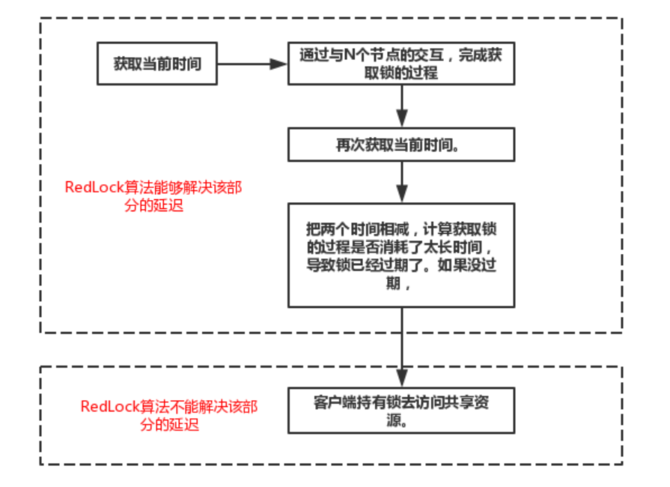
如图所示,我们将其分为上下两个部分。对于上半部分框图里的步骤来说,无论因为什么原因发生了延迟,RedLock算法都能处理,客户端不会拿到一个它认为有效,实际却失效的锁。然而,对于下半部分框图里的步骤来说,如果发生了延迟导致锁失效,都有可能使得客户端2拿到锁。因此,RedLock算法并没有解决该问题。
(2)zookeeper
zookeeper在集群部署中,zookeeper节点数量一般是奇数,且一定大等于3。我们先回忆一下,zookeeper的写数据的原理。
如图所示,这张图懒得画,直接搬其他文章的了。
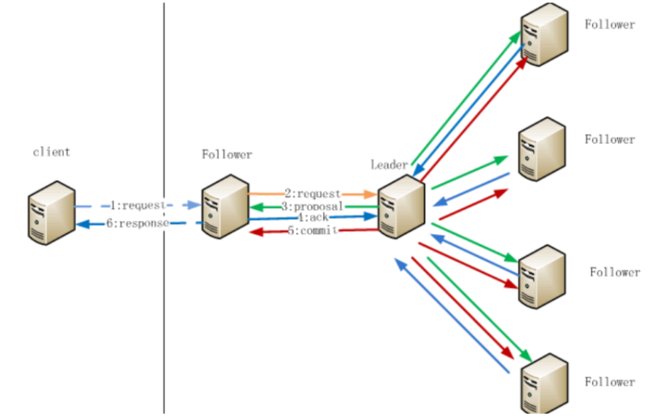
那么写数据流程步骤如下:
1.在Client向Follwer发出一个写的请求
2.Follwer把请求发送给Leader
3.Leader接收到以后开始发起投票并通知Follwer进行投票
4.Follwer把投票结果发送给Leader,只要半数以上返回了ACK信息,就认为通过
5.Leader将结果汇总后如果需要写入,则开始写入同时把写入操作通知给Leader,然后commit;
6.Follwer把请求结果返回给Client
还有一点,zookeeper采取的是全局串行化操作。
OK,现在开始分析。
集群同步
client给Follwer写数据,可是Follwer却宕机了,会出现数据不一致问题么?不可能,这种时候,client建立节点失败,根本获取不到锁。
client给Follwer写数据,Follwer将请求转发给Leader,Leader宕机了,会出现不一致的问题么?不可能,这种时候,zookeeper会选取新的leader,继续上面的提到的写流程。
总之,采用zookeeper作为分布式锁,你要么就获取不到锁,一旦获取到了,必定节点的数据是一致的,不会出现redis那种异步同步导致数据丢失的问题。
时间跳跃问题
不依赖全局时间,怎么会存在这种问题
超时导致锁失效问题
不依赖有效时间,怎么会存在这种问题
第三回合,锁的其他特性比较
(1)redis的读写性能比zookeeper强太多,如果在高并发场景中,使用zookeeper作为分布式锁,那么会出现获取锁失败的情况,存在性能瓶颈。
(2)zookeeper可以实现读写锁,redis不行。
(3)zookeeper的watch机制,客户端试图创建znode的时候,发现它已经存在了,这时候创建失败,那么进入一种等待状态,当znode节点被删除的时候,zookeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。这套机制,redis无法实现。
总结
OK,正文啰嗦了一大堆。其实只是想表明两个观点,无论是redis还是zookeeper,其实可靠性都存在一点问题。但是,zookeeper的分布式锁的可靠性比redis强太多!但是,zookeeper读写性能不如redis,存在着性能瓶颈。大家在生产上使用,可自行进行评估使用。