












大数据文摘出品
编辑:李馨瑜、Yanruo
AlphaGo打败李世乭、南京大学设立人工智能学院、百度无人车批量生产....
每当人工智能和机器学习取得一些进展时,这些进展一定占据着各大媒体的头版头条。
媒体对其有如此高的关注度,这意味着,现在科技界主流的兴趣领域是数据科学。
对于有大局意识的人来说,这无疑是一个很好的创业机会和职业选择。要想抓住职业机会,你需要超强的“码力”和深入的专业知识。
然而,每个想在数据领域有所成就的数据科学家应该非常熟悉,在吸睛的神经网络和分布式计算名词背后是一些基本的统计实践。
你可以为特定的项目去学习***的代码框架或者阅读该领域***成果的科研论文。但是,没有捷径可以获得数据科学家所需的基础统计知识。
所以,只有不停地耐心练习,再加上一些学习过程中的挫折,才能真正提高你的“数据直觉”。
简约原则
简约原则在介绍性的统计课程中反复强调,但英国统计学家乔治·博克斯今天说的话可能比之前更有意义:
| “所有模型都错了,但有些模型很有用” |
这句话想说明什么?
它的意思是说:在寻求对现实世界进行系统建模时,必须以牺牲易理解性为代价来简化和概括。
现实世界纷乱嘈杂,我们无法理解每一个细节。因此,统计建模并不是为了获得***的预测能力,而是用最小的必要的模型来实现***的预测能力。
对于那些刚接触数据世界的人来说,这个概念看起来可能违反直觉。但为什么不在模型中包含尽可能多的条件项呢?多余的条件项仅仅只能为模型增加说服力吗?
嗯,是的......不可以。你只需关心那些会显著增加模型解释力的条件项。
考虑将给定的数据集拟合不同类型的模型。
最基本的是null模型,它只有一个参数—响应变量的总体平均值(加上一些随机分布的错误)。
该模型假定响应变量不依赖于任何解释变量。相反,它的值完全由关于整体均值的随机波动来解释。这显然限制了模型的解释力。
在完全相反的饱和模型中,每个数据点都有一个参数。这样,你会有一个***的模型,但是如果你试图将新的数据用于模型,它没有任何解释力。
每个数据点包括一个特征的同时也忽略了任何有意义的简化方式。实际上用处并不大。
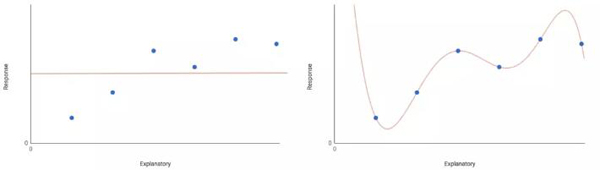
如上图左边是一个空模型,右边是一个饱和模型。两种模型都不会提供有力的说服力。
显然,这些是极端的情况。你应该在两者之间寻找一个模型—一个能很好地拟合数据并具有良好解释力的模型。 您可以尝试拟合***模型。 该模型包括所考虑的所有因素和制约条件。
例如,假设您有一个响应变量y,您希望将其作为解释变量x 1和x 2的函数进行建模,乘以系数β。 ***模型看起来像这样:
y = intercept + β₁x₁ + β₂x₂ + β₃(x₁x₂) + error
这个***模型可以很好地拟合数据,并提供良好的解释力。它包括每个解释变量项和一个交互项x₁x₂。
从模型中删除条件项将增加整体剩余偏差,或者观察到的预测模型未能将自身的变化考虑进来。
但是,并非所有条件项都一样重要。 您可以删除一个(或多个)条件项,但并不会发现统计结果上的显著偏差。
这些条件项可以被认为是无关紧要的,并从模型中删除。 您可以逐个删除无关紧要的项(记住重新计算每一步的剩余偏差)。 重复此操作,直到所有项保持良好的统计性。
现在你已经达到了最小的合适模型。每一项的系数β的估计值明显不同于0。得出此模型的逐步消除方法称为“逐步”回归。
支持这种简化模型的哲学原理被称为简约原则。
它与中世纪哲学家威廉的奥卡姆着名的启发式奥卡姆的剃刀有一些相似之处。 这个原则是这样的:“给出两个或多个同样可接受的现象解释,选择引入假设最少的那一个。”
换句话说:你能以最简单的方式解释一些复杂的东西吗? 可以说,这是数据科学的决定性追求 - 有效地将复杂性转化为可见性。
永远持怀疑态度
假设检验(如A / B检验)是一个重要的数据科学概念。
简单地说,假设检验将问题转化为两个相互排斥的假设,并且在哪个假设下询问检验统计量的观察值是最可能的。当然,检验统计量是从一组适当的实验或观察数据中计算出来的。
当涉及到假设检验时,通常会询问你是接受还是拒绝零假设。
通常,你会听到人们将零假设描述为令人失望的东西,甚至是实验失败的证据。
也许它源于如何向初学者普及假设检验,但似乎许多研究人员和数据科学家对零假设有潜意识偏见。他们试图拒绝它,支持所谓更令人兴奋,更有趣,另类的假设。
这不仅仅是一个奇闻乐事。目前已经有人撰写了完整的论文去研究科学文献中公开的学术偏见问题。人们仅仅想知道一点:这种倾向在商业环境下有什么影响。
然而事实是:对于任何设计合理的实验或完整的数据集,接受零假设应该与接受替代方案一样有趣。
实际上,零假设是推论统计的基石。它定义了我们作为数据科学家所做的工作,即将数据转化为洞察力。如果我们没有过多地地干涉统计结果的可能性,那么洞察力是没有价值的,正是由于这个原因,在任何时候都持怀疑态度是值得的。
特别是考虑到“意外地”拒绝零假设(至少在天真地应用频率论方法时)是多么容易时,怀疑态度更是不可缺少。
数据挖掘(或“p-hacking”)可以抛出各种无意义的结果,但这些结果有着非常重要的统计学意义。在无法避免多次比较的情况下,有必要采取措施减少I型错误(误报,或者说“看不到真正存在的效果”)。
- 首先,在统计测试方面,选择一个本质上谨慎的测试。检查是否正确满足了测试对数据的假设。
- 研究校正方法也很重要,例如Bonferroni校正。 然而,这些方法有时因过于谨慎而受到批评。 它们可能产生太多的II型错误(假阴性,或者说“忽略实际存在的效应”)从而降低统计的效果。
- 查找结果的“null”解释。 您的数据采集程序是否满足假设条件? 你能排除任何系统错误吗? 幸存者偏差,自相关或趋中心回归会有什么影响吗?
- ***,您发现的任何潜在关系有多可信? 无论正确率多低,都不要拿看起来好看的数据来糊弄。
怀疑主义是有益的,一般来说,始终注意对数据的空解释是一种好习惯。
但要避免偏执! 如果您已经很好地设计了实验,并谨慎地分析了您的数据,那么请将你的发现视为是真实的!
了解你的方法
最近技术和理论的进步为数据科学家提供了一系列强大的新工具,用于解决十年前甚至是两年前还无法解决的复杂问题。
机器学习的这些进步有理由让人万分激动。但是,当将其应用于特定问题时可能存在的限制很容易被忽略。
例如,神经网络在图像分类和手写识别方面可能非常出色,但它绝不是解决所有问题的***解决方案。首先,神经网络很容易过拟合—即对训练数据过度拟合,无法推广到新数据中。
如神经网络的不透明性。神经网络的预测能力通常以牺牲模型透明度为代价。由于特征选择的内化,即使网络进行了准确预测,你也不一定理解它是如何得出答案的。
在许多业务和商业应用中,理解“为什么和怎么做”通常是分析项目最重要的。为了预测准确性而放弃可理解性或许是值得做出的权衡。
同样,依靠复杂机器学习算法的准确性很吸引人,但它们绝不是***可靠的。
例如, 令人深刻的Google Cloud Vision API 也很容易被图像中的少量噪音欺骗。相反地,另一篇有趣的论文展示了深度神经网络如何“看到”那些根本不存在的图像。

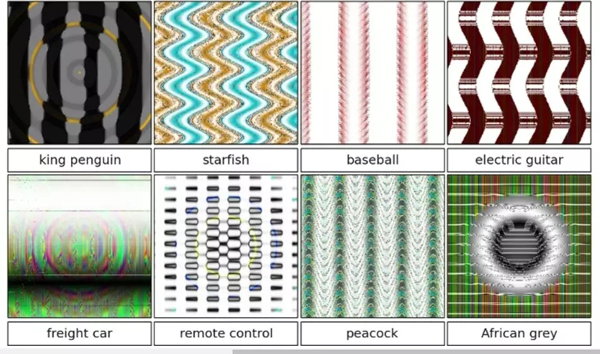
这不仅仅是需要谨慎使用的前沿机器学习方法。
即使采用更传统的建模方法,也需要注意满足关键假设。每次都注意使用到训练数据以为的数据时,如不怀疑也至少要谨慎使用。每次得到的结论都需要检验方法是否合理。
这并不是说根本不相信任何方法—只是要知道在任何时候为什么使用这种方法而不是另一种方法,以及其相对利弊。
一般地,如果你不能想出至少一个正考虑使用方法的缺点,那么在进行下一步之前深入研究它。始终使用最简单的工具来完成工作。
了解何时适合使用给定方法是否适合数据科学是一项关键技能。 这是一种随着经验和对方法的真正理解而提高的技能。
沟通
沟通是数据科学的精华。不同于学校的科目,你的目标受众将是你研究领域中受过专业训练的专家,商业数据科学家的观众可能会成为其他领域的专家。
如果沟通不畅,即使是世界上***的洞察力也没什么价值。许多来自学术/研究领域有抱负的数据科学家会与技术专业的受众进行沟通。
然而,在商业环境中,不能过分强调以一般受众能理解和可使用的方式来解释你的调查结果是多么重要。
例如,你的调查结果可能与机构内的一系列不同的部门(从营销,运营到产品开发)都相关。其中每个成员都将成为各自工作领域的专家,并将从简明扼要的相关调查结果的总结中受益。
与实际结果一样重要的是知道调查结果的局限性。确保你的受众了解工作流程中的任何关键假设、缺失数据或不确定程度。
老生常谈的“一张图片胜过千言万语”在数据科学中尤其如此。因此,数据可视化工具非常重要。
应用软件例如Tableau、程序库ggplot2 for R和D3.js等都是有效表达复杂数据的好方法,与任何技术概念一样值得掌握。
适当了解图形设计原则将大大有助于让你的图表看起来更加专业和出彩。
写作一定要清晰。生物进化已经将我们塑造成充满潜意识偏见的和易受影响的生物,我们固有地倾向于相信更好的展示和写得好的资料。
有时,理解概念的***方式是互动—因此学习一些前端网络技术来制作观众可以玩的交互可视化特效是值得的。我们没有必要重新造轮子,像D3.js和R's Shiny这样的库和工具可使任务变得更加容易。
相关报道:
https://medium.freecodecamp.org/how-to-develop-your-data-instincts-95d4d7fad9ba
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】


















