公有云的存储服务具有易扩展的特性,用户可以非常方便的根据其存储容量需求,对其已有的存储服务的容量进行扩展,因此从用户角度来说,公有云的存储服务具有***容量的特点。
- Unlimited Capacity:公有云的存储服务具有易扩展的特性,用户可以非常方便的根据其存储容量需求,对其已有的存储服务的容量进行扩展,因此从用户角度来说,公有云的存储服务具有***容量的特点。
- Low Cost:公有云的存储服务采用的是即用即付的模式,而且支持按照实际使用容量进行计费;同时也没有对存储基础设施的要求,所以具有低成本的优势。
- Performance not Well:通过公网对存储服务进行访问的网络开销,云服务商所采用的通用共享的硬件资源,以及通过虚拟化技术提供的服务,使得对于公有云存储服务来说,其访问性能并不是很高。
- Security and Controllability not Well:如前面说的,在公有云中,所有的硬件、软件和其他支持性基础架构都是云服务商所拥有和管理的,并且所有组织和租户都是共享相同的硬件、存储设备和网络设备,因此,从数据的安全性和可控制性角度来说,公有云的存储服务并不是一个理想的选择。
私有云存储
- High Performance:私有网络甚至是专线网络所带来的较小的网络开销,以及软、硬件资源选择上极大的灵活性,使得对于私有云存储服务来说,可以提供一个优于公有云的访问性能。
- High Security and Controllability:对于私有云存储服务来说,因为其软、硬件资源不与其他组织和租户共享,而且可以完全将服务架设在私有网络中,所以可实现更高的控制性和安全性级别。
- Limited Capacity:对于私有云存储服务来说,因为其所有资源都是自拥有的,也都需要自维护,包括对存储集群进行扩容,所以从容量角度来说,为存储集群进行扩容,显性和隐性成本都很高,因此,从用户角度出发,私有云存储服务并不是***容量的。
- High Cost:如前面说的,在私有云存储服务中,所有的软、硬件资源成本,存储集群的运维成本,包括数据中心的搭建、运营,私有网络甚至是专线网络的搭建,集群的维护等等,这些都是需要被纳入到私有云存储服务的成本中的。除此之外,不像公有云存储可以按需分配容量,需要多少用多少,在私有云存储中,为了满足以后的一个可预期的***容量需求,以及避免频繁扩容所带来的高昂的运维成本,在集群搭建时,往往都会以一个规划容量进行搭建,这实际上就导致了整个存储集群的使用容量会长期处于一个不饱和状态,即部分存储资源会长期出于一个空闲状态。以上两方面,就导致了私有云存储相较于公有云存储成本较高的问题。
混合云存储
混合云存储,即是将私有云存储与公有云存储打通,使得两者相结合,共同对外提供存储服务,可以说是私有云存储和公有云存储所有优点的集大成者。
- High Performance :活动数据存储在私有云存储中,归档数据存储到公有云存储中。首先从性能角度来说,通过将活动数据、会被频繁访问到的数据存储在私有云存储中,可以保证混合云存储可以提供一个较高的访问性能;
- High Security and Controllability:因为混合云存储中的私有云部分的软、硬件资源都是自拥有和独享的,所以将重要、敏感的数据信息保存在私有云存储中,可以实现更高的可控制性和安全性;
- Unlimited Capacity:因为与公有云存储的互通,借由公有云存储***容量的特性,混合云存储也具备了***容量的特性;
- Relatively Low Cost:可以选择将一些归档数据、不常访问的数据以及访问性能要求不高的数据存储到公有云存储中,在节省了私有云存储部分的成本的同时,还能拥有公有云存储按需分配的成本优势,因此混合云存储相较于私有云存储,也具有低成本的优势。
现有解决方案的局限性
混合云存储相较于公有云存储和私有云存储会更加全面,更加完善。Ceph 的对象存储针对混合云的场景,也相应的提供了解决方案,即云同步Cloud Sync 功能。Ceph RGW 的Cloud Sync 功能是基于RGW Multisite 机制实现的,先看下RGW Multisite 机制。
RGW Multisite
Ceph RGW 的 Multisite 机制用于实现多个Ceph 对象存储集群间数据同步,其涉及到的核心概念包括:
- zone:对应于一个独立的集群,由一组 RGW 对外提供服务。
- zonegroup:顾名思义,每个 zonegroup 可以对应多个zone,zone 之间同步数据和元数据。
- realm:每个realm都是独立的命名空间,可以包含多个 zonegroup,zonegroup 之间同步元数据。
Multisite 的工作机制如下:
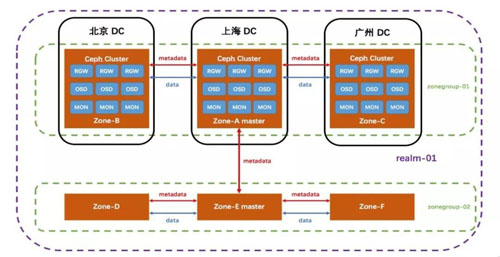
因为Multisite 是一个zone 层面的功能处理机制,所以默认情况下,是zone 级的数据同步,即配置了Multisite 之后,整个zone 当中的数据都会被进行同步处理。
整个zone 层面的数据同步,操作粒度过于粗糙,在很多场景下都是非常不适用的。当前,Ceph RGW 还支持通过 bucket syncenable/disable 来启用/禁用存储桶级的数据同步,操作粒度更细,灵活度也更高。
RGW Cloud Sync
基于RGW multisite 实现了 Cloud Sync,支持将Ceph 中的对象数据同步到支持 S3 接口的公有云存储中,默认为zone 级的数据同步。由上面的介绍可知,RGW的 Multisite 机制是用于实现多个Ceph 对象存储集群之间、多数据中心之间数据同步的。而 zone 本身是一个抽象的概念,那么从一个抽象程度更高的角度来看,它不单单可以代表一个 Ceph 对象存储集群。
RGW Cloud Sync 功能正是基于这样的思想所实现的。在 Cloud Sync 框架中,slave zone 不再仅仅对应一个 Ceph 对象存储集群,而是一个抽象程度更高的概念,即可以代表任何一个集群,而这个集群可以是 Ceph 对象存储集群,当然,也可以是AWS的S3。Cloud Sync 功能正是将支持 S3 接口的存储集群,抽象为 slave zone 的概念,然后通过Multisite 机制,实现将 Ceph 中的对象数据同步到外部对象存储中。
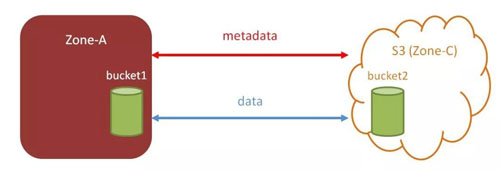
可以通过 bucket sync enable/disable启用/禁用存储桶级的数据同步 。
Cloud Sync的局限性
在使用 Ceph 对象存储时, RGW 的 Cloud Sync 功能实际上是基本可以满足混合云存储的应用场景的,但就当前 RGW Cloud Sync 功能的实现来说,还存在如下的局限性:
支持的同步粒度最细为存储桶级,在某些应用场景下,存储桶级的同步粒度是不够灵活的;时间控制,RGW Multisite 的数据同步处理是通过 RGW 自身的协程库实现的,整个处理过程是异步完成的,且数据同步处理的起始时间无法人为控制,所以这个数据同步处理的时间控制不够灵活,一些时间敏感的场景并不适用。
基于Ceph的分级混合云存储方案UMStor
有了上面这诸多局限性,我们开始考虑能否实现一种管理粒度更细、时间可控性更好的机制,来提供一种更为灵活的数据管理和迁移方案。通过对象数据存储分级、对象生命周期管理、自动生成迁移等系列实践,我们开发了一款基于Ceph的分级混合云存储解决方案UMStor。
解决方案一:对象数据存储升级
首先,我会介绍我们如何在 Ceph 对象存储中实现 Storage Class,对对象数据进行存储分级。
对存储系统分级
为什么要对存储系统进行分级?我觉得可以从如下三方面进行考虑。
1.存储介质
首先,在存储集群当中,出于对访问性能、成本等因素的考虑,我们可能会同时引入 SSD 和 HDD。在这种情况下,如果不进行存储分级,就可能会导致某些对访问性能要求不高的数据,或是归档数据,被存储在 SSD 中,而某些对访问性能要求较高的数据则被存储在了 HDD 中,这无疑会影响数据的访问性能,同时也提高了数据的存储成本。
2.存储策略
- 副本
- 副本
- Erasure Code
那有的数据对可靠性要求很高,我们才会将其以三副本的形式进行存储。可能有的数据,我们对它的可靠性要求没那么高,那我们可以考虑将其以两副本的形式进行存储,节省存储空间。
3.存储提供商
- UCloud
- AWS S3
所以说,对存储系统进行存储分级,实际上是非常必要的。
RGW 数据存放规则
本身在 RGW 中,是存在placement rule概念的,即数据的存放规则。可以在placement rule 中定义存储桶索引数据存放的存储池index pool,对象数据存放的存储池data pool,以及通过Multipart 上传大文件时临时数据存放的存储池data extra pool。
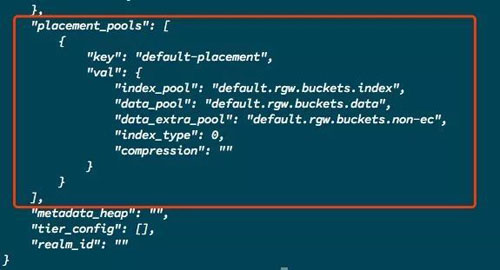
因为placement rule 是针对所使用的存储池进行定义,而存储池是位于zone 之下的概念,所以在RGW 中将placement rule 作为一个zone 级别的配置,其作用影响的粒度为存储桶级,即可以指定存储桶所使用的placement rule ,那所有上传到该存储桶中的对象数据都会按照该存储桶的placement rule 定义的存放规则进行存放。用户可以通过为不同的存储桶配置不同的placement rule 来实现将不同存储桶中的对象数据存放在不同的存储介质中或是使用不同的存储策略。
然而,存储桶级的数据存放规则,显然不够灵活,无法满足某些应用场景的需求。
对象数据存储策略
Storage Class 这一概念,本身是AWS S3 中的一个重要的特性。在S3 中,每个对象都具有 “storage-class” 这一属性,用于定义该对象数据的存储策略。在 S3 中Storage Class 特性支持如下几个预定义的存储策略:
- STANDARD针对频繁访问数据;
- STANDARD_IA用于不频繁访问但在需要时也要求快速访问的数据;
- ONEZONE_IA用于不频繁访问但在需要时也要求快速访问的数据。其他 Amazon 对象存储类将数据存储在至少三个可用区(AZ) 中,而S3 One Zone-IA 将数据存储在单个可用区中;
- REDUCED_REDUNDANCY主要是针对一些对存储可靠性要求不高的数据,通过减少数据存储的副本数,来降低存储成本;
- GLACIER。
结合上面介绍的分布式存储系统对存储分级的需求,以及当前 RGW 中所支持的data placement rule 的机制,我们在Ceph 对象存储中引入了object storage class 的概念。
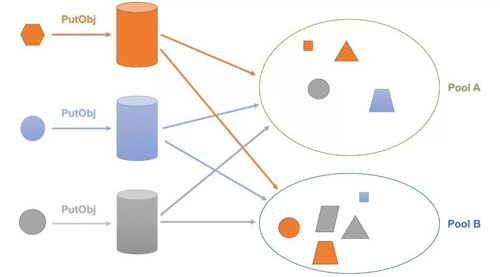
- 首先,我们对存储池的概念进行了更高程度的抽象,不仅可以按照当前 Ceph 对象存储支持,同时:可以按照不同的存储介质来划分存储池 (HDD/SSD);可以按照不同的存储策略(数据冗余策略)来划分存储池 (2x Replication/ 3x Replication/ Erasure Code);可以把外部存储 (包括外部公有云存储、私有云存储) 抽象为存储池;
- 将 RGW zone 的 placement rule 的作用范围进行了细粒度化的处理,使其作用到对象级别,实现了对象级别的存储分级, 即使是同一个存储桶中,不同的对象数据也可以保存在不同的存储池中。
解决方案二:对象生命周期管理
在实现了对象级别的 Storage Class 功能之后,我们开始考虑,如何实现数据迁移时间的可控性。这也就是下面我们要介绍的内容。
AWS S3 对象生命周期管理
对象生命周期管理也是AWS S3 中一个非常重要的特性,通过为存储桶设置生命周期管理规则,可以对存储桶中特定的对象集进行生命周期管理。当前,AWS S3 的对象生命周期管理支持:
- 迁移处理,即支持在经过指定的时间间隔后,或是到达某一特定时间点时,将存储桶中的特定对象集由当前的 storage class 存储类别迁移到另外一个指定的 storage class 存储类别中;
- 过期删除处理,即支持在经过指定的时间间隔后,或是到达某一特定时间点时,将存储桶中的特定对象集进行清除。
RGW 对象生命周期管理
当前,Ceph RGW 对象存储实际上也支持LC 对象生命周期管理。但是,因为 RGW 本身并不支持object storage class / placement rule,因此其对象生命周期管理目前只支持Expiration actions 过期删除处理。
实现完整的对象生命周期管理
基于上面实现的 Object Storage Class,在RGW 现有 LC 实现的基础上,我们对RGW LC 的处理逻辑进行了扩展,实现了LC 迁移功能,支持通过对象生命周期管理,将对象数据迁移到其他存储类别 storage class 中,例如支持从SSD 迁移到 HDD,从3 副本池迁移到 2 副本池,从副本池迁移到纠删码池,从 Ceph 集群中迁移到外部Ufile 公有云存储等等,从而实现了完整的对象生命周期管理。支持标准的 AWS S3 ObjectLifecycle Management 的相关接口。
由上面的介绍,我们实现的Storage Class 功能是支持将外部存储指定为一个存储类别的,因此,支持通过配置存储桶的LC 规则,将该存储桶中的某一特定对象集迁移到外部存储中,如UFile、S3 等等。
相较于 RGW 的Cloud Sync 功能,通过配置LC 迁移规则将Ceph 集群中的对象数据迁移到外部云存储具有如下优点:
1. 操作的粒度更细,可以直接以对象为单位,对数据进行操作;
2. 时间可控,可以通过在 LC 规则当中对操作生效的时间进行配置指定,人为控制数据迁移的时间,时间可控性更强;
至此,我们已经在Ceph 对象存储的基础上,实现了一套完整的、全粒度支持的数据迁移处理机制,从zone 级、到bucket 级、再到object 级、基本可以覆盖所有应用场景的常见需求。
解决方案三:自动生成迁移策略
存储桶日志
存储桶日志是用于记录追踪对某一特定存储桶的操作和访问的功能特性。存储桶日志的每条日志记录都记录了一次对相应存储桶的操作访问请求的细节,例如请求的发起者、存储桶名字、请求时间、请求的操作、返回的状态码等等。
自动生成迁移策略
根据存储桶日志中的操作记录、以及可配置的标尺参数,对存储桶中的对象数据的热度进行分析,并按照分析结果自动生成迁移策略,对对象数据进行管理。一张图来概要介绍下处理流程:
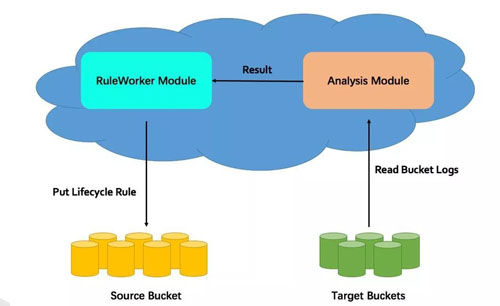
- 从target bucket 中读取存储桶日志;
- 对日记记录进行过滤、分析,得到用户配置的规则中所标定的对象数据的访问热度;
- 生成相应的生命周期管理规则;
- 将生成的生命周期管理规则配置到相应的存储桶上。
关于未来
基于Ceph对象存储的分级混合云存储方案能够很好的满足使用者的需求,但是在支持数据双向同步、代理读写等功能上还要继续完善。