生产环境上了大规模容器集群后,肯定需要对容器进行监控,容器的编排我们采用了Kubernetes,监控前期采用了Weave Scope,后期采用了cAdvisor+Heapster+InfluxDB的方案,刚开始监控感觉并没有什么异常,但是集群运行久了之后,发现监控的指标和预想的并不一样。
我们有对应的Java应用跑在容器中,每个Container的资源限制了4C16G(看起来和虚机一样夸张),JVM设置了Xmx2G的限制,但是发现有些容器的内存使用率一直在16G左,完全没有释放出来。Weave Scope和Heapster监控采集到的指标都是一样的,但是实际登录容器后发现JVM才用了800M不到。Weave Scope上其实可看到container和container内process的内存消耗,这个和实际登录容器看到的是一样的结果,如下图(剩余的那些sleep等进程其实占内存很少,忽略不计)
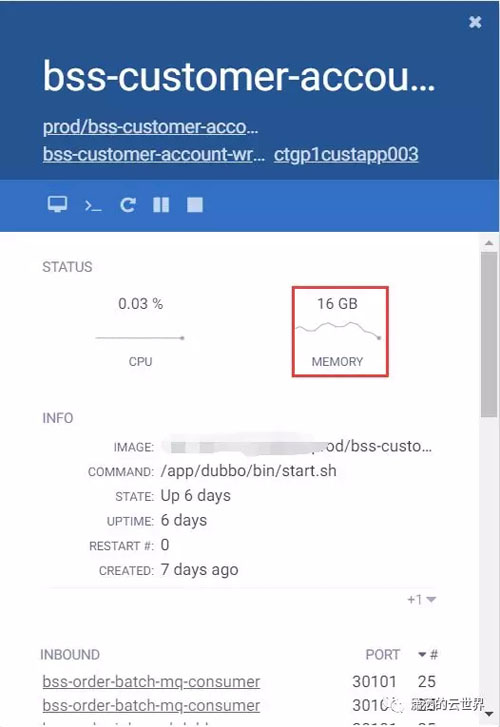
我们可以用docker stats查看对应容器的资源消耗,看到内存使用率在16G左,如下图

其实容器内部就是Linux对于内存的计算方式,我Baidu了一下发现Linux和Docker对于容器内存的计算是有差异的,Linux中buffer/cache是不计算进used memory的,所以下图中total=free+used+buff/cache,free命令的数据来源于/proc/meminfo

Docker本身的内存要通过cgroup文件中相关数据计算,我们进入对应容器的cgroup目录中,我们的容器以Pod为最小单位运行在Kubernetes环境中,所以路径在/sys/fs/cgroup/memory/kubepods下,后面跟着Pod的***标识和container的***标志
- /sys/fs/cgroup/memory/kubepods/pod2534673f-68bd-11e8-9fff-325ce3dddf77/245ac9f74c34b666ba14fadab30ef51c0f6259324b4b2f100e9b6b732b4c0933
在该目录中有一个memory.limit_in_bytes文件,这个就是Kubernetes的YAML文件通过resource.limit将值传递给Docker API下发的内存限制,cat查看为17179869184,单位Byte,转换后刚好为16G;然后我们看到有一个memory.usage_in_bytes,为当前容器的内存使用量,cat查看为17179824128,转换后15.9999G,Docker的原生监控,就是我们在用的这些Weave Scope和Heapster其实都是查询这个memory.usage_in_bytes的值;那么我们怎么推算出实际容器中应用消耗的内存总量呢,我们需要查看该目录下的memory.stat文件,cat看到如下内容
- [root@docker 245ac9f74c34b666ba14fadab30ef51c0f6259324b4b2f100e9b6b732b4c0933]# cat memory.stat
- cache 15749447680
- rss 817262592
- rss_huge 715128832
- mapped_file 3653632
- swap 0
- pgpgin 59308038
- pgpgout 55485716
- pgfault 97852409
- pgmajfault 1048
- inactive_anon 0
- active_anon 817238016
- inactive_file 7932751872
- active_file 7816630272
- unevictable 0
- hierarchical_memory_limit 17179869184
- hierarchical_memsw_limit 34359738368
- total_cache 15749447680
- total_rss 817262592
- total_rss_huge 715128832
- total_mapped_file 3653632
- total_swap 0
- total_pgpgin 59308038
- total_pgpgout 55485716
- total_pgfault 97852409
- total_pgmajfault 1048
- total_inactive_anon 0
- total_active_anon 817238016
- total_inactive_file 7932751872
- total_active_file 7816630272
- total_unevictable 0
对其中常用项的解释如下表

实际Container中实际内存使用量real_used =memory.usage_in_bytes - (rss + active_file + inactive_file),但是一个resource.limit为16G的Container,JVM应用只是用了几百兆,但监控查到使用了16G,多出的15G用在哪里。我们查询了InfluxDB数据库,拉出了Pod的监控历史,发现有一个时间点,内存使用率从16G一下子掉到了11G,并且在1分钟后上升到了16G,此时间点通过工作记录发现是有清容器日志的操作,应用将日志通过文件的形式写在宿主机的文件系统中,我们找了测试环境尝试,将一个内存消耗为7G的Container的5G日志清掉,docker stats可以看到Container的内存使用率一下子掉到了4G,并且active_file和inactive_flie都有大幅度的下降,这里为什么清了日志内存使用率只掉到4G,因为我们还有其他的写文件日志没有清,以及Container本身输出在Stdout的json.log。这样的高内存使用率长达1周,但是我们发现并没有让容器因为OOM(Out-Of-Memory)而退出,推算出容器中的Cache其实会根据实际的内存分配量而使用,并不像程序为超额使用导致容器OOM退出。