【51CTO.com原创稿件】不知道大家有没有过这种烦恼:在电脑上看到有趣的地方,想要截个图,奈何分辨率太小,放大后看不清?保存了有趣的图片/表情包,想要用的时候竟变得模糊?每每遇到这种情况,就像一个800度近视的人,摘下眼镜,便是恐慌,有木有!Don't worry!今天就来帮你解决这一难题,还您一个高清无码的世界!
一,什么是图像超分辨率重建技术
简单的说,就是将一张(或多张)分辨率较低的图像,通过一定的技术手段,生成一张分辨率高的图像。
比如这样一张表情图片:
(图1)
分辨率是 125 x 75,图片的细节,包括***行字,从远处看,都容易看不清,如果想看的清楚,我们想到的***个办法是放大图片。
我们按像素放大这张图片:
如果我们在画图软件/word/浏览器里面调节显示比例,去看这幅图片把每个像素都放大,到400%的尺寸,但是不增加像素数目(也就是说,把一个像素 从原来1x1的宽高,显示到4x4的宽高下),显示一张图片得到的效果是这样:
(图2)
如果我们把放大400%后的图像截图,生成了一张宽高值都x4的新图,里面相应的4x4 = 16个像素,代表原来小图的一个像素,从图1生成图2(图像分辨率宽高变为4倍),就是做了一次超分辨率重建。但是,效果极差!
其实我们期待,图片放大后,图像细节(图形的边缘轮廓,字体等)能够清晰,比如下面这个样子:
(图3)
如果能从图1 生成 图3(图像分辨率宽高变为4倍),就是一次非常理想的超分辨率重建了。
二,图像超分辨率重建技术的应用
我们上面说到了一个例子,把一个分辨率低的表情图片,经过处理,变成了原始4倍宽高的新图片,这里并没有看到什么意义,但是在实际中,图像超分辨率重建技术是非常有用的。
在监控领域
我们经常看到一些影视作品中,警察在监控画面上,拉近放大看犯罪嫌疑人的脸。这个放大过程,其实并没有那么简单,很多摄像头是不具备光学变焦能力的,即使摄像头带有光学变焦能力,但是监控画面很多情况下是去看之前的录像,所以光学变焦也没用,这时通过超分辨率重建技术放大有限区域内的像素,形成清晰的图像,是非常有意义的
卫星图像等遥感领域
卫星一般离地几百km采集地面的各种图像,图像上面两个像素点,在地球上的实际距离,可能是1km(已经算是比较高分辨率)到几百km(低分辨率),将卫星图像,做超分辨率重建,将大大提升后续的处理精度
医学图像领域
医学图像的分辨率,受限于X光机、核磁共振扫描仪等设备的物理能力,通过超分辨率重建技术,增加医学图像的分辨率,将给医生诊断提供更大帮助
其它通用图像处理领域
- (低分辨率)老照片,老图像重建
- 低分辨率)视频重建
- 图像压缩传输
传输时采取低分辨率视频,显示时通过超分辨率重建显示原始分辨率
三,传统的图像超分辨率重建技术简介
基于插值的技术
什么是插值?给个小白版本的解释,我们用一张非常小的图来说明:一张图像的分辨率 3 x 2,我们要把它变成 6 x 4
原图每个像素点的亮度值是:

我们建立一个6 x 4的图像,把这6个已经知道的点,放在他们大概应该在新图的位置:
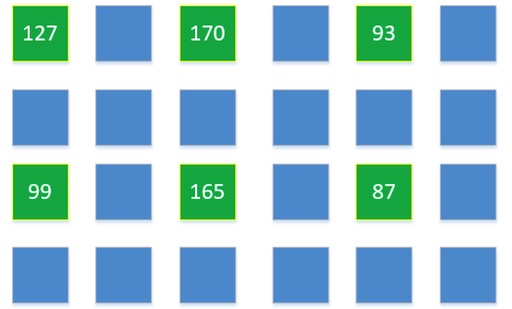
已经知道6x4新图中6个已知的点(绿色),下面需要求剩余18个点(蓝色)的值。
通过某个点周围若干个已知点的值,以及周围点和此点的位置关系,根据一定的公式,算出此点的值,就是插值法。
如何把原图像的点摆放在新图中(确定具体坐标);未知的点计算时,需要周围多少个点参与,公式如何。不同的方案选择,就是不同的插值算法。图像处理中,常用的插值算法有:最邻近元法,双线性内插法,三次内插法等等。
但是实际上,通过这些插值算法,提升的图像细节有限,所以使用较少。通常,通过多幅图像之间的插值算法来重建是一个手段。另外,在视频超分辨重建中,通过在两个相邻帧间插值添加新帧的手段,可以提升视频帧率,减少画面顿挫感。
基于重建的方法
以下都是一些传统的基于重建超分辨率算法,涉及到概率论,集合论等相关领域,这里只列出,不做介绍:
- 凸集投影法(POCS)
- 贝叶斯分析方法
- 迭代反投影法(IBP)
- ***后验概率方法
- 正规化法
- 混合方法
基于重建的方法通常基于多帧图像,需要结合先验知识(通常为平滑性)。
基于学习的方法(非深度学习)
以下为传统的基于学习的超分辨率方法,这里只列出,不做介绍:
- Example-based方法
- 邻域嵌入方法
- 支持向量回归方法
- 虚幻脸
- 稀疏表示法
这些方法,都属于机器学习领域,但是没有使用深度学习方法。
四,基于深度学习的图像超分辨率重建技术
深度学习介绍
深度学习是机器学习的一个分支,所以首先介绍下机器学习:
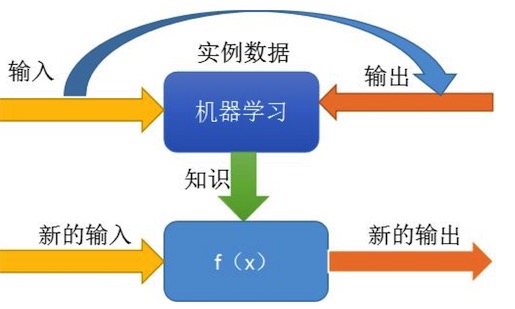
我们给机器(计算机上的程序)已知的输入、输出,让它去找规律出来(知识发现),然后我们让它根据找到的规律,用新的输入算出新的输出来,并对这个输出结果做评价,如果合适就正向鼓励,如果结果不合适,就告诉机器这样不对,让它重新找规律。
其实这个过程在模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习的本质就是让机器根据已有的数据,去分析出一个模型来表示隐藏在这些数据背后的规律(函数)。深度学习就是利用人工神经网络模型进行机器学习的方法。
人工神经网络是,人为的构造出一些处理节点(模拟脑神经元),每个节点有个函数,处理几个输入,生成若干输出,每个节点与其它节点组合,综合成一个模型(函数)。
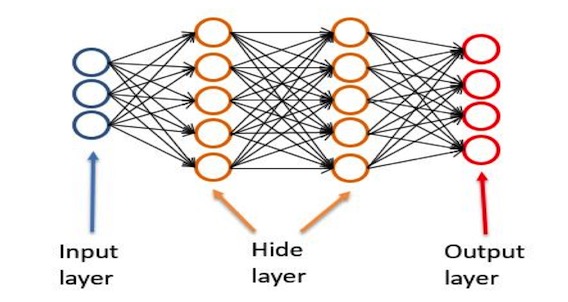
从左到右分别是输出层, 隐藏层,输出层。输入层负责接受输入,输出层负责输出结果,隐藏层负责中间的计算过程。
隐藏层的每一个节点,就是一个处理函数。隐藏层的结构,也就是层数,节点数,还有每个节点的函数将决定整个神经网络的处理结果。
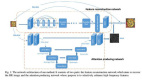
通过深度学习进行图像超分辨率重建的原理
既然深度学习可以通过数据加训练找到一个模型,去描述其背后的规律,那么我们就把它应用在图像超分辨率重建领域来。
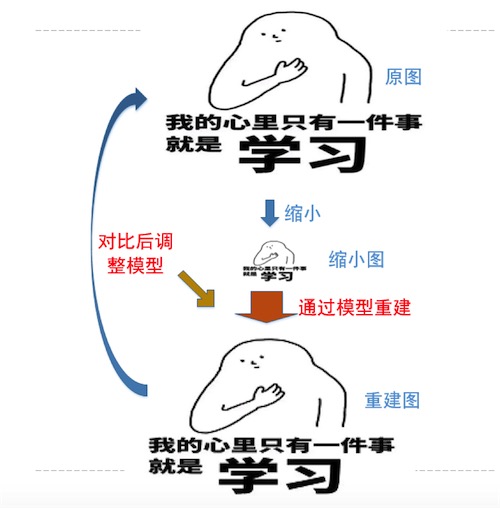
过程如下:
- 首先我们找到一组原始图像P1;
- 将这组图片降低分辨率为一组图像P2;
- 通过人工神经网络,将P2超分辨率重建为P3(P3和P1分辨率一样)
- 通过PSNR等方法比较P1与P3,验证超分辨率重建的效果,根据效果调节人工神经网络中的节点模型和参数
- 反复执行,直到第四步比较的结果满意
过程如下图:
对于神经网络模型选择、参数选择的不同,形成不同的方案,下面将分别进行简单介绍。
基于深度学习进行图像超分辨率重建的方案
基于深度学习的方案目前有很多种,这里列出部分,并对其中***个和***一个稍作介绍,感兴趣的同学可以自行搜索详细介绍、代码、相关训练集,也可使用自己生成的训练集。
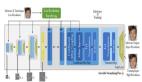
SRCNN
(Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014)
SRCNN是深度学习用在超分辨率重建上的开山之作。SRCNN的网络结构非常简单,仅仅用了三个卷积层,网络结构如下图所示。
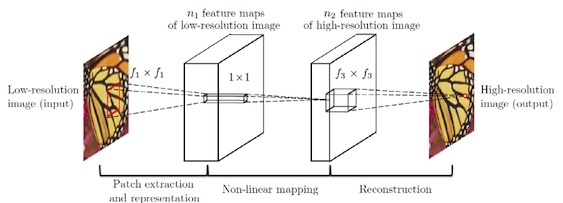
SRCNN首先使用双三次(bicubic)插值将低分辨率图像放大成目标尺寸,接着通过三层卷积网络拟合非线性映射,***输出高分辨率图像结果。作者将三层卷积的结构解释成三个步骤:图像块的提取和特征表示,特征非线性映射和最终的重建。
三个卷积层使用的卷积核的大小分为为9x9,,1x1和5x5,前两个的输出特征个数分别为64和32。用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练。使用均方误差(Mean Squared Error, MSE)作为损失函数,有利于获得较高的PSNR。
FSRCNN
(Accelerating the Super-Resolution Convolutional Neural Network, ECCV2016)
ESPCN
(Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, CVPR2016)
VDSR
(Accurate Image Super-Resolution Using Very Deep Convolutional Networks, CVPR2016)
DRCN
(Deeply-Recursive Convolutional Network for Image Super-Resolution, CVPR2016)
RED
(Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections, NIPS2016)
DRRN
(Image Super-Resolution via Deep Recursive Residual Network, CVPR2017)
LapSRN
(Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution, CVPR2017)
SRDenseNet
(Image Super-Resolution Using Dense Skip Connections, ICCV2017)
DenseNet是CVPR2017的best papaer获奖论文
SRGAN(SRResNet)
(Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, CVPR2017)
在这篇文章中,将生成对抗网络(Generative Adversarial Network, GAN)用在了解决超分辨率问题上
EDSR
(Enhanced Deep Residual Networks for Single Image Super-Resolution, CVPRW2017)
EDSR是NTIRE2017超分辨率挑战赛上获得冠军的方案。如论文中所说,EDSR最有意义的模型性能提升是去除掉了SRResNet多余的模块,从而可以扩大模型的尺寸来提升结果质量。EDSR的网络结构如下图所示。
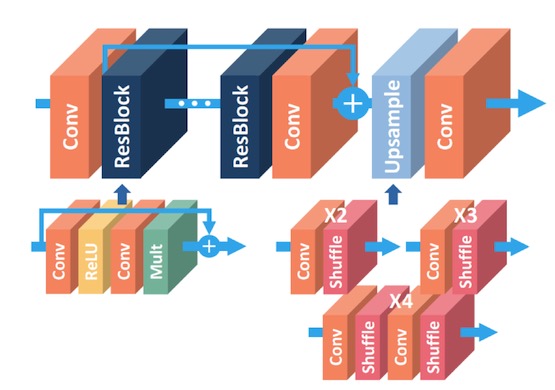
可以看到,EDSR在结构上与SRResNet相比,就是把批规范化处理(batch normalization, BN)操作给去掉了。文章中说,原始的ResNet最一开始是被提出来解决高层的计算机视觉问题,比如分类和检测,直接把ResNet的结构应用到像超分辨率这样的低层计算机视觉问题,显然不是***的。由于批规范化层消耗了与它前面的卷积层相同大小的内存,在去掉这一步操作后,相同的计算资源下,EDSR就可以堆叠更多的网络层或者使每层提取更多的特征,从而得到更好的性能表现。EDSR用L1范数样式的损失函数来优化网络模型。在训练时先训练低倍数的上采样模型,接着用训练低倍数上采样模型得到的参数来初始化高倍数的上采样模型,这样能减少高倍数上采样模型的训练时间,同时训练结果也更好。
【作者简介】曾小伟,现任PP云技术副总监,图像编解码、高性能计算出身,辅修AI(NLP方向),10年以上流媒体服务端开发及架构设计经验。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】