












【51CTO.com原创稿件】当一张图片显示在眼前时,我们的大脑会马上会识别出图片里面所含的对象。另一方面,我们需要花费大量的时间和训练数据才能让机器识别这些对象。
不过鉴于硬件和深度学习方面最近的进步,这个计算机视觉领域变得容易和直观了许多。
以下面这张图片为例,该系统能够识别图片中的不同对象,准确度极高。

图 1
现在对象检测技术在各行各业已迅速得到了采用。它帮助自动驾驶汽车安全地行驶,在拥挤的场所发现暴力行为,协助球队分析和制作选秀报告,确保制造零件得到适当的质量控制,不一而足。
这些仅仅是对象探测技术强大功能的几个应用!在本文中我们将了解对象检测是什么,看看可用来在该领域解决问题的几种不同方法。
然后我们将深入研究使用 Python 构建我们自己的对象检测系统。看完本文后,你将掌握足够的知识,克服不同的对象检测难题!
注意:本教程假设你了解了深度学习的基础知识,之前已解决了简单的图像处理问题。
如果你还没有或需要恶补一下,建议先阅读下列文章:
- 《深度学习的基础:从人工神经网络开始》
- 《面向计算机视觉的深度学习:卷积神经网络简介》
- 《教程:使用Keras优化神经网络(附有图像识别案例研究)》
对象检测是什么?
在我们开始构建最先进的模型之前,先了解一下对象检测是什么。我们不妨假设为自动驾驶汽车构建一个行人检测系统。
假设你开的汽车捕捉到如下图这样的图像,你会如何描述这个图像?

图 2
该图像实际上描绘了我们的汽车驶近广场,几个人在我们的车前方横过马路。
由于交通标志看不清楚,汽车的行人检测系统应准确识别人们行走的位置,以便能避开他们。
那么,汽车的系统该怎样确保避免行人呢?它能做的就是用边界框将这些人圈出来,那样系统就能准确识别图像中行人的位置,然后相应地决定走哪条路,以免发生任何意外。

图 3
我们做对象检测有两方面的目标:
- 识别图像中的所有对象及其位置
- 过滤掉关注的对象
解决对象检测问题的不同方法
我们已知道陈述的问题是什么,那么可以用哪种方法(或哪几种方法)来解决问题呢?
在本节中我们将介绍可用于检测图像中对象的几种技术。先从最简单的方法开始介绍,然后逐渐深入。
方法 1:朴素方法(分治法)
我们可以采取的最简单方法就是将图像分解成四个部分:

图 4:左上角

图 5:右上角

图 6:左下角

图 7:右下角
下一步是将这每一个部分都馈送给图像分类器。其输出结果就是图像的某部分有没有行人。如果有行人,就在原始图像中标记这个图像块(patch)。
输出结果会像这样:

图 8
这是值得先试一下的好方法,但我们寻求的是一种准确性和精确性极高的系统。
它需要识别整个对象(或本文中的行人),因为仅仅定位对象的某些部分可能导致灾难性的结果。
方法 2:增加分解数量
前一个系统做得很好,但我们还能做些什么?我们可以大幅增加输入到系统的图像块的数量,以此改进该系统。
输出结果应该是这样:

图 9
最终这有利也有弊。当然,我们的解决方案看起来比朴素方法好一点,但存在太多大同小异的边界框。这是个问题,我们需要一种更结构化的方法来解决问题。
方法 3:执行结构化分解
为了以一种更结构化的方式构建对象检测系统,我们可以遵照下列步骤:
第 1 步:将图像分解成 10x10 网格,如下图所示:

图 10
第 2 步:为每个图像块定义质心(centroid)。
第 3 步:对于每个质心,取高度和纵横比不一的三个不同的图像块,如下图所示:
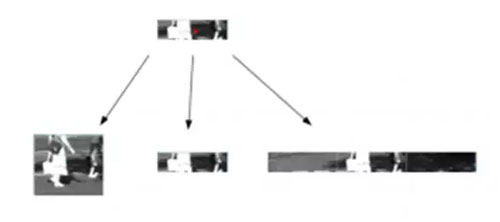
图 11
第 4 步:让创建的所有图像块过一遍图像分类器,进行预测。
那么最终的输出结果怎样?当然更结构化一点、更规范化一点,请看下面:

图 12
但我们可以进一步改进这方面!下面介绍获得更好结果的另一种方法。
方法 4:提高效率
我们看到的前一种方法在很大程度上可以接受,但我们可以构建比它更高效一点的系统。
对此你有何建议?我首先想到的就是优化。如果我们考虑采用方法 3,可以做两件事来改善模型。
增加网格大小
我们可以将网格大小增加到 20,而不是选择 10。

图 13
使用高度和纵横比不一的更多图像块,而不是三个图像块
在这里,我们可以让一个锚点(anchor)对应 9 个图像块,即 3 个高度不一的方形图像块和 6 个高度不一的垂直和水平矩形图像块。这将给我们带来纵横比不一的图像块。
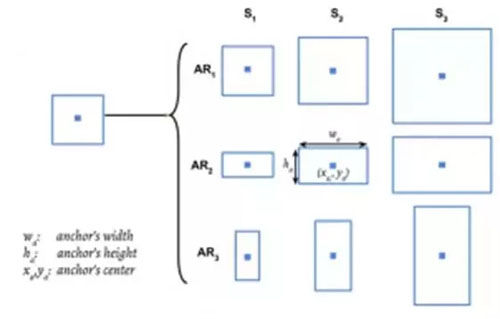
图 14
这同样有其优缺点。当然,这两种方法都可以帮助我们更精细化。但它会再次生成不得不过一遍图像分类器模型的众多图像块。
我们能做的是,取用选择性的图像块,而不是取用所有图像块。比如我们可以构建一个中间分类器,试着预测某图像块实际上有没有背景,即可能含有一个对象。这将大大减少图像分类器模型所看到的图像块。
我们能做的另一种优化就是减少表明“同一结果”的预测。不妨再以方法 3 的输出结果为例:

图 15
如你所见,两个边界框预测基本上是同一个人。我们可以选择其中任何一个。
所以为了做预测,我们考虑“表明同一结果”的所有边界框,然后选择最有可能检测到人的那个边界框。
到目前为止,所有这些优化都给了我们效果相当不错的预测。我们几乎稳操胜券,但你猜到少了什么吗?当然是少了深度学习!
方法 5:使用深度学习
使用深度学习用于特征选择并构建端到端方法,深度学习在对象检测领域大有潜力。我们可以在哪里利用深度学习来解决我们的问题?如何利用?
我在下面列出了几种方法:
- 我们可以让原始图像过一遍神经网络以减少维数,而不是取用来自原始图像的图像块。
- 我们还可以使用神经网络来建议选择性的图像块。
- 我们可以强化深度学习算法,让预测尽可能接近原始边界框。这将确保算法给出更严谨、更精细的边界框预测。
现在我们可以采用单个深度神经网络模型来尝试自行解决所有问题,而不是训练不同的神经网络来解决每一个问题。
这么做的优点是,神经网络每个较小的部分将有助于优化同一个神经网络的其他部分。这将帮助我们共同训练整个深度模型。
输出结果将带来目前为止我们看到的所有方法中最佳的性能,有点类似于下图。我们在下一节将看到如何使用 Python 来构建这个模型。

图 16
如何使用 ImageAI 库构建对象检测模型?
我们已知道了对象检测是什么、解决这个问题的最佳方法,现在不妨构建自己的对象检测系统!
我们将使用 ImageAI(https://github.com/OlafenwaMoses/ImageAI),这个 Python 库支持面向计算机视觉任务的最先进的机器学习算法。
运行对象检测模型来获得预测很简单。我们不必操心复杂的安装脚本即可入手,甚至不需要 GPU 来生成预测!我们将使用这个 ImageAI 库来获得在上面方法 5 中看到的输出预测。
强烈建议你遵循下面的代码(在你自己的机器上),因为这让你能够从本节获得尽可能多的知识。
请注意,你在构建对象检测模型之前需要设置好系统。一旦你在本地系统中安装了 Anaconda,就可以开始执行下列步骤。
第 1 步:使用 Python 版本 3.6 创建 Anaconda 环境。
conda create -n retinanet python=3.6 anaconda
- 1.
第 2 步:激活该环境,安装必要的程序包。
source activate retinanet
conda install tensorflow numpy scipy opencv pillow matplotlib h5py keras
- 1.
- 2.
第 3 步:随后安装 ImageAI 库。
pip install https://github.com/OlafenwaMoses/ImageAI/releases/download/2.0.1/imageai-2.0.1-py3-none-any.whl
- 1.
第 4 步:现在下载生成预测所需要的预训练模型。该模型基于 RetinaNet。
点击链接即可下载:RetinaNet 预训练模型(https://github.com/OlafenwaMoses/ImageAI/releases/download/1.0/resnet50_coco_best_v2.0.1.h5)。
第 5 步:将下载的文件复制到当前的工作文件夹。
第6 步:从该链接(https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2018/06/I1_2009_09_08_drive_0012_001351-768x223.png)下载图像,将图像命名为 image.png。
第 7 步:打开 jupyter 笔记本(在终端中输入 jupyter notebook),运行下列代码:
from imageai.Detection import ObjectDetection
import os
execution_path = os.getcwd()
detector = ObjectDetection()
detector.setModelTypeAsRetinaNet()
detector.setModelPath( os.path.join(execution_path , "resnet50_coco_best_v2.0.1.h5"))
detector.loadModel()
custom_objects = detector.CustomObjects(person=True, car=False)
detections = detector.detectCustomObjectsFromImage(input_image=os.path.join(execution_path , "image.png"), output_image_path=os.path.join(execution_path , "image_new.png"), custom_objects=custom_objects, minimum_percentage_probability=65)
for eachObject in detections:
print(eachObject["name"] + " : " + eachObject["percentage_probability"] )
print("--------------------------------")
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
这将创建一个名为 image_new.png 的修改后的图像文件,文件含有图像的边界框。
第 8 步:想打印输出图像,请使用下列代码:
fromIPython.display import Image
Image("image_new.png")
- 1.
- 2.

恭喜!你已自行构建了检测行人的对象检测模型。瞧瞧有多棒?
结束语
在本文中我们了解了对象检测是什么以及构建对象检测模型背后的机理。我们还了解了如何使用 ImageAI 库来构建检测行人的这个对象检测模型。
只要稍稍改一下代码,你就很容易改变模型,克服自己的对象检测难题。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】





















{kind=link}