高并发也算是这几年的热门词汇了,尤其在互联网圈,开口不聊个高并发问题,都不好意思出门。高并发有那么邪乎吗?动不动就千万并发、亿级流量,听上去的确挺吓人。但仔细想想,这么大的并发与流量不都是通过路由器来的吗?
一、一切源自网卡
高并发的流量通过低调的路由器进入我们系统,第一道关卡就是网卡,网卡怎么抗住高并发?这个问题压根就不存在,千万并发在网卡看来,一样一样的,都是电信号,网卡眼里根本区分不出来你是千万并发还是一股洪流,所以衡量网卡牛不牛都说带宽,从来没有并发量的说法。
网卡位于物理层和链路层,最终把数据传递给网络层(IP层),在网络层有了IP地址,已经可以识别出你是千万并发了,所以搞网络层的可以自豪的说,我解决了高并发问题,可以出来吹吹牛了。谁没事搞网络层呢?主角就是路由器,这玩意主要就是玩儿网络层。
二、一头雾水
非专业的我们,一般都把网络层(IP层)和传输层(TCP层)放到一起,操作系统提供,对我们是透明的,很低调、很靠谱,以至于我们都把他忽略了。
吹过的牛是从应用层开始的,应用层一切都源于Socket,那些千万并发最终会经过传输层变成千万个Socket,那些吹过的牛,不过就是如何快速处理这些Socket。处理IP层数据和处理Socket究竟有啥不同呢?
三、没有连接,就没用等待
最重要的一个不同就是IP层不是面向连接的,而Socket是面向连接的,IP层没有连接的概念,在IP层,来一个数据包就处理一个,不用瞻前也不用顾后;而处理Socket,必须瞻前顾后,Socket是面向连接的,有上下文的,读到一句我爱你,激动半天,你不前前后后地看看,就是瞎激动了。
你想前前后后地看明白,就要占用更多的内存去记忆,就要占用更长的时间去等待;不同连接要搞好隔离,就要分配不同的线程(或者协程)。所有这些都解决好,貌似还是有点难度的。
四、感谢操作系统
操作系统是个好东西,在Linux系统上,所有的IO都被抽象成了文件,网络IO也不例外,被抽象成Socket,但是Socket还不仅是一个IO的抽象,它同时还抽象了如何处理Socket,最著名的就是select和epoll了,知名的nginx、netty、redis都是基于epoll搞的,这仨家伙基本上是在千万并发领域必备神技。
但是多年前,Linux只提供了select的,这种模式能处理的并发量非常小,而epoll是专为高并发而生的,感谢操作系统。不过操作系统没有解决高并发的所有问题,只是让数据快速地从网卡流入我们的应用程序,如何处理才是老大难。
操作系统的使命之一就是最大限度的发挥硬件的能力,解决高并发问题,这也是最直接、最有效的方案,其次才是分布式计算。前面我们提到的nginx、netty、redis都是最大限度发挥硬件能力的典范。如何才能最大限度的发挥硬件能力呢?
五、核心矛盾
要最大限度的发挥硬件能力,首先要找到核心矛盾所在。我认为,这个核心矛盾从计算机诞生之初直到现在,几乎没有发生变化,就是CPU和IO之间的矛盾。
CPU以摩尔定律的速度野蛮发展,而IO设备(磁盘,网卡)却乏善可陈。龟速的IO设备成为性能瓶颈,必然导致CPU的利用率很低,所以提升CPU利用率几乎成了发挥硬件能力的代名词。
六、中断与缓存
CPU与IO设备的协作基本都是以中断的方式进行的,例如读磁盘的操作,CPU仅仅是发一条读磁盘到内存的指令给磁盘驱动,之后就立即返回了,此时CPU可以接着干其他事情,读磁盘到内存本身是个很耗时的工作,等磁盘驱动执行完指令,会发个中断请求给CPU,告诉CPU任务已经完成,CPU处理中断请求,此时CPU可以直接操作读到内存的数据。
中断机制让CPU以最小的代价处理IO问题,那如何提高设备的利用率呢?答案就是缓存。
操作系统内部维护了IO设备数据的缓存,包括读缓存和写缓存,读缓存很容易理解,我们经常在应用层使用缓存,目的就是尽量避免产生读IO。
写缓存应用层使用的不多,操作系统的写缓存,完全是为了提高IO写的效率。操作系统在写IO的时候会对缓存进行合并和调度,例如写磁盘会用到电梯调度算法。
七、高效利用网卡
高并发问题首先要解决的是如何高效利用网卡。网卡和磁盘一样,内部也是有缓存的,网卡接收网络数据,先存放到网卡缓存,然后写入操作系统的内核空间(内存),我们的应用程序则读取内存中的数据,然后处理。
除了网卡有缓存外,TCP/IP协议内部还有发送缓冲区和接收缓冲区以及SYN积压队列、accept积压队列。
这些缓存,如果配置不合适,则会出现各种问题。例如在TCP建立连接阶段,如果并发量过大,而nginx里面socket的backlog设置的值太小,就会导致大量连接请求失败。
如果网卡的缓存太小,当缓存满了后,网卡会直接把新接收的数据丢掉,造成丢包。当然如果我们的应用读取网络IO数据的效率不高,会加速网卡缓存数据的堆积。如何高效读取网络数据呢?目前在Linux上广泛应用的就是epoll了。
操作系统把IO设备抽象为文件,网络被抽象成了Socket,Socket本身也是一个文件,所以可以用read/write方法来读取和发送网络数据。在高并发场景下,如何高效利用Socket快速读取和发送网络数据呢?
要想高效利用IO,就必须在操作系统层面了解IO模型,在《UNIX网络编程》这本经典著作里,总结了五种IO模型,分别是阻塞式IO,非阻塞式IO,多路复用IO,信号驱动IO和异步IO。
八、阻塞式IO
我们以读操作为例,当我们调用read方法读取Socket上的数据时,如果此时Socket读缓存是空的(没有数据从Socket的另一端发过来),操作系统会把调用read方法的线程挂起,直到Socket读缓存里有数据时,操作系统再把该线程唤醒。
当然,在唤醒的同时,read方法也返回了数据。我理解所谓的阻塞,就是操作系统是否会挂起线程。
九、非阻塞式IO
而对于非阻塞式IO,如果Socket的读缓存是空的,操作系统并不会把调用read方法的线程挂起,而是立即返回一个EAGAIN的错误码,在这种情景下,可以轮询read方法,直到Socket的读缓存有数据则可以读到数据,这种方式的缺点非常明显,就是消耗大量的CPU。
十、多路复用IO
对于阻塞式IO,由于操作系统会挂起调用线程,所以如果想同时处理多个Socket,就必须相应地创建多个线程,线程会消耗内存,增加操作系统进行线程切换的负载,所以这种模式不适合高并发场景。有没有办法较少线程数呢?
非阻塞IO貌似可以解决,在一个线程里轮询多个Socket,看上去可以解决线程数的问题,但实际上这个方案是无效的,原因是调用read方法是一个系统调用,系统调用是通过软中断实现的,会导致进行用户态和内核态的切换,所以很慢。
但是这个思路是对的,有没有办法避免系统调用呢?有,就是多路复用IO。
在Linux系统上select/epoll这俩系统API支持多路复用IO,通过这两个API,一个系统调用可以监控多个Socket,只要有一个Socket的读缓存有数据了,方法就立即返回,然后你就可以去读这个可读的Socket了,如果所有的Socket读缓存都是空的,则会阻塞,也就是将调用select/epoll的线程挂起。
所以select/epoll本质上也是阻塞式IO,只不过他们可以同时监控多个Socket。
1. select和epoll的区别
为什么多路复用IO模型有两个系统API?我分析原因是,select是POSIX标准中定义的,但是性能不够好,所以各个操作系统都推出了性能更好的API,如Linux上的epoll、Windows上的IOCP。
至于select为什么会慢,大家比较认可的原因有两点,一点是select方法返回后,需要遍历所有监控的Socket,而不是发生变化的Ssocket,还有一点是每次调用select方法,都需要在用户态和内核态拷贝文件描述符的位图(通过调用三次copy_from_user方法拷贝读、写、异常三个位图)。epoll可以避免上面提到的这两点。
2. Reactor多线程模型
在Linux操作系统上,性能最为可靠、稳定的IO模式就是多路复用,我们的应用如何能够利用好多路复用IO呢?经过前人多年实践总结,搞了一个Reactor模式,目前应用非常广泛,著名的Netty、Tomcat NIO就是基于这个模式。
Reactor的核心是事件分发器和事件处理器,事件分发器是连接多路复用IO和网络数据处理的中枢,核心就是监听Socket事件(select/epoll_wait),然后将事件分发给事件处理器,事件分发器和事件处理器都可以基于线程池来做。
需要重点提一下的是,在Socket事件中主要有两大类事件,一个是连接请求,另一个是读写请求,连接请求成功处理之后会创建新的Socket,读写请求都是基于这个新创建的Socket。
所以在网络处理场景中,实现Reactor模式会稍微有点绕,但是原理没有变化。具体实现可以参考Doug Lea的《Scalable IO in Java》(http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf)
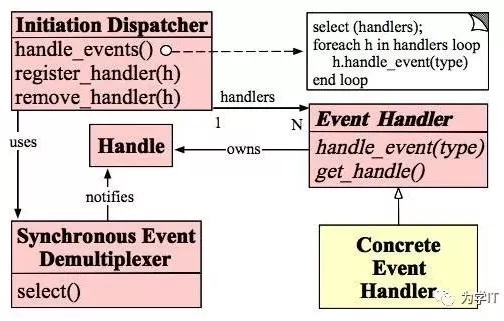
Reactor原理图
3. Nginx多进程模型
Nginx默认采用的是多进程模型,Nginx分为Master进程和Worker进程,真正负责监听网络请求并处理请求的只有Worker进程,所有的Worker进程都监听默认的80端口,但是每个请求只会被一个Worker进程处理。
这里面的玄机是:每个进程在accept请求前必须争抢一把锁,得到锁的进程才有权处理当前的网络请求。每个Worker进程只有一个主线程,单线程的好处是无锁处理,无锁处理并发请求,这基本上是高并发场景里面的最高境界了。
(参考http://www.dre.vanderbilt.edu/~schmidt/PDF/reactor-siemens.pdf)
数据经过网卡、操作系统、网络协议中间件(Tomcat、Netty等)重重关卡,终于到了我们应用开发人员手里,我们如何处理这些高并发的请求呢?我们还是先从提升单机处理能力的角度来思考这个问题。
4. 突破木桶理论
据经过网卡、操作系统、中间件(Tomcat、Netty等)重重关卡,终于到了我们应用开发人员手里,我们如何处理这些高并发的请求呢?
我们还是先从提升单机处理能力的角度来思考这个问题,在实际应用的场景中,问题的焦点是如何提高CPU的利用率(谁叫它发展的最快呢),木桶理论讲最短的那根板决定水位,那为啥不是提高短板IO的利用率,而是去提高CPU的利用率呢?
这个问题的答案是在实际应用中,提高了CPU的利用率往往会同时提高IO的利用率。当然在IO利用率已经接近极限的条件下,再提高CPU利用率是没有意义的。我们先来看看如何提高CPU的利用率,后面再看如何提高IO的利用率。
5. 并行与并发
提升CPU利用率目前主要的方法是利用CPU的多核进行并行计算,并行和并发是有区别的,在单核CPU上,我们可以一边听MP3,一边Coding,这个是并发,但不是并行,因为在单核CPU的视野,听MP3和Coding是不可能同时进行的。
只有在多核时代,才会有并行计算。并行计算这东西太高级,工业化应用的模型主要有两种,一种是共享内存模型,另外一种是消息传递模型。
6. 多线程设计模式
对于共享内存模型,其原理基本都来自大师Dijkstra在半个世纪前(1965)的一篇论文《Cooperating sequential processes》,这篇论文提出了大名鼎鼎的概念信号量,Java里面用于线程同步的wait/notify也是信号量的一种实现。
大师的东西看不懂,学不会也不用觉得丢人,毕竟大师的嫡传子弟也没几个。东洋有个叫结城浩的总结了一下多线程编程的经验,写了本书叫《JAVA多线程设计模式》,这个还是挺接地气(能看懂)的。下面简单介绍一下。
(1) Single Threaded Execution
这个模式是把多线程变成单线程,多线程在同时访问一个变量时,会发生各种莫名其妙的问题,这个设计模式直接把多线程搞成了单线程,于是安全了,当然性能也就下来了。最简单的实现就是利用synchronized将存在安全隐患的代码块(方法)保护起来。在并发领域有个临界区(criticalsections)的概念,我感觉和这个模式是一回事。
(2) Immutable Pattern
如果共享变量永远不变,那就多个线程访问就没有任何问题,永远安全。这个模式虽然简单,但是用的好,能解决很多问题。
(3) Guarded Suspension Patten
这个模式其实就是等待-通知模型,当线程执行条件不满足时,挂起当前线程(等待),当条件满足时,唤醒所有等待的线程(通知),在Java语言里利用synchronized,wait/notifyAll可以很快实现一个等待通知模型。结城浩将这个模式总结为多线程版的If,我觉得非常贴切。
(4) Balking
这个模式和上个模式类似,不同点是当线程执行条件不满足时直接退出,而不是像上个模式那样挂起。这个用法最大的应用场景是多线程版的单例模式,当对象已经创建了(不满足创建对象的条件)就不用再创建对象(退出)。
(5) Producer-Consumer
生产者-消费者模式,全世界人都知道。我接触的最多的是一个线程处理IO(如查询数据库),一个(或者多个)线程处理IO数据,这样IO和CPU就都能成分利用起来。如果生产者和消费者都是CPU密集型,再搞生产者-消费者就是自己给自己找麻烦了。
(6) Read-Write Lock
读写锁解决的读多写少场景下的性能问题,支持并行读,但是写操作只允许一个线程做。如果写操作非常非常少,而读的并发量非常非常大,这个时候可以考虑使用写时复制(copy on write)技术,我个人觉得应该单独把写时复制单独作为一个模式。
(7) Thread-Per-Message
就是我们经常提到的一请求一线程。
(8) Worker Thread
一请求一线程的升级版,利用线程池解决线程的频繁创建、销毁导致的性能问题。BIO年代Tomcat就是用的这种模式。
(9) Future
当你调用某个耗时的同步方法很心烦,想同时干点别的事情,可以考虑用这个模式,这个模式的本质是个同步变异步的转换器。同步之所以能变异步,本质上是启动了另外一个线程,所以这个模式和一请求一线程还是多少有点关系的。
(10) Two-Phase Termination
这个模式能解决优雅地终止线程的需求。
(11) Thread-Specific Storage
线程本地存储,避免加锁、解锁开销的利器,C#里面有个支持并发的容器ConcurrentBag就是采用了这个模式,这个星球上最快的数据库连接池HikariCP借鉴了ConcurrentBag的实现,搞了个Java版的,有兴趣的同学可以参考。
(12) Active Object(这个不讲也罢)
这个模式相当于降龙十八掌的最后一掌,综合了前面的设计模式,有点复杂,个人觉得借鉴的意义大于参考实现。
最近国人也出过几本相关的书,但总体还是结城浩这本更能经得住推敲。基于共享内存模型解决并发问题,主要问题就是用好锁,但是用好锁,还是有难度的,所以后来又有人搞了消息传递模型,这个后面再聊。
基于共享内存模型解决并发问题,主要问题就是用好锁,但是用好锁,还是有难度的,所以后来又有人搞了消息传递模型。
十一、消息传递模型
共享内存模型难度还是挺大的,而且你没有办法从理论上证明写的程序是正确的,我们总一不小心就会写出来个死锁的程序来,每当有了问题,总会有大师出来,于是消息传递(Message-Passing)模型横空出世(发生在上个世纪70年代),消息传递模型有两个重要的分支,一个是Actor模型,一个是CSP模型。
十二、Actor模型
Actor模型因为Erlang声名鹊起,后来又出现了Akka。在Actor模型里面,没有操作系统里所谓进程、线程的概念,一切都是Actor,我们可以把Actor想象成一个更全能、更好用的线程。
在Actor内部是线性处理(单线程)的,Actor之间以消息方式交互,也就是不允许Actor之间共享数据,没有共享,就无需用锁,这就避免了锁带来的各种副作用。
Actor的创建和new一个对象没有啥区别,很快、很小,不像线程的创建又慢又耗资源;Actor的调度也不像线程会导致操作系统上下文切换(主要是各种寄存器的保存、恢复),所以调度的消耗也很小。
Actor还有一个有点争议的优点,Actor模型更接近现实世界,现实世界也是分布式的、异步的、基于消息的、尤其Actor对于异常(失败)的处理、自愈、监控等都更符合现实世界的逻辑。
但是这个优点改变了编程的思维习惯,我们目前大部分编程思维习惯其实是和现实世界有很多差异的(这个回头再细说),一般来讲,改变我们思维习惯的事情,阻力总是超乎我们的想象。
十三、CSP模型
Golang在语言层面支持CSP模型,CSP模型和Actor模型的一个感官上的区别是在CSP模型里面,生产者(消息发送方)和消费者(消息接收方)是完全松耦合的,生产者完全不知道消费者的存在,但是在Actor模型里面,生产者必须知道消费者,否则没办法发送消息。
CSP模型类似于我们在多线程里面提到的生产者-消费者模型,核心的区别我觉得在于CSP模型里面有类似绿色线程(green thread)的东西,绿色线程在Golang里面叫做协程,协程同样是个非常轻量级的调度单元,可以快速创建而且资源占用很低。
Actor在某种程度上需要改变我们的思维方式,而CSP模型貌似没有那么大动静,更容易被现在的开发人员接受,都说Golang是工程化的语言,在Actor和CSP的选择上,也可以看到这种体现。
十四、多样世界
除了消息传递模型,还有事件驱动模型、函数式模型。事件驱动模型类似于观察者模式,在Actor模型里面,消息的生产者必须知道消费者才能发送消息,而在事件驱动模型里面,事件的消费者必须知道消息的生产者才能注册事件处理逻辑。
Akka里消费者可以跨网络,事件驱动模型的具体实现如Vertx里,消费者也可以订阅跨网络的事件,从这个角度看,大家都在取长补短。
【本文来自51CTO专栏作者张开涛的微信公众号(开涛的博客),公众号id: kaitao-1234567】