Hadoop学习系列一:环境搭建。为了学习HBase,跑过来先把Hadoop学习下。主要是根据马老师之前直播的教程来学习的。好了,废话不多说了,开搞。
一. 安装虚拟机
相比VMware,Vritual Box是免费的,因此这里采用Virtual Box。首先在virtualbox官网的下载页面下载Virtual Box,并安装。安装过程没什么好说的。

二. 在虚拟机里安装CentOS
在CentOS官网下载最新版的CentOS 7,下载的时候要DVD ISO,Minimal ISO文件虽然比较小,但不能满足我们的需求。
下载完成后,打开Virtual Box,点击“新建”,输入虚拟机的名称(我这里输入“node1”),类型选择“Linux”,因为这里下载的CentOS是64位版本,所有这里的版本要选择“Red Hat (64-bit)”,点击“下一步”。
“内存大小”先设置1G,选择“下一步”。
“虚拟硬盘”选择“现在创建虚拟硬盘”,点击“创建”。
”虚拟硬盘文件类型“默认就好,选择“下一步”。
”存储在物理硬盘上“选择“动态分配”,选择“下一步”。最后点击“创建”按钮,完成虚拟机“node1”的创建。
node1创建好后,如下图所示:

接下来安装CentOS 7系统:
右键单击虚拟机“node1”,点击“设置”-“存储”,右侧“存储介质”-“控制器:IDE”的后面,有个“添加 虚拟 光驱”按钮,如下图红色方框中:

点击该按钮后,点“选择磁盘”,然后选择之前下载好的CentOS7的ISO镜像文件后,点“OK”。
然后双击启动虚拟机"node1"。
安装过程中,“软件选择”要选择“基础设施服务器”,“安装位置”点“完成”,然后点“开始安装”就可以了。
安装过程中需要设置root用户的密码。
另外需要注意的是:如果想从Virtual Box虚拟机中切换到宿主机的话,按右边的“Ctrl”键即可。
三. 配置CentOS
系统安装好后,先配置下虚拟机的网络:
将node1虚拟机的网络中网卡连接方式设置为“仅主机(Host-Only)网络”。cmd下ipconfig命令查看Virtual Box虚拟网卡的IP地址,如下图:

我这里的IP地址为192.168.56.1,子网掩码255.255.255.0
CentOS下设置node1的IP地址为192.168.56.100,子网掩码为255.255.255.0:
- vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
- TYPE=Ethernet
- IPADDR=192.168.56.100
- NETMASK=255.255.255.0
设置node1的网关:
- vim /etc/sysconfig/network
- NETWORKING=yes
- GATEWAY=192.68.56.1
设置node1的hostname:
- hostnamectl set-hostname node1
停止防火墙并禁止开机启动:
- systemctl stop firewalld
- systemctl disable firewalld
重启网络:
- systemctl restart network
这个时候主机和虚拟机应该可以相互ping通了:
- ping 192.168.56.1

如果出现虚拟机ping不通主机,但是主机可以ping通虚拟机的情况,可以参考https://blog.csdn.net/u014594922/article/details/53426225
四. 安装java和hadoop
下载jdk和hadoop
使用xshell登陆到node1,使用xftp将jdk和hadoop复制到node1
安装jdk:
- rpm -ivh jdk-8u171-linux-x64.rpm
安装hadoop:
- tar -zxvf hadoop-2.9.1.tar.gz
配置hadoop环境变量:
- vim /etc/profile
添加下面代码:
- export PATH=$PATH:/root/hadoop-2.9.1/bin:/root/hadoop-2.9.1/sbin
使环境变量生效:
- source /etc/profile
在hadoop中指明java路径:
- vim /root/hadoop-2.9.1/etc/hadoop/hadoop-env.sh
将其中的JAVA_HOME改为/usr:
- export JAVA_HOME=/usr
五. 复制虚拟机及配置hadoop
将node1关机,复制3份,使用完全复制,命名为node2、node3、node4,并依次打开,配置IP地址分别192.168.56.101,192.168.56.102,192.168.56.103,hostname分别为node2、node3、node4
使用“无界面启动”方式用打开四个虚拟机,并用xshell创建4个对应的会话
勾选xshell的“工具”-“发送键输入到所有会话”,可以同时向4个会话发送内容
切换到4个会话的hadoop目录下:
- cd ~/hadoop-2.9.1
修改4个会话的文件,用于指明namenode:etc/hadoop/core-site.xml
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://node1:9000</value>
- </property>
- </configuration>
修改4个会话的hosts文件:
- vim /etc/hosts
- 192.168.56.100 node1
- 192.168.56.101 node2
- 192.168.56.102 node3
- 192.168.56.103 node4
在node1会话中初始化hdfs:
- hdfs namenode -format
输入y
在node1会话中开启namenode:
- hadoop-daemon.sh start namenode
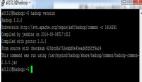
在node1会话中jps,出现NameNode说明启动成功:
- jps
- 4483 Jps
- 4404 NameNode
在node2、node3、node4会话中开启datanode:
- hadoop-daemon.sh start datanode
在node2、node3、node4会话中jps,出现DataNode说明启动成功:
- jps
- 5314 DataNode
- 5391 Jps
通过web页面查看hadoop状态
node1下查看hadoop的web页面端口:
- netstat -ntlp | grep java
- tcp 0 0 192.168.56.100:9000 0.0.0.0:* LISTEN 4491/java
- tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 4491/java
50070就是hadoop的web页面端口
浏览器打开http://192.168.56.100:50070:

可以看到Live Nodes是3,说明由node1管理的3个节点在运行中
在namenode上使用slaves文件启动datanode
其实可以直接在namenode上启动datanode,但要确保datanode上的hadoop路径与namenode上的一致,而且需要datanode配置了上一篇文章中提到的core-site.xml。在etc/hadoop/slaves中添加所有的datanode节点:
- node2
- node3
- node4
使用下列命令启动整个集群:
- start-dfs.sh
运行完成后,发现datanode也都启动了
在namenode上免密启动datanode
虽然上面通过slaves文件已经可以启动整个集群了,但是在连接每个datanode时都需要输入密码,很不方便。
到root用户的.ssh下:
- cd /root/.ssh
生成密钥对:
- ssh-keygen -t rsa
将密钥对拷贝到所有node中:
- ssh-copy-id node1
- ssh-copy-id node2
- ssh-copy-id node3
- ssh-copy-id node4
接下来,启动和结束hdfs时不需要再输入密码
hdfs的使用
使用hadoop fs或hdfs dfs可查看帮助
将文件1.txt保存到hdfs根目录下:
- hadoop fs -put ./1.txt /
查看hdfs根目录文件:
- hadoop fs -ls /
命令和linux下命令很像