












存储产业正在发生颠覆性的变化,主要有两大推手:一个是新一代存储介质SSD;另一个是分布式存储的演进,以SDS(软件定义存储)为代表。
根据IDC预计,2017年~2021年期间,全球软件定义存储市场的复合年增长率将达到13.5%,到2021年市场规模可接近162亿美元。在SDS市场中,主要细分市场为块、文件、对象和超融合基础设施(HCI)。IDC预计,SDS市场未来五年复合增长率为28.8%,超融合市场为24.7%。
应用如何过渡、迁移?
分布式存储技术首先成功应用在互联网企业的应用场景。
鉴于无法预计的互联网访问流量,互联网迫切需要一种弹性十足的IT基础架构,传统磁盘阵列以Scale Up为主,且价格昂贵,难以满足需求。对此,互联网企业不得不寻求更加具有成本竞争力的方案。
以成本优异的x86工业标准服务器为基础,通过强大的软件调度管理能力,互联网企业成功践行了分布式软件定义存储,从而开辟了以Scale Out为特征的分布式存储应用。
但是与互联网企业不同,传统企业以往多采用集中部署模式,例如存储以磁盘阵列为主,属于Scale Up模式,上层应用也是建立在这个模式基础上的。
换句话说,与互联网企业相比,传统行业企业有历史的包袱,存在兼容性的问题。此外,行业性质以及监管不同,较之互联网企业,传统行业企业用户对于可靠性、稳定性有更高的需求。
如今,云计算是产业发展的潮流和趋势,对于传统企业来说,云环境部署更加复杂。如今,有一种观点认为:OpenStack作为私有云标准大局已定。与之相适应,有观点认为,较之Sheepdog、MooseFS等开源系统,以及众多自主研发的系统,作为OpenStack认证对接的分布式存储,Ceph才是最为理想的选择。
真的是这样的吗?
有关“块”的问题
所谓OpenStack认证对接的分布式存储,并不意味Ceph就是***的选择,Ceph并不是OpenStack环境的标配,Ceph只是适逢其会。如果了解Ceph就会知道,其绝大部分核心代码都出自Inktank团队,如今已经被Redhat整体收购。它只是一种分布式存储的开源架构,并没有充分考虑企业级应用的需求。而且Ceph设计之初就定位为“分布式文件系统”,并没有关注“块设备”应用环境低延迟、高性能的特性。
换句话说:在“块设备”应用的场景,Ceph本身是不擅长的。
鹏云网络创始人陈靓博士
原AWS核心架构师、S3、Glacier存储项目团队负责人,华裔科学家陈靓先生表示:传统企业应用上云,在存储方面需要解决:
1)可用性与可靠性,这是用户最为关心的问题,当节点或磁盘故障时,业务不停,数据不丢是必须的。但限于crush机制,Ceph系统在节点当机时会造成IO中断,前端业务会受到一定影响。
2)性能。Ceph基于对象存储,IO延迟长,而传统业务系统对IO延迟比较敏感。
3)应提供丰富的企业级存储服务功能,例如,快照/克隆技术提供快速数据恢复、以及多用途数据副本等能力;在线迁移能够根据实际需求为业务系统调整存储资源配置;QoS功能在多业务系统复杂环境下充分保证关键业务系统的存储性能供给。
以上这些问题,用户都可以在产品测试过程中进行实际的验证和考察,眼见为实。
ZettaStor和原生块存储
作为原AWS核心架构师、S3、Glacier存储项目团队负责人,陈靓先生非常了解对象存储应对块数据需求的不足。
机缘巧合,2012年,陈靓应南京市政府的感召归国创业,创办了南京鹏云网络科技有限公司,并推出了从***层开始研发的ZettaStor DBS软件定义分布式存储系统,提出了原生块存储的概念。
它是以裸设备方式直接管理底层硬盘,并整合成为块存储资源供上层应用来访问使用,由于并不存在对象存储的中间转换过程,因此能够实现低延迟的高I/O访问效率。
考虑到传统企业级应用对于功能的需求,ZettaStor DBS还提供了自动精简配置、快照/克隆、分级存储、数据复制和迁移、SSD缓存加速、QoS管理、访问控制、多路径冗余等完整的功能。ZettaStor DBS所具有的机房多级容灾、故障域隔离、双活容灾解决方案可以很好满足企业级用户业务的需求。
ZettaStor DBS以标准的iSCSI/SCSI协议和私有的LBD协议对外提供存储服务,并可以通过对接Cinder API、标准REST接口,可以为OpenStack等云计算管理平台的统一管理提供技术支持!
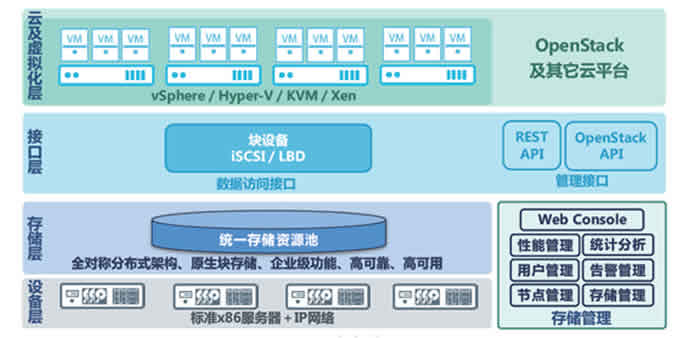
ZettaStor DBS产品架构图
测试中的 “猫腻”
谈到原生块存储,陈靓表示:其实概念并不重要。在担任AWS核心架构师期间,其内部很少谈论概念,更多是专注在要解决哪些技术问题。用户应该更加专注需要解决的问题,而不应该盲从于概念、标准或者趋势。其实,关注问题不同,着眼点也不同。
对于原生块存储、非原生块存储,测试和验证将是一个非常重要的方法。但是在测试过程中,也应该结合实际,谨防被一些“猫腻”手段所蒙蔽。
以可靠性测试为例,重点要考察的是:当集群中磁盘或节点发生故障时,数据会不会丢失?业务会不会中断?中断的时长是多少?
很多SDS的容错域都是提前配置好的。以3副本9个节点为例,通常会配置3个容错域A\B\C、每个容错域各3个节点,每个容错域保存独立的副本数据。例如当以一个容错域A的3台机器都故障时,还有两2个副本存在,数据不会丢失,业务照常运行,这就是通常所说的能容忍1/3节点宕机。这样的要求大多数厂家都能做到,但如果同时B域或者C域也有机器down机呢?
这就是测试中,用户需要仔细考察和验证的。
再以性能测试为例,SSD缓存对性能测试有很大的影响,特别在小数据量时,看不出来系统的差异,但在实际中,当数据量、负载加大,SSD存在被穿透的可能,这时数据就需要落盘(写到硬盘),这个时候良莠不齐,高低立判。这就是为什么很多以ceph为基础二次开发的系统把SSD缓存做为标配的原因,因为一旦没有SSD加速性能会变得很差。
当系统发生磁盘/节点故障,恢复数据是否会影响系统性能表现。以Ceph为例,其元数据管理和寻址采用的是Crush算法,在节点动荡时,元数据(其实是ceph内部保存的资源列表)发生变化,会导致大量的没有必要的数据迁移,不仅导致网络带宽拥挤,严重时会导致业务系统访问受影响。
小结
传统企业没有办法和互联网企业相比,无论IT管理模式,技术水平,还是发展阶段,二者完全不同。所谓橘生淮南则为橘,生于淮北则为枳,无论对于互联网企业、云计算服务商,还是对于传统企业用户,服务的对象,面临场景不同,其选择也就不同,切不可为商业化的宣传所误导!
















![[[235614]]](https://s4.51cto.com/oss/201807/06/4e638aa598282a9d94aad4b1e88499d4.jpeg){kind=link}