在各色数据库系统百花齐放的今天,能让大家铭记的,往往是一个数据库所能带给大家的差异化能力。正如梁宁老师的产品思维课程中所讲到的,这是一个数据库系统所能带给产品使用者的"确定性"。
差异化能力通常需要从数据库底层开始构筑,而数据存储方式显得至关重要,因为它直接关乎数据写入与读取的效率。在一个系统中,这两方面的能力需要进行很好的权衡:如果设计有利于数据的快速写入,可能意味着查询时需要需要花费较大的精力去组织数据,反之,如果写入时花费精力去更好的组织数据,查询就会变的非常轻松。
探讨数据库的数据存储方式,其实就是探讨数据如何在磁盘上进行有效的组织。因为我们通常以如何高效读取和消费数据为目的,而不是数据存储本身。在RDBMS领域,因为键与数据的组织方式的区别,有两种表组织结构最为常见,一种是键与数据联合存储的索引组织表结构,在这种表结构下,查到键值意味着查找到数据;另外一种是键与数据分离存储的堆表结构。在这种表结构下,查找到键以后,只是拿到了数据记录的物理地址,还需要基于该物理地址去查找具体的数据记录。在大数据分析领域,有几种通用的文件格式,如Parquet, RCFile, ORCFile,CarbonData等等,这些文件大多基于列式的设计结构,来加速通用的分析型查询。但在实时数据库领域,却以各种私有的文件格式最为常见,如Bigtable的SSTable,HBase的HFile,Kudu的DiskRowSets,Cassandra的变种SSTable,MongoDB支持的每一种Storage Engine都是私有的文件格式设计,等等。
本文将详细探讨HBase的HFile设计,第一部分为HFile原理概述,第二部分介绍了一个HFile从无到有的生成过程,最后部分列出了几点与HFile有关的附加信息。
HFile原理概述
最初的HFile格式(HFile V1),参考了Bigtable的SSTable以及Hadoop的TFile(HADOOP-3315)。如下图所示:
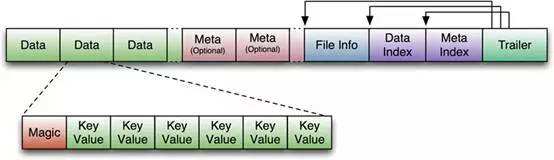
HFile在生成之前,数据在内存中已经是按序组织的。存放用户数据的KeyValue,被存储在一个个默认为64kb大小的Data Block中,在Data Index部分存储了每一个Data Block的索引信息{Offset,Size,FirstKey},而Data Index的索引信息{Data Index Offset, Data Block Count}被存储在HFile的Trailer部分。除此以外,在Meta Block部分还存储了Bloom Filter的数据。下图更直观的表达出了HFile V1中的数据组织结构:
这种设计简单、直观。但用过0.90或更老版本的同学,对于这个HFile版本所存在的问题应该深有痛楚:Region Open的时候,需要加载所有的Data Block Index数据,另外,第一次读取时需要加载所有的Bloom Filter数据到内存中。一个HFile中的Bloom Filter的数据大小可达百MB级别,一个RegionServer启动时可能需要加载数GB的Data Block Index数据。这在一个大数据量的集群中,几乎无法忍受。
Data Block Index究竟有多大?
一个Data Block在Data Block Index中的索引信息包含{Offset, Size, FirstKey},BlockOffset使用Long型数字表示,Size使用Int表示即可。假设用户数据RowKey的长度为50bytes,那么,一个64KB的Data Block在Data Block Index中的一条索引数据大小约为62字节。
假设一个RegionServer中有500个Region,每一个Region的数量为10GB(假设这是Data Blocks的总大小),在这个RegionServer上,约有81920000个Data Blocks,此时,Data Block Index所占用的大小为81920000*62bytes,约为4.7GB。
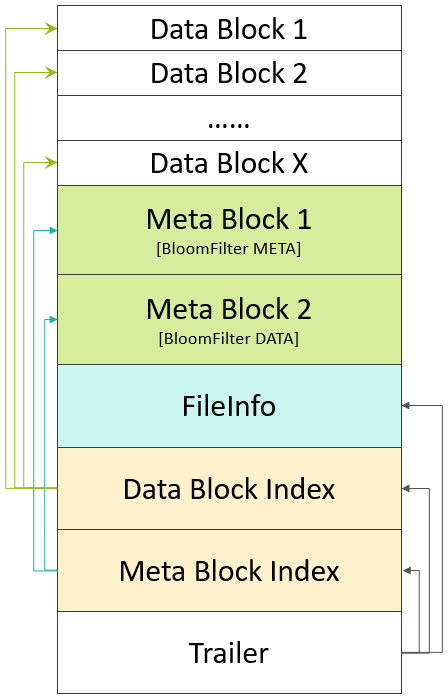
这是HFile V2设计的初衷,HFile V2期望显著降低RegionServer启动时加载HFile的时延,更希望解决一次全量加载数百MB级别的BloomFilter数据带来的时延过大的问题。下图是HFile V2的数据组织结构:
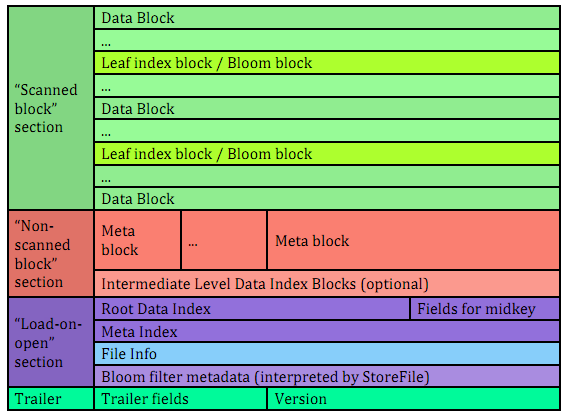
较之HFile V1,我们来看看HFile V2的几点显著变化:
1.分层索引
无论是Data Block Index还是Bloom Filter,都采用了分层索引的设计。
Data Block的索引,在HFile V2中做多可支持三层索引:最底层的Data Block Index称之为Leaf Index Block,可直接索引到Data Block;中间层称之为Intermediate Index Block,最上层称之为Root Data Index,Root Data index存放在一个称之为”Load-on-open Section“区域,Region Open时会被加载到内存中。基本的索引逻辑为:由Root Data Index索引到Intermediate Block Index,再由Intermediate Block Index索引到Leaf Index Block,最后由Leaf Index Block查找到对应的Data Block。在实际场景中,Intermediate Block Index基本上不会存在,文末部分会通过详细的计算阐述它基本不存在的原因,因此,索引逻辑被简化为:由Root Data Index直接索引到Leaf Index Block,再由Leaf Index Block查找到的对应的Data Block。
Bloom Filter也被拆成了多个Bloom Block,在”Load-on-open Section”区域中,同样存放了所有Bloom Block的索引数据。
2.交叉存放
在”Scanned Block Section“区域,Data Block(存放用户数据KeyValue)、存放Data Block索引的Leaf Index Block(存放Data Block的索引)与Bloom Block(Bloom Filter数据)交叉存在。
3.按需读取
无论是Data Block的索引数据,还是Bloom Filter数据,都被拆成了多个Block,基于这样的设计,无论是索引数据,还是Bloom Filter,都可以按需读取,避免在Region Open阶段或读取阶段一次读入大量的数据,有效降低时延。
从0.98版本开始,社区引入了HFile V3版本,主要是为了支持Tag特性,在HFile V2基础上只做了微量改动。在下文内容中,主要围绕HFile V2的设计展开。
HFile生成流程
在本章节,我们以Flush流程为例,介绍如何一步步生成HFile的流程,来加深大家对于HFile原理的理解。
起初,HFile中并没有任何Block,数据还存在于MemStore中。
Flush发生时,创建HFile Writer,第一个空的Data Block出现,初始化后的Data Block中为Header部分预留了空间,Header部分用来存放一个Data Block的元数据信息。
而后,位于MemStore中的KeyValues被一个个append到位于内存中的第一个Data Block中:
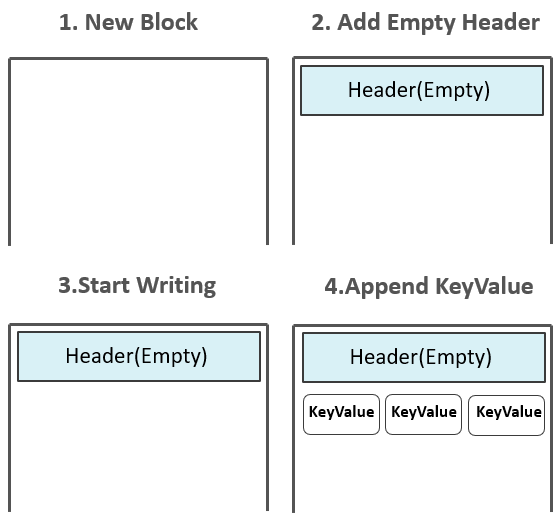
注:如果配置了Data Block Encoding,则会在Append KeyValue的时候进行同步编码,编码后的数据不再是单纯的KeyValue模式。Data Block Encoding是HBase为了降低KeyValue结构性膨胀而提供的内部编码机制。上图中所体现出来的KeyValue,只是为了方便大家理解。当Data Block增长到预设大小(默认64KB)后,一个Data Block被停止写入,该Data Block将经历如下一系列处理流程:1.如果有配置启用压缩或加密特性,对Data Block的数据按相应的算法进行压缩和加密。
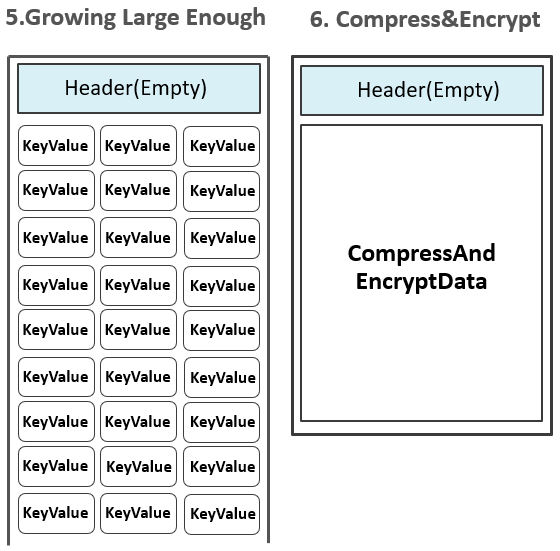
2.在预留的Header区,写入该Data Block的元数据信息,包含{压缩前的大小,压缩后的大小,上一个Block的偏移信息,Checksum元数据信息}等信息,下图是一个Header的完整结构:
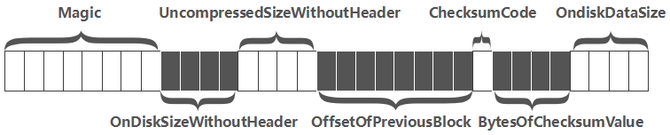
3.生成Checksum信息。
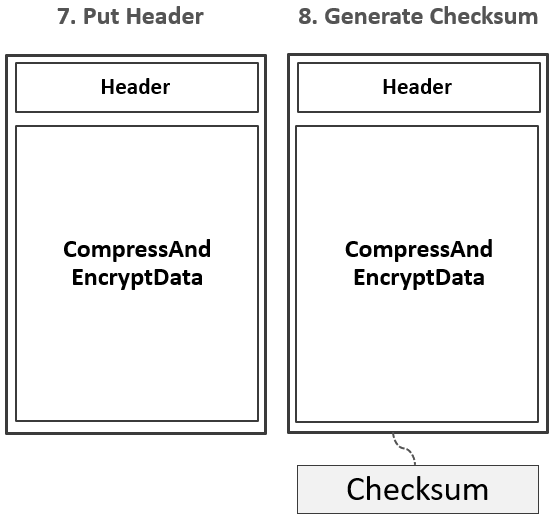
4.Data Block以及Checksum信息通过HFile Writer中的输出流写入到HDFS中。
5.为输出的Data Block生成一条索引记录,包含这个Data Block的{起始Key,偏移,大小}信息,这条索引记录被暂时记录到内存的Block Index Chunk中:
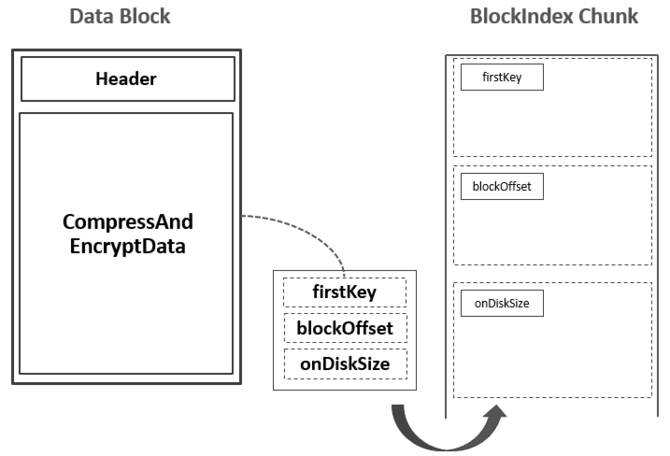
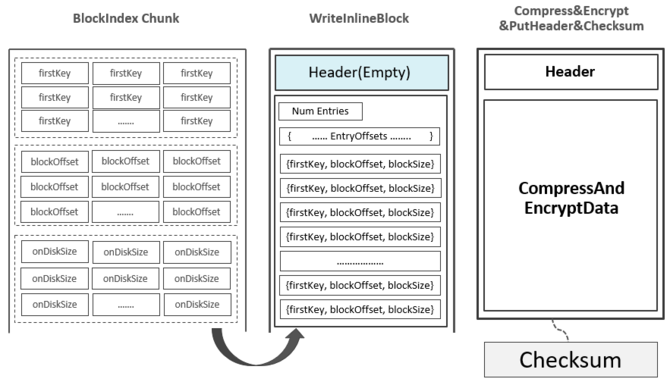
注:上图中的firstKey并不一定是这个Data Block的第一个Key,有可能是上一个Data Block的最后一个Key与这一个Data Block的第一个Key之间的一个中间值。具体可参考附录部分的信息。至此,已经写入了第一个Data Block,并且在Block Index Chunk中记录了关于这个Data Block的一条索引记录。随着Data Blocks数量的不断增多,Block Index Chunk中的记录数量也在不断变多。当Block Index Chunk达到一定大小以后(默认为128KB),Block Index Chunk也经与Data Block的类似处理流程后输出到HDFS中,形成第一个Leaf Index Block:
此时,已输出的Scanned Block Section部分的构成如下:
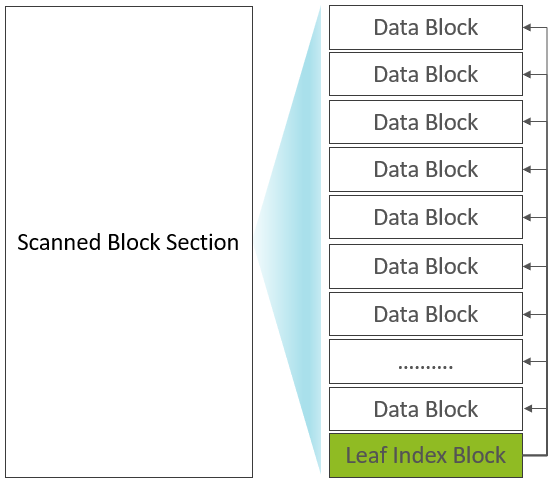
正是因为Leaf Index Block与Data Block在Scanned Block Section交叉存在,Leaf Index Block被称之为Inline Block(Bloom Block也属于Inline Block)。在内存中还有一个Root Block Index Chunk用来记录每一个Leaf Index Block的索引信息:
从Root Index到Leaf Data Block再到Data Block的索引关系如下:
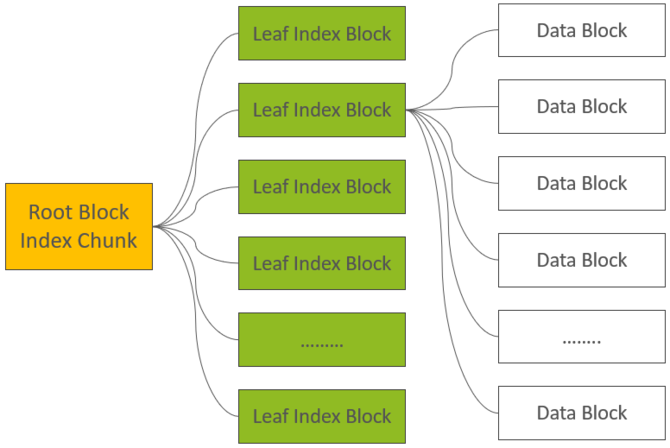
我们先假设没有Bloom Filter数据。当MemStore中所有的KeyValues全部写完以后,HFile Writer开始在close方法中处理最后的”收尾”工作:
1.写入最后一个Data Block。
2.写入最后一个Leaf Index Block。
如上属于Scanned Block Section部分的”收尾”工作。
3.如果有MetaData则写入位于Non-Scanned Block Section区域的Meta Blocks,事实上这部分为空。
4.写Root Block Index Chunk部分数据:
如果Root Block Index Chunk超出了预设大小,则输出位于Non-Scanned Block Section区域的Intermediate Index Block数据,以及生成并输出Root Index Block(记录Intermediate Index Block索引)到Load-On-Open Section部分。
如果未超出大小,则直接输出为Load-On-Open Section部分的Root Index Block。
5.写入用来索引Meta Blocks的Meta Index数据(事实上这部分只是写入一个空的Block)。
6.写入FileInfo信息,FileInfo中包含:
Max SequenceID, MajorCompaction标记,TimeRanage信息,最早的Timestamp, Data BlockEncoding类型,BloomFilter配置,最大的Timestamp,KeyValue版本,最后一个RowKey,平均的Key长度,平均Value长度,Key比较器等。
7.写入Bloom Filter元数据与索引数据。
注:前面每一部分信息的写入,都以Block形式写入,都包含Header与Data两部分,Header中的结构也是相同的,只是都有不同的Block Type,在Data部分,每一种类型的Block可以有自己的定义。
8.写入Trailer部分信息, Trailer中包含:
Root Index Block的Offset,FileInfo部分Offset,Data Block Index的层级,Data Block Index数据总大小,第一个Data Block的Offset,最后一个Data Block的Offset,Comparator信息,Root Index Block的Entries数量,加密算法类型,Meta Index Block的Entries数量,整个HFile文件未压缩大小,整个HFile中所包含的KeyValue总个数,压缩算法类型等。
至此,一个完整的HFile已生成。我们可以通过下图再简单回顾一下Root Index Block、Leaf Index Block、Data Block所处的位置以及索引关系:
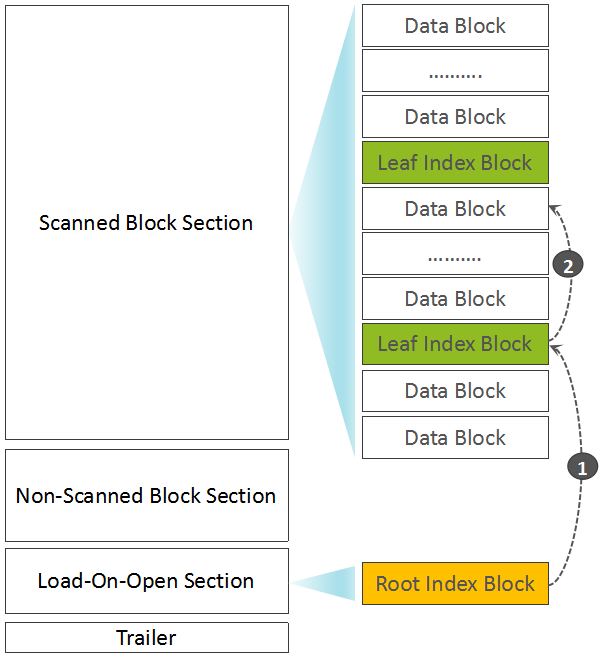
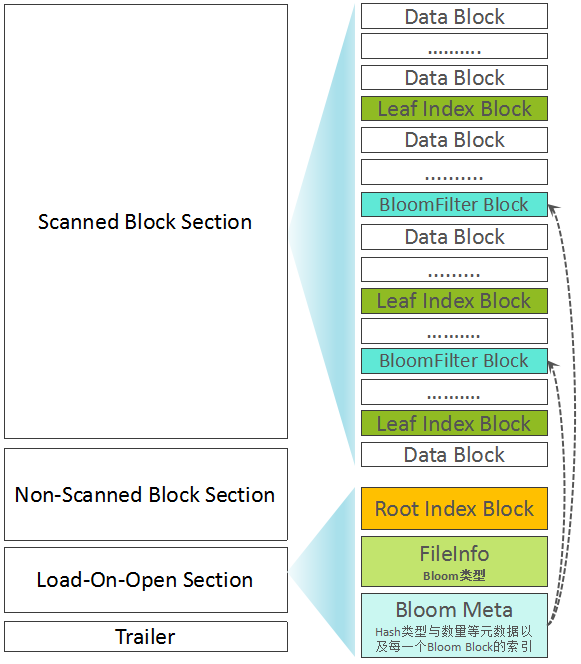
简单起见,上文中刻意忽略了Bloom Filter部分。Bloom Filter被用来快速判断一条记录是否在一个大的集合中存在,采用了多个Hash函数+位图的设计。写入数据时,一个记录经X个Hash函数运算后,被映射到位图中的X个位置,将位图中的这X个位置写为1。判断一条记录是否存在时,也是通过这个X个Hash函数计算后,获得X个位置,如果位图中的这X个位置都为1,则表明该记录”可能存在”,但如果至少有一个为0,则该记录”一定不存在”。
详细信息,大家可以直接参考Wiki,这里不做过多展开。Bloom Filter包含Bloom元数据(Hash函数类型,Hash函数个数等)与位图数据(BloomData),为了避免每一次读取时加载所有的Bloom Data,HFile V2中将BloomData部分分成了多个小的Bloom Block。BloomData数据也被当成一类Inline Block,与Data Block、Leaf Index Block交叉存在,而关于Bloom Filter的元数据与多个Bloom Block的索引信息,被存放在Load-On-Open Section部分。但需要注意的是,在FileInfo部分,保存了关于BloomFilter配置类型信息,共包含三种类型:不启用,基于Row构建BloomFilter,基于Row+Column构建Bloom Filter。混合了BloomFilter Block以后的HFile构成如下图所示:
附录1 多大的HFile文件才存在Intermiate Index Block
每一个Leaf Index Block大小的计算方法如下(HFileBlockIndex$BlockIndexChunk#getNonRootSize):
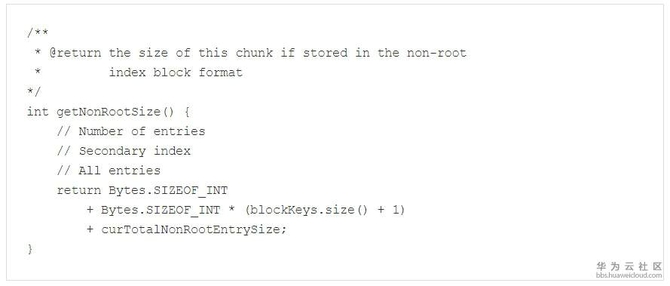
curTotalNonRootEntrySize是在每次写入一个新的Entry的时候累加的:

这样子,可以看出来,每一次新增一个Entry,则累计的值为:
- 12 + firstKey.length
假设一个Leaf Index Block可以容纳的Data Block的数量为x:
- 4 + 4 * (x + 1) + x * (12 + firstKey.length)
进一步假设,firstKey.length为50bytes。而一个Leaf Index Block的默认最大大小为128KB:
- 4 + 4 * (x + 1) + x * (12 + 50) = 128 * 1024
- x ≈1986
也就是说,在假设firstKey.length为50Bytes时,一个128KB的Leaf Index Block所能容纳的Data Block数量约为1986个。
我们再来看看Root Index Chunk大小的计算方法:

基于firstKey为50 Bytes的假设,每往Root Index Chunk中新增一个Entry(关联一个Leaf Index Block),那么,curTotalRootSize的累加值为:
- 12 + 1 + 50 = 63
因此,一个128KB的Root Index Chunk可以至少存储2080个Entries,即可存储2080个Leaf Index Block。
这样, 一个Root Index Chunk所关联的Data Blocks的总量应该为:
- 1986 * 2080 = 4,130,880
而每一个Data Block默认大小为64KB,那么,这个HFile的总大小至少为:
- 4,130,880 * 64 * 1024 ≈ 252 GB
即,基于每一个Block中的FirstKey为50bytes的假设,一个128KB的Root Index Block可容纳的HFile文件总大小约为252GB。
如果实际的RowKey小于50 Bytes,或者将Data Block的Size调大,一个128KB的Root Index Chunk所关联的HFile文件将会更大。因此,在大多数场景中,Intermediate Index Block并不会存在。
附录2 关于HFile数据查看工具
HBase中提供了一个名为HFilePrettyPrinter的工具,可以以一种直观的方式查看HFile中的数据,关于该工具的帮助信息,可通过如下命令查看:
- hbase org.apache.hadoop.hbase.io.hfile.HFile
- References
- HBase Architecture 101 – Storage
- HBASE-3857: Change the HFile Format
- HBase Document: Appendix H: HFile format
- HADOOP-3315: New Binary file format
SSTable and Log Structured Storage: LevelDB