Hi,大家好,我是承香墨影!
HTTP 协议在网络知识中占据了重要的地位,HTTP 协议最基础的就是请求和响应的报文,而报文又是由报文头(Header)和实体组成。大多数 HTTP 协议的使用方式,都是依赖设置不同的 HTTP 请求/响应 的 Header 来实现的。
本系列《实用 HTTP》就抛开常规的 Header 讲解式的表述方式,从实际问题出发,来分析这些 HTTP 协议的使用方式,到底是为了解决什么问题?同时讲解它是如何设计的和它实现原理。
HTTP 协议是一种无状态的“松散协议”,它不会记录不同请求的状态,并且因为它本身包含了两端(客户端和服务端),根据请求和响应来区分,它大部分的内容都只是一个建议,其实双边是可以不遵守此建议的。
前两篇文章中,我们分别聊了 HTTP 的缓存机制 和 HTTP 内容实体编码压缩机制 ,在说到实体编码压缩的时候,还提到了一个传输编码,让我们优化传输的方式。实体编码和传输编码二者是相辅相成的,一般我们会配合使用。
本文就来聊聊 HTTP 的传输编码机制。
二、HTTP 的传输编码
2.1 什么是传输编码?
传输编码在 HTTP 的报文头中,使用 Transfer-Encoding 首部进行标记,它就是指明当前使用的传输编码。
Transfer-Encoding 会改变报文的格式和传输的方式,使用它不但不会减少内容传输的大小,甚至还有可能会使传输变大,看似是一个不环保的做法,但是其实是为了解决一些特殊问题。
简单来说,传输编码必须配合持久连接去使用,为了在一个持久连接中,将数据分块传输,并标记传输结束而设计的,后面会详细讲解。
在早年间的设计里,和内容编码使用 Accept-Encoding 来标记客户端接收的压缩编码类型一样,传输编码还需要配合 TE 这个请求报文头来使用,用于指定支持的传输编码。但是在最新的 HTTP/1.1 协议规范中,只定义了一种传输编码:分块编码(chunked),所以并不需要再依赖 TE 这个头部。
这些细节,后面都会讲到。既然传输编码和持久连接是息息相关的,那我们就先来了解一下什么是持久连接。
2.2 持久连接(Persistent Connection)
持久连接通俗来讲,就是长连接,英文叫 Persistent Connection,其实按字面意思理解就好了。
在早期的 HTTP 协议中,传输数据的顺序大致分为发起请求、建立连接、传输数据、关闭连接等步骤,而持久连接,就是去掉关闭连接这个步骤,让客户端和服务端可以继续通过此次连接传输内容。
这其实也是为了提高传输效率,我们知道 HTTP 协议是建立在 TCP 协议之上的,自然有 TCP 一样的三次握手、慢启动等特性,这样每一次连接其实都是一次宝贵的资源。为了尽可能的提高 HTTP 的性能,使用持久连接就显得很重要了。为此在 HTTP 协议中,就引入了相关的机制。
在早期的 HTTP/1.0 协议中并没有持久连接,持久连接的概念是在后期才引入的,当时是通过 Connection:Keep-Alive 这个头部来标记实现,用于通知客户端或服务端相对的另一端,在发送完数据之后,不要断开 TCP 连接,之后还需要再次使用。
而在 HTTP/1.1 协议中,发现持久连接的重要性了,它规定所有的连接必须都是持久的,除非显式的在报文头里,通过 Connection:close 这个首部,指定在传输结束之后会关闭此连接。
实际上在 HTTP/1.1 中Connect 这个头部已经没有 Keep-Alive 这个取值了,由于历史原因,很多客户端和服务端,依然保留了这个报文头。
长连接带来了另外一个问题,如何判定当前数据发送完成。
2.3 判断传输完成
在早期不支持持久连接的时候,其实是可以依靠连接断开来判定当前传输已经结束,大部分浏览器也是这么干的,但这并不是规范的操作。应该使用 Content-Length 这个头部,来指定当前传输的实体内容长度。
下面举个例子,在保持持久连接的情况下,依赖 Content-Length 来确定数据发送完毕。
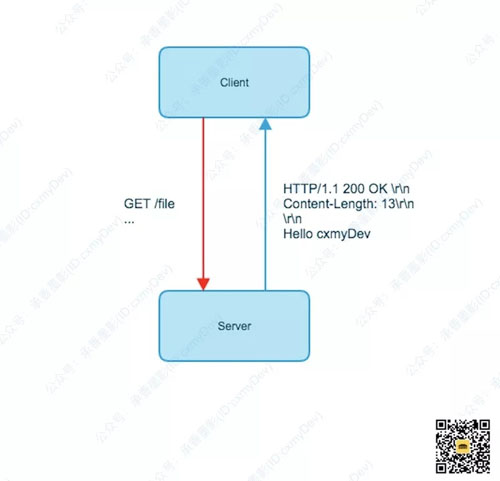
Content-Length 在这里起到了一个响应实体已经发送结束的判断依据。这样的情况下,我们就要求 Content-Length 必须和内容实体的长度一致,如果不一致,就会出现各种问题。
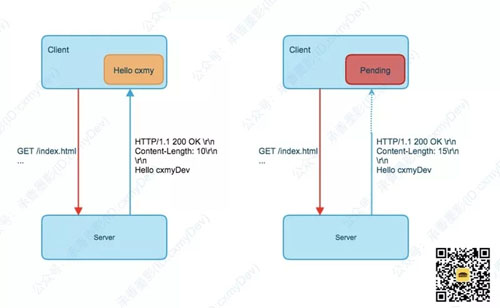
如上图所示,如果 Content-Length 小于内容实体的长度,则会截断,反之则无法判定当前响应已经结束,会将请求持续挂起造成 Padding 状态。
理想情况下,我们在响应一个请求的时候,就需要知道它的内容实体的大小。但是在实际应用中,有些时候内容实体的长度并没有那么容易获得。例如内容实体来自网络文件、或者是动态生成的。这个时候如果依然想要提前获取到内容实体的长度,只能开一个足够大的 Buffer,等内容全部缓存好了再计算。
但这并不是一个好的方案,全部缓存到 Buffer 里,第一会消耗更多的内存,第二也会更耗时,让客户端等待过久。
此时就需要一个新的机制,不依赖 Content-Length 的值,来判定当前内容实体是否传输完成,此时就需要 Transfer-Encoding 这个头部来判定。
2.4 Transfer-Encoding:chunked
前面也提到,Transfer-Encoding 在最新的 HTTP/1.1 协议里,就只有 chunked 这个参数,标识当前为分块编码传输。
分块编码传输既然只有一个可选的参数,我们就只需要指定它为 Transfer-Encoding:chunked ,后续我们就可以将内容实体包装一个个块进行传输。
分块传输的规则:
1. 每个分块包含一个 16 进制的数据长度值和真实数据。
2. 数据长度值独占一行,和真实数据通过 CRLF(\r\n) 分割。
3. 数据长度值,不计算真实数据末尾的 CRLF,只计算当前传输块的数据长度。
4. 最后通过一个数据长度值为 0 的分块,来标记当前内容实体传输结束。
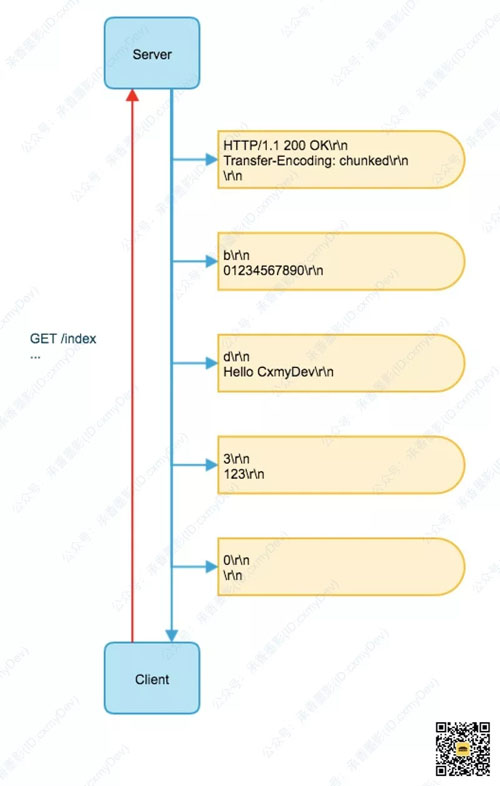
在这个例子中,首先在响应头部里标记了 Transfer-Encoding: chunked,后续先传递了第一个分块 “0123456780”,长度为 b(11 的十六进制),之后分别传输了 “Hello CxmyDev” 和 “123”,最后以一个长度为 0 的分块标记当前响应结束。
2.5 chunked 的拖挂
当我们使用 chunked 进行分块编码传输的时候,传输结束之后,还有机会在分块报文的末尾,再追加一段数据,此数据称为拖挂(Trailer)。
拖挂的数据,可以是服务端在末尾需要传递的数据,客户端其实是可以忽略并丢弃拖挂的内容的,这就需要双方协商好传输的内容了。
在拖挂中可以包含附带的首部字段,除了 Transfer-Encoding、Trailer 以及 Content-Length 首部之外,其他 HTTP 首部都可以作为拖挂发送。
一般我们会使用拖挂来传递一些在响应报文开始的时候,无法确定的某些值,例如:Content-MD5 首部就是一个常见的在拖挂中追加发送的首部。和长度一样,对于需要分块编码传输的内容实体,在开始响应的时候,我们也很难算出它的 MD5 值。
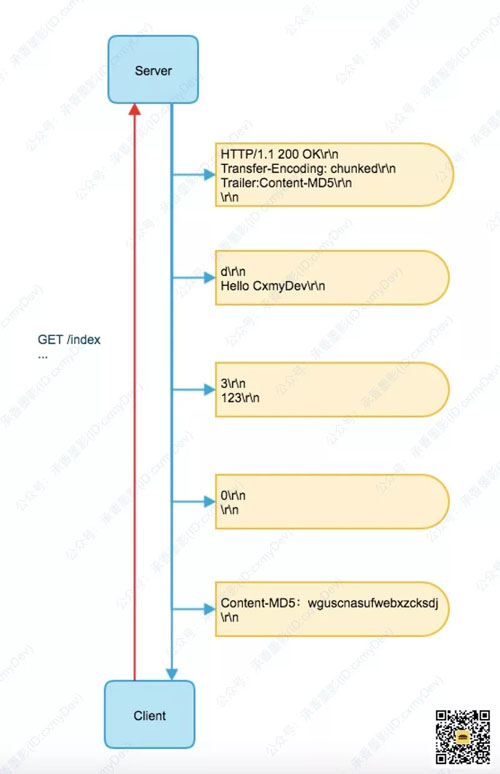
注意这里在头部增加了 Trailder,用以指定末尾还会传递一个 Content-MD5 的拖挂首部,如果有多个拖挂的数据,可以使用逗号进行分割。
三、内容编码和传输编码结合
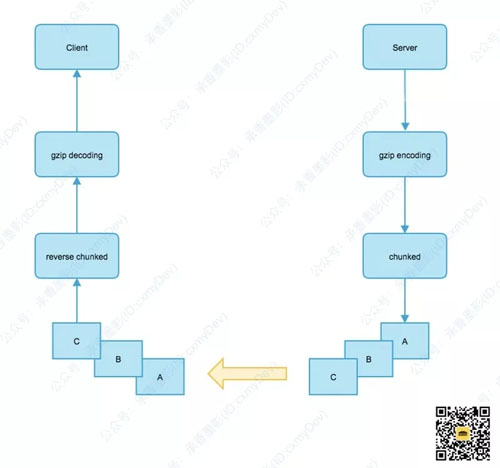
内容编码和传输编码一般都是配合使用的。我们会先使用内容编码,将内容实体进行压缩,然后再通过传输编码分块发送出去。客户端接收到分块的数据,再将数据进行重新整合,还原成最初的数据。
四、传输编码小结
我们对传输编码应该有一定的了解了。这里简单总结一下:
1. 传输编码使用 Transfer-Encoding 首部进行标记,在最新的 HTTP/1.1 协议里,它只有 chunked 这一个取值,表示分块编码。
2. 传输编码主要是为了解决持久连接里将数据分块传输之后,判定内容实体传输结束。
3. 分块的格式:数据长度(16进制)+ 分块数据。
4. 如果还有额外的数据,可以在结束之后,使用 Trailer 进行拖挂传输额外的数据。
5. 传输编码通常会配合内容编码一起使用。
此外,传输编码应该是所有 HTTP/1.1 的标准实现,应该都有支持,如果收到无法理解的经过传输编码的报文,应该直接返回 501 Unimplemented 这个状态码来回复即可。
参考连接:
HTTP 协议中的 Transfer-Encoding:https://imququ.com/post/transfer-encoding-header-in-http.html
REC 7230, 3.3.1 Transfer-Encoding:https://tools.ietf.org/html/rfc7230#page-28
RFC 7230, section 4.4: Trailer:https://tools.ietf.org/html/rfc7230#section-4.4
RFC 7230, section 4.1.2: Chunked trailer part:https://tools.ietf.org/html/rfc7230#section-4.1.2

【本文为51CTO专栏作者“张旸”的原创稿件,转载请通过微信公众号联系作者获取授权】